 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoDensity: Rewarding Information-Dense Traces for Efficient Reasoning
Mar 18, 2026Large Language Models (LLMs) with extended reasoning capabilities often generate verbose and redundant reasoning traces, incurring unnecessary computational cost. While existing reinforcement learning approaches address this by optimizing final response length, they neglect the quality of intermediate reasoning steps, leaving models vulnerable to reward hacking. We argue that verbosity is not merely a length problem, but a symptom of poor intermediate reasoning quality. To investigate this, we conduct an empirical study tracking the conditional entropy of the answer distribution across reasoning steps. We find that high-quality reasoning traces exhibit two consistent properties: low uncertainty convergence and monotonic progress. These findings suggest that high-quality reasoning traces are informationally dense, that is, each step contributes meaningful entropy reduction relative to the total reasoning length. Motivated by this, we propose InfoDensity, a reward framework for RL training that combines an AUC-based reward and a monotonicity reward as a unified measure of reasoning quality, weighted by a length scaling term that favors achieving equivalent quality more concisely. Experiments on mathematical reasoning benchmarks demonstrate that InfoDensity matches or surpasses state-of-the-art baselines in accuracy while significantly reducing token usage, achieving a strong accuracy-efficiency trade-off.
Unlocking Cognitive Capabilities and Analyzing the Perception-Logic Trade-off
Feb 27, 2026Recent advancements in Multimodal Large Language Models (MLLMs) pursue omni-perception capabilities, yet integrating robust sensory grounding with complex reasoning remains a challenge, particularly for underrepresented regions. In this report, we introduce the research preview of MERaLiON2-Omni (Alpha), a 10B-parameter multilingual omni-perception tailored for Southeast Asia (SEA). We present a progressive training pipeline that explicitly decouples and then integrates "System 1" (Perception) and "System 2" (Reasoning) capabilities. First, we establish a robust Perception Backbone by aligning region-specific audio-visual cues (e.g., Singlish code-switching, local cultural landmarks) with a multilingual LLM through orthogonal modality adaptation. Second, to inject cognitive capabilities without large-scale supervision, we propose a cost-effective Generate-Judge-Refine pipeline. By utilizing a Super-LLM to filter hallucinations and resolve conflicts via a consensus mechanism, we synthesize high-quality silver data that transfers textual Chain-of-Thought reasoning to multimodal scenarios. Comprehensive evaluation on our newly introduced SEA-Omni Benchmark Suite reveals an Efficiency-Stability Paradox: while reasoning acts as a non-linear amplifier for abstract tasks (boosting mathematical and instruction-following performance significantly), it introduces instability in low-level sensory processing. Specifically, we identify Temporal Drift in long-context audio, where extended reasoning desynchronizes the model from acoustic timestamps, and Visual Over-interpretation, where logic overrides pixel-level reality. This report details the architecture, the data-efficient training recipe, and a diagnostic analysis of the trade-offs between robust perception and structured reasoning.
