 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilience of Large Language Models for Noisy Instructions
Paper and Code
Apr 15, 2024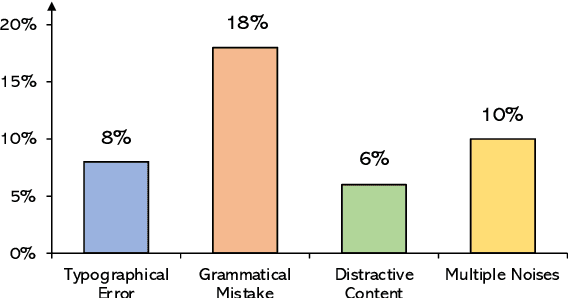



As the rapidly advancing domain of natural language processing (NLP), large language models (LLMs) have emerged as powerful tools for interpreting human commands and generating text across various tasks. Nonetheless, the resilience of LLMs to handle text containing inherent errors, stemming from human interactions and collaborative systems, has not been thoroughly explored. Our study investigates the resilience of LLMs against five common types of disruptions including 1) ASR (Automatic Speech Recognition) errors, 2) OCR (Optical Character Recognition) errors, 3) grammatical mistakes, 4) typographical errors, and 5) distractive content. We aim to investigate how these models react by deliberately embedding these errors into instructions. Our findings reveal that while some LLMs show a degree of resistance to certain types of noise, their overall performance significantly suffers. This emphasizes the importance of further investigation into enhancing model resilience. In response to the observed decline in performance, our study also evaluates a "re-pass" strategy, designed to purify the instructions of noise before the LLMs process them. Our analysis indicates that correcting noisy instructions, particularly for open-source LLMs, presents significant challenges.