 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Classification: Towards Speech Emotion Reasoning with Multitask AudioLLMs
Jun 07, 2025Audio Large Language Models (AudioLLMs) have achieved strong results in semantic tasks like speech recognition and translation, but remain limited in modeling paralinguistic cues such as emotion. Existing approaches often treat emotion understanding as a classification problem, offering little insight into the underlying rationale behind predictions. In this work, we explore emotion reasoning, a strategy that leverages the generative capabilities of AudioLLMs to enhance emotion recognition by producing semantically aligned, evidence-grounded explanations. To support this in multitask AudioLLMs, we introduce a unified framework combining reasoning-augmented data supervision, dual-encoder architecture, and task-alternating training. This approach enables AudioLLMs to effectively learn different tasks while incorporating emotional reasoning. Experiments on IEMOCAP and MELD show that our approach not only improves emotion prediction accuracy but also enhances the coherence and evidential grounding of the generated responses.
Advancing Singlish Understanding: Bridging the Gap with Datasets and Multimodal Models
Jan 02, 2025



Singlish, a Creole language rooted in English, is a key focus in linguistic research within multilingual and multicultural contexts. However, its spoken form remains underexplored, limiting insights into its linguistic structure and applications. To address this gap, we standardize and annotate the largest spoken Singlish corpus, introducing the Multitask National Speech Corpus (MNSC). These datasets support diverse tasks, including Automatic Speech Recognition (ASR), Spoken Question Answering (SQA), Spoken Dialogue Summarization (SDS), and Paralinguistic Question Answering (PQA). We release standardized splits and a human-verified test set to facilitate further research. Additionally, we propose SingAudioLLM, a multi-task multimodal model leveraging multimodal large language models to handle these tasks concurrently. Experiments reveal our models adaptability to Singlish context, achieving state-of-the-art performance and outperforming prior models by 10-30% in comparison with other AudioLLMs and cascaded solutions.
MERaLiON-AudioLLM: Bridging Audio and Language with Large Language Models
Dec 18, 2024

We introduce MERaLiON-AudioLLM (Multimodal Empathetic Reasoning and Learning in One Network), the first speech-text model tailored for Singapore's multilingual and multicultural landscape. Developed under the National Large Language Models Funding Initiative, Singapore, MERaLiON-AudioLLM integrates advanced speech and text processing to address the diverse linguistic nuances of local accents and dialects, enhancing accessibility and usability in complex, multilingual environments. Our results demonstrate improvements in both speech recognition and task-specific understanding, positioning MERaLiON-AudioLLM as a pioneering solution for region specific AI applications. We envision this release to set a precedent for future models designed to address localised linguistic and cultural contexts in a global framework.
MERaLiON-AudioLLM: Technical Report
Dec 13, 2024We introduce MERaLiON-AudioLLM (Multimodal Empathetic Reasoning and Learning in One Network), the first speech-text model tailored for Singapore's multilingual and multicultural landscape. Developed under the National Large Language Models Funding Initiative, Singapore, MERaLiON-AudioLLM integrates advanced speech and text processing to address the diverse linguistic nuances of local accents and dialects, enhancing accessibility and usability in complex, multilingual environments. Our results demonstrate improvements in both speech recognition and task-specific understanding, positioning MERaLiON-AudioLLM as a pioneering solution for region specific AI applications. We envision this release to set a precedent for future models designed to address localised linguistic and cultural contexts in a global framework.
MoWE-Audio: Multitask AudioLLMs with Mixture of Weak Encoders
Sep 10, 2024