Toward Real-World Chinese Psychological Support Dialogues: CPsDD Dataset and a Co-Evolving Multi-Agent System
Jul 10, 2025
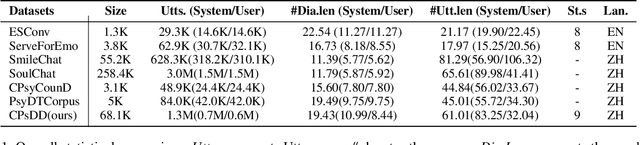
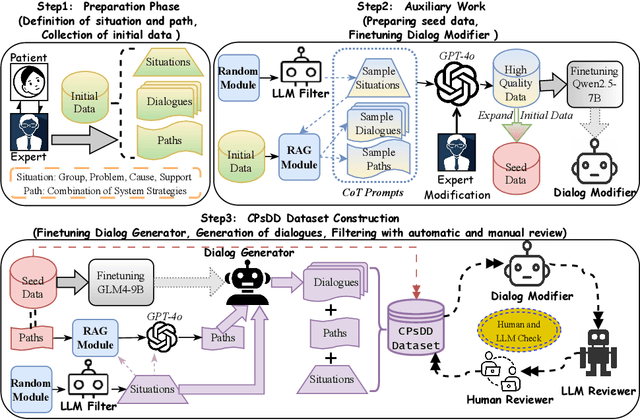
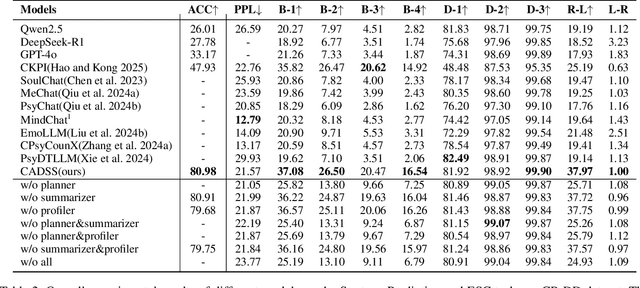
The growing need for psychological support due to increasing pressures has exposed the scarcity of relevant datasets, particularly in non-English languages. To address this, we propose a framework that leverages limited real-world data and expert knowledge to fine-tune two large language models: Dialog Generator and Dialog Modifier. The Generator creates large-scale psychological counseling dialogues based on predefined paths, which guide system response strategies and user interactions, forming the basis for effective support. The Modifier refines these dialogues to align with real-world data quality. Through both automated and manual review, we construct the Chinese Psychological support Dialogue Dataset (CPsDD), containing 68K dialogues across 13 groups, 16 psychological problems, 13 causes, and 12 support focuses. Additionally, we introduce the Comprehensive Agent Dialogue Support System (CADSS), where a Profiler analyzes user characteristics, a Summarizer condenses dialogue history, a Planner selects strategies, and a Supporter generates empathetic responses. The experimental results of the Strategy Prediction and Emotional Support Conversation (ESC) tasks demonstrate that CADSS achieves state-of-the-art performance on both CPsDD and ESConv datasets.
Improving Multilingual Social Media Insights: Aspect-based Comment Analysis
May 29, 2025The inherent nature of social media posts, characterized by the freedom of language use with a disjointed array of diverse opinions and topics, poses significant challenges to downstream NLP tasks such as comment clustering, comment summarization, and social media opinion analysis. To address this, we propose a granular level of identifying and generating aspect terms from individual comments to guide model attention. Specifically, we leverage multilingual large language models with supervised fine-tuning for comment aspect term generation (CAT-G), further aligning the model's predictions with human expectations through DPO. We demonstrate the effectiveness of our method in enhancing the comprehension of social media discourse on two NLP tasks. Moreover, this paper contributes the first multilingual CAT-G test set on English, Chinese, Malay, and Bahasa Indonesian. As LLM capabilities vary among languages, this test set allows for a comparative analysis of performance across languages with varying levels of LLM proficiency.
Multi-Hop Question Generation via Dual-Perspective Keyword Guidance
May 21, 2025Multi-hop question generation (MQG) aims to generate questions that require synthesizing multiple information snippets from documents to derive target answers. The primary challenge lies in effectively pinpointing crucial information snippets related to question-answer (QA) pairs, typically relying on keywords. However, existing works fail to fully utilize the guiding potential of keywords and neglect to differentiate the distinct roles of question-specific and document-specific keywords. To address this, we define dual-perspective keywords (i.e., question and document keywords) and propose a Dual-Perspective Keyword-Guided (DPKG) framework, which seamlessly integrates keywords into the multi-hop question generation process. We argue that question keywords capture the questioner's intent, whereas document keywords reflect the content related to the QA pair. Functionally, question and document keywords work together to pinpoint essential information snippets in the document, with question keywords required to appear in the generated question. The DPKG framework consists of an expanded transformer encoder and two answer-aware transformer decoders for keyword and question generation, respectively. Extensive experiments demonstrate the effectiveness of our work, showcasing its promising performance and underscoring its significant value in the MQG task.
