 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIFEval-Audio: Benchmarking Instruction-Following Capability in Audio-based Large Language Models
May 22, 2025Large language models (LLMs) have demonstrated strong instruction-following capabilities in text-based tasks. However, this ability often deteriorates in multimodal models after alignment with non-text modalities such as images or audio. While several recent efforts have investigated instruction-following performance in text and vision-language models, instruction-following in audio-based large language models remains largely unexplored. To bridge this gap, we introduce IFEval-Audio, a novel evaluation dataset designed to assess the ability to follow instructions in an audio LLM. IFEval-Audio contains 280 audio-instruction-answer triples across six diverse dimensions: Content, Capitalization, Symbol, List Structure, Length, and Format. Each example pairs an audio input with a text instruction, requiring the model to generate an output that follows a specified structure. We benchmark state-of-the-art audio LLMs on their ability to follow audio-involved instructions. The dataset is released publicly to support future research in this emerging area.
Advancing Singlish Understanding: Bridging the Gap with Datasets and Multimodal Models
Jan 02, 2025



Singlish, a Creole language rooted in English, is a key focus in linguistic research within multilingual and multicultural contexts. However, its spoken form remains underexplored, limiting insights into its linguistic structure and applications. To address this gap, we standardize and annotate the largest spoken Singlish corpus, introducing the Multitask National Speech Corpus (MNSC). These datasets support diverse tasks, including Automatic Speech Recognition (ASR), Spoken Question Answering (SQA), Spoken Dialogue Summarization (SDS), and Paralinguistic Question Answering (PQA). We release standardized splits and a human-verified test set to facilitate further research. Additionally, we propose SingAudioLLM, a multi-task multimodal model leveraging multimodal large language models to handle these tasks concurrently. Experiments reveal our models adaptability to Singlish context, achieving state-of-the-art performance and outperforming prior models by 10-30% in comparison with other AudioLLMs and cascaded solutions.
AudioBench: A Universal Benchmark for Audio Large Language Models
Jun 25, 2024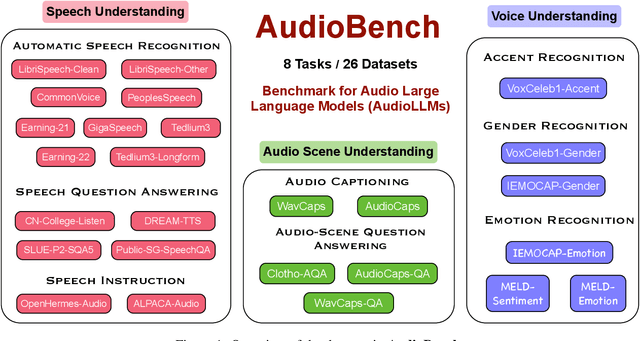
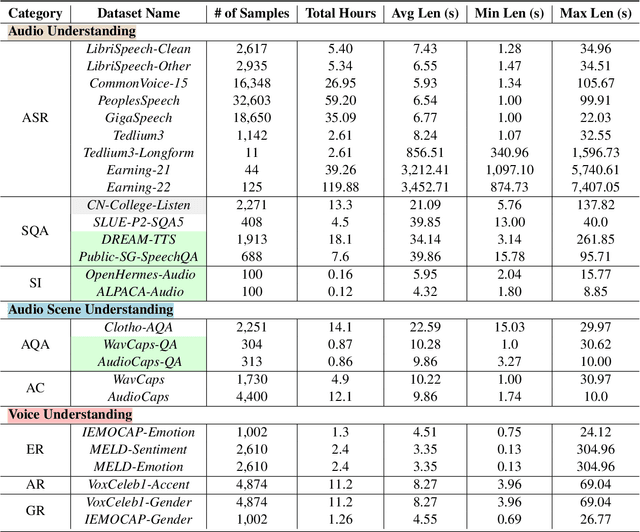
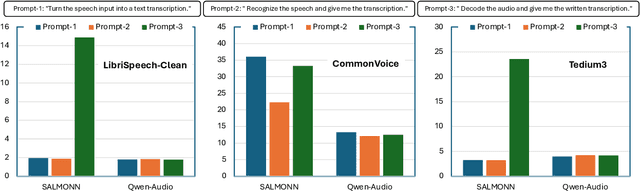
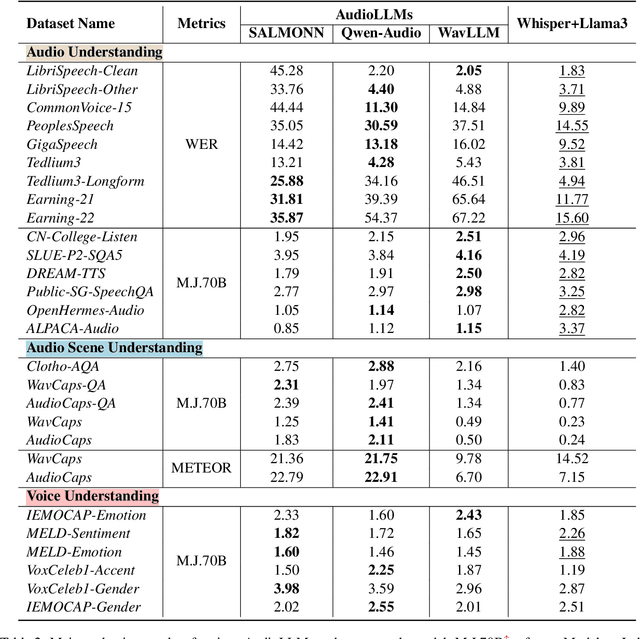
We introduce AudioBench, a new benchmark designed to evaluate audio large language models (AudioLLMs). AudioBench encompasses 8 distinct tasks and 26 carefully selected or newly curated datasets, focusing on speech understanding, voice interpretation, and audio scene understanding. Despite the rapid advancement of large language models, including multimodal versions, a significant gap exists in comprehensive benchmarks for thoroughly evaluating their capabilities. AudioBench addresses this gap by providing relevant datasets and evaluation metrics. In our study, we evaluated the capabilities of four models across various aspects and found that no single model excels consistently across all tasks. We outline the research outlook for AudioLLMs and anticipate that our open-source code, data, and leaderboard will offer a robust testbed for future model developments.