 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Contextual Paralinguistic Understanding in Large Speech-Language Models
Aug 10, 2025Current large speech language models (Speech-LLMs) often exhibit limitations in empathetic reasoning, primarily due to the absence of training datasets that integrate both contextual content and paralinguistic cues. In this work, we propose two approaches to incorporate contextual paralinguistic information into model training: (1) an explicit method that provides paralinguistic metadata (e.g., emotion annotations) directly to the LLM, and (2) an implicit method that automatically generates novel training question-answer (QA) pairs using both categorical and dimensional emotion annotations alongside speech transcriptions. Our implicit method boosts performance (LLM-judged) by 38.41% on a human-annotated QA benchmark, reaching 46.02% when combined with the explicit approach, showing effectiveness in contextual paralinguistic understanding. We also validate the LLM judge by demonstrating its correlation with classification metrics, providing support for its reliability.
Beyond Classification: Towards Speech Emotion Reasoning with Multitask AudioLLMs
Jun 07, 2025Audio Large Language Models (AudioLLMs) have achieved strong results in semantic tasks like speech recognition and translation, but remain limited in modeling paralinguistic cues such as emotion. Existing approaches often treat emotion understanding as a classification problem, offering little insight into the underlying rationale behind predictions. In this work, we explore emotion reasoning, a strategy that leverages the generative capabilities of AudioLLMs to enhance emotion recognition by producing semantically aligned, evidence-grounded explanations. To support this in multitask AudioLLMs, we introduce a unified framework combining reasoning-augmented data supervision, dual-encoder architecture, and task-alternating training. This approach enables AudioLLMs to effectively learn different tasks while incorporating emotional reasoning. Experiments on IEMOCAP and MELD show that our approach not only improves emotion prediction accuracy but also enhances the coherence and evidential grounding of the generated responses.
Improving Multilingual Social Media Insights: Aspect-based Comment Analysis
May 29, 2025The inherent nature of social media posts, characterized by the freedom of language use with a disjointed array of diverse opinions and topics, poses significant challenges to downstream NLP tasks such as comment clustering, comment summarization, and social media opinion analysis. To address this, we propose a granular level of identifying and generating aspect terms from individual comments to guide model attention. Specifically, we leverage multilingual large language models with supervised fine-tuning for comment aspect term generation (CAT-G), further aligning the model's predictions with human expectations through DPO. We demonstrate the effectiveness of our method in enhancing the comprehension of social media discourse on two NLP tasks. Moreover, this paper contributes the first multilingual CAT-G test set on English, Chinese, Malay, and Bahasa Indonesian. As LLM capabilities vary among languages, this test set allows for a comparative analysis of performance across languages with varying levels of LLM proficiency.
Contextual Paralinguistic Data Creation for Multi-Modal Speech-LLM: Data Condensation and Spoken QA Generation
May 19, 2025Current speech-LLMs exhibit limited capability in contextual reasoning alongside paralinguistic understanding, primarily due to the lack of Question-Answer (QA) datasets that cover both aspects. We propose a novel framework for dataset generation from in-the-wild speech data, that integrates contextual reasoning with paralinguistic information. It consists of a pseudo paralinguistic label-based data condensation of in-the-wild speech and LLM-based Contextual Paralinguistic QA (CPQA) generation. The effectiveness is validated by a strong correlation in evaluations of the Qwen2-Audio-7B-Instruct model on a dataset created by our framework and human-generated CPQA dataset. The results also reveal the speech-LLM's limitations in handling empathetic reasoning tasks, highlighting the need for such datasets and more robust models. The proposed framework is first of its kind and has potential in training more robust speech-LLMs with paralinguistic reasoning capabilities.
AdaCoT: Rethinking Cross-Lingual Factual Reasoning through Adaptive Chain-of-Thought
Jan 27, 2025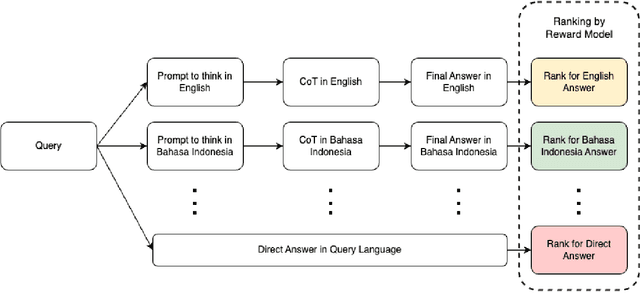
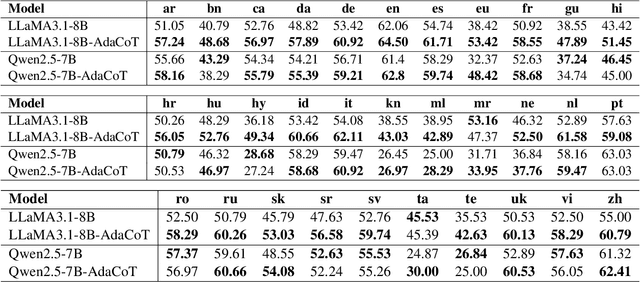

