 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified-MAS: Universally Generating Domain-Specific Nodes for Empowering Automatic Multi-Agent Systems
Mar 23, 2026Automatic Multi-Agent Systems (MAS) generation has emerged as a promising paradigm for solving complex reasoning tasks. However, existing frameworks are fundamentally bottlenecked when applied to knowledge-intensive domains (e.g., healthcare and law). They either rely on a static library of general nodes like Chain-of-Thought, which lack specialized expertise, or attempt to generate nodes on the fly. In the latter case, the orchestrator is not only bound by its internal knowledge limits but must also simultaneously generate domain-specific logic