Discourse Cohesion Evaluation for Document-Level Neural Machine Translation
Aug 19, 2022
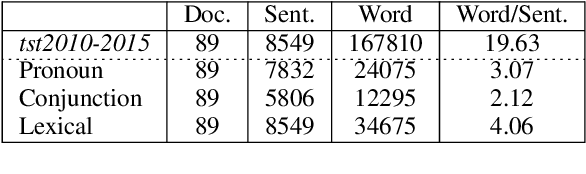
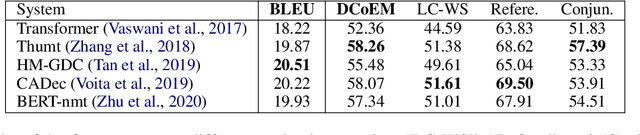
It is well known that translations generated by an excellent document-level neural machine translation (NMT) model are consistent and coherent. However, existing sentence-level evaluation metrics like BLEU can hardly reflect the model's performance at the document level. To tackle this issue, we propose a Discourse Cohesion Evaluation Method (DCoEM) in this paper and contribute a new test suite that considers four cohesive manners (reference, conjunction, substitution, and lexical cohesion) to measure the cohesiveness of document translations. The evaluation results on recent document-level NMT systems show that our method is practical and essential in estimating translations at the document level.
Are Eliminated Spans Useless for Coreference Resolution? Not at all
Jan 04, 2021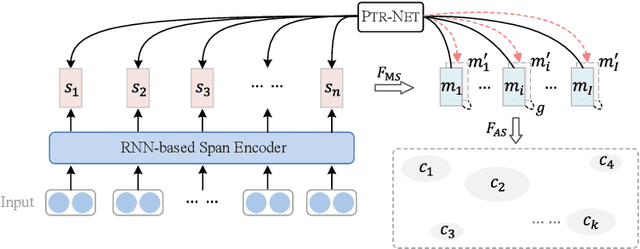
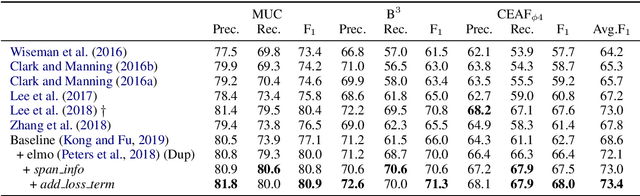
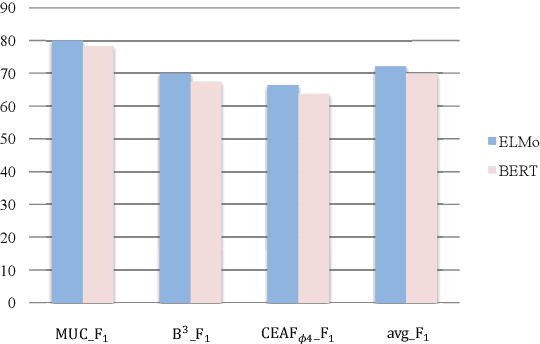
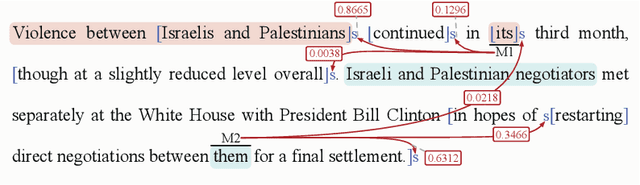
Various neural-based methods have been proposed so far for joint mention detection and coreference resolution. However, existing works on coreference resolution are mainly dependent on filtered mention representation, while other spans are largely neglected. In this paper, we aim at increasing the utilization rate of data and investigating whether those eliminated spans are totally useless, or to what extent they can improve the performance of coreference resolution. To achieve this, we propose a mention representation refining strategy where spans highly related to mentions are well leveraged using a pointer network for representation enhancing. Notably, we utilize an additional loss term in this work to encourage the diversity between entity clusters. Experimental results on the document-level CoNLL-2012 Shared Task English dataset show that eliminated spans are indeed much effective and our approach can achieve competitive results when compared with previous state-of-the-art in coreference resolution.
