 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioBench: A Universal Benchmark for Audio Large Language Models
Paper and Code
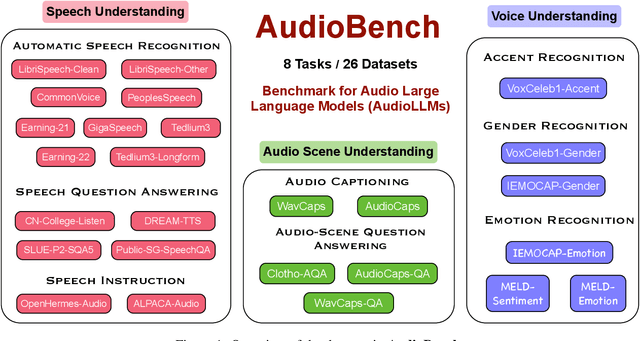
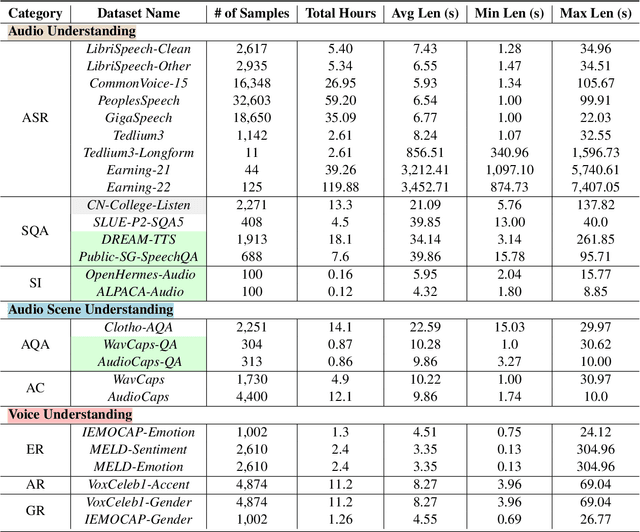
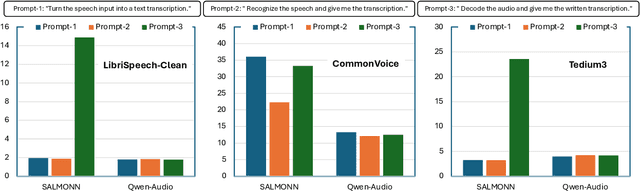
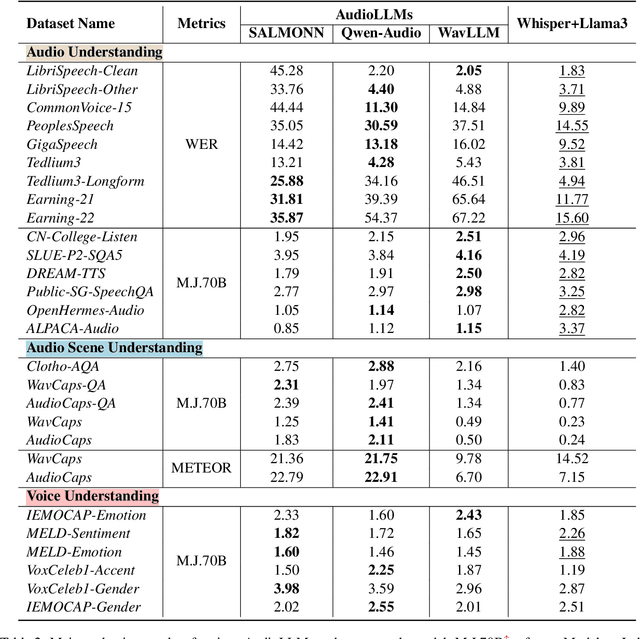
We introduce AudioBench, a new benchmark designed to evaluate audio large language models (AudioLLMs). AudioBench encompasses 8 distinct tasks and 26 carefully selected or newly curated datasets, focusing on speech understanding, voice interpretation, and audio scene understanding. Despite the rapid advancement of large language models, including multimodal versions, a significant gap exists in comprehensive benchmarks for thoroughly evaluating their capabilities. AudioBench addresses this gap by providing relevant datasets and evaluation metrics. In our study, we evaluated the capabilities of four models across various aspects and found that no single model excels consistently across all tasks. We outline the research outlook for AudioLLMs and anticipate that our open-source code, data, and leaderboard will offer a robust testbed for future model developments.