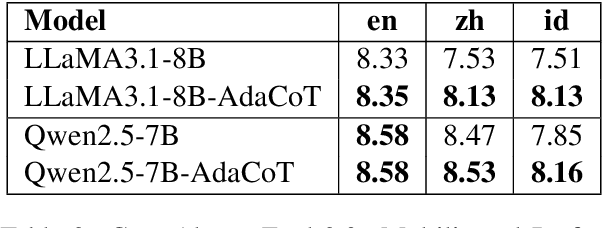
Large language models (LLMs) have shown impressive multilingual capabilities through pretraining on diverse corpora. While these models show strong reasoning abilities, their performance varies significantly across languages due to uneven training data distribution. Existing approaches using machine translation, and extensive multilingual pretraining and cross-lingual tuning face scalability challenges and often fail to capture nuanced reasoning processes across languages. In this paper, we introduce AdaCoT (Adaptive Chain-of-Thought), a framework that enhances multilingual reasoning by dynamically routing thought processes through intermediary "thinking languages" before generating target-language responses. AdaCoT leverages a language-agnostic core and incorporates an adaptive, reward-based mechanism for selecting optimal reasoning pathways without requiring additional pretraining. Our comprehensive evaluation across multiple benchmarks demonstrates substantial improvements in both factual reasoning quality and cross-lingual consistency, with particularly strong performance gains in low-resource language settings. The results suggest that adaptive reasoning paths can effectively bridge the performance gap between high and low-resource languages while maintaining cultural and linguistic nuances.
MERaLiON-SpeechEncoder: Towards a Speech Foundation Model for Singapore and Beyond
Dec 20, 2024



This technical report describes the MERaLiON-SpeechEncoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON-SpeechEncoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON-SpeechEncoder was pre-trained from scratch on 200,000 hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
MERaLiON-AudioLLM: Bridging Audio and Language with Large Language Models
Dec 18, 2024

We introduce MERaLiON-AudioLLM (Multimodal Empathetic Reasoning and Learning in One Network), the first speech-text model tailored for Singapore's multilingual and multicultural landscape. Developed under the National Large Language Models Funding Initiative, Singapore, MERaLiON-AudioLLM integrates advanced speech and text processing to address the diverse linguistic nuances of local accents and dialects, enhancing accessibility and usability in complex, multilingual environments. Our results demonstrate improvements in both speech recognition and task-specific understanding, positioning MERaLiON-AudioLLM as a pioneering solution for region specific AI applications. We envision this release to set a precedent for future models designed to address localised linguistic and cultural contexts in a global framework.
Towards a Speech Foundation Model for Singapore and Beyond
Dec 16, 2024This technical report describes the MERaLiON Speech Encoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON Speech Encoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON Speech Encoder was pre-trained from scratch on 200K hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
MERaLiON-AudioLLM: Technical Report
Dec 13, 2024We introduce MERaLiON-AudioLLM (Multimodal Empathetic Reasoning and Learning in One Network), the first speech-text model tailored for Singapore's multilingual and multicultural landscape. Developed under the National Large Language Models Funding Initiative, Singapore, MERaLiON-AudioLLM integrates advanced speech and text processing to address the diverse linguistic nuances of local accents and dialects, enhancing accessibility and usability in complex, multilingual environments. Our results demonstrate improvements in both speech recognition and task-specific understanding, positioning MERaLiON-AudioLLM as a pioneering solution for region specific AI applications. We envision this release to set a precedent for future models designed to address localised linguistic and cultural contexts in a global framework.
MoWE-Audio: Multitask AudioLLMs with Mixture of Weak Encoders
Sep 10, 2024



The rapid advancements in large language models (LLMs) have significantly enhanced natural language processing capabilities, facilitating the development of AudioLLMs that process and understand speech and audio inputs alongside text. Existing AudioLLMs typically combine a pre-trained audio encoder with a pre-trained LLM, which are subsequently finetuned on specific audio tasks. However, the pre-trained audio encoder has constrained capacity to capture features for new tasks and datasets. To address this, we propose to incorporate mixtures of `weak' encoders (MoWE) into the AudioLLM framework. MoWE supplements a base encoder with a pool of relatively light weight encoders, selectively activated based on the audio input to enhance feature extraction without significantly increasing model size. Our empirical results demonstrate that MoWE effectively improves multi-task performance, broadening the applicability of AudioLLMs to more diverse audio tasks.