A Top-Down Neural Architecture towards Text-Level Parsing of Discourse Rhetorical Structure
May 21, 2020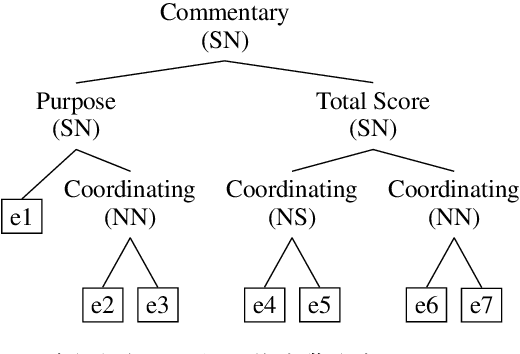
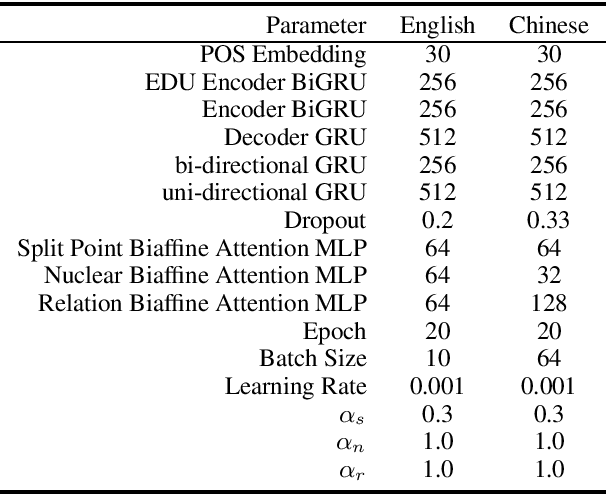
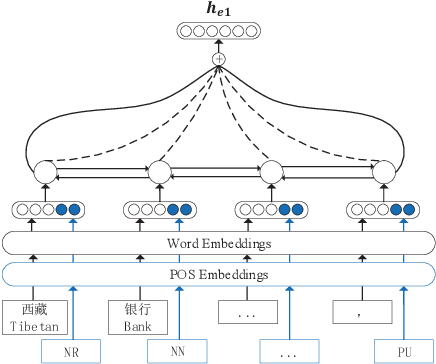
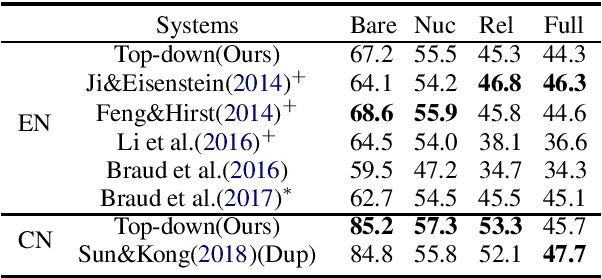
Due to its great importance in deep natural language understanding and various down-stream applications, text-level parsing of discourse rhetorical structure (DRS) has been drawing more and more attention in recent years. However, all the previous studies on text-level discourse parsing adopt bottom-up approaches, which much limit the DRS determination on local information and fail to well benefit from global information of the overall discourse. In this paper, we justify from both computational and perceptive points-of-view that the top-down architecture is more suitable for text-level DRS parsing. On the basis, we propose a top-down neural architecture toward text-level DRS parsing. In particular, we cast discourse parsing as a recursive split point ranking task, where a split point is classified to different levels according to its rank and the elementary discourse units (EDUs) associated with it are arranged accordingly. In this way, we can determine the complete DRS as a hierarchical tree structure via an encoder-decoder with an internal stack. Experimentation on both the English RST-DT corpus and the Chinese CDTB corpus shows the great effectiveness of our proposed top-down approach towards text-level DRS parsing.