The rapid advancements in large language models (LLMs) have significantly enhanced natural language processing capabilities, facilitating the development of AudioLLMs that process and understand speech and audio inputs alongside text. Existing AudioLLMs typically combine a pre-trained audio encoder with a pre-trained LLM, which are subsequently finetuned on specific audio tasks. However, the pre-trained audio encoder has constrained capacity to capture features for new tasks and datasets. To address this, we propose to incorporate mixtures of `weak' encoders (MoWE) into the AudioLLM framework. MoWE supplements a base encoder with a pool of relatively light weight encoders, selectively activated based on the audio input to enhance feature extraction without significantly increasing model size. Our empirical results demonstrate that MoWE effectively improves multi-task performance, broadening the applicability of AudioLLMs to more diverse audio tasks.
AudioBench: A Universal Benchmark for Audio Large Language Models
Jun 25, 2024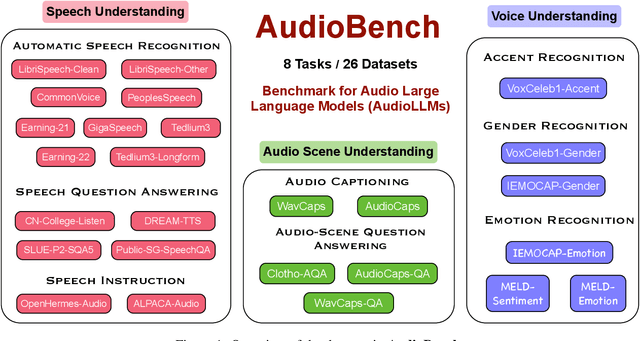
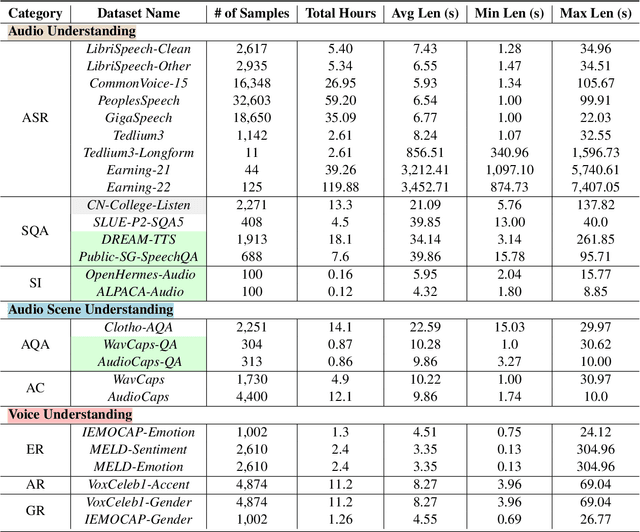
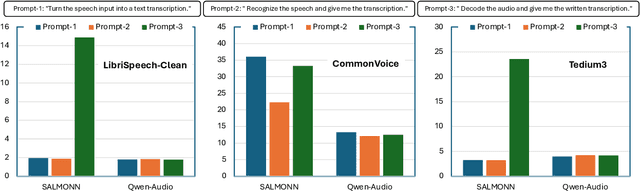
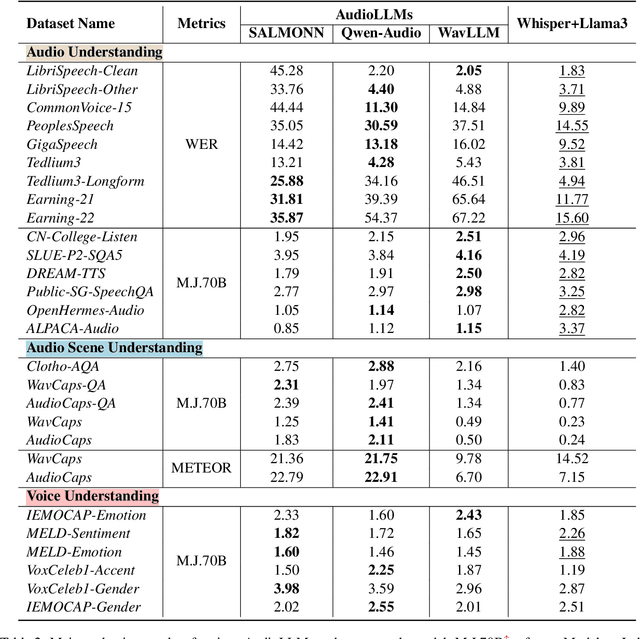
We introduce AudioBench, a new benchmark designed to evaluate audio large language models (AudioLLMs). AudioBench encompasses 8 distinct tasks and 26 carefully selected or newly curated datasets, focusing on speech understanding, voice interpretation, and audio scene understanding. Despite the rapid advancement of large language models, including multimodal versions, a significant gap exists in comprehensive benchmarks for thoroughly evaluating their capabilities. AudioBench addresses this gap by providing relevant datasets and evaluation metrics. In our study, we evaluated the capabilities of four models across various aspects and found that no single model excels consistently across all tasks. We outline the research outlook for AudioLLMs and anticipate that our open-source code, data, and leaderboard will offer a robust testbed for future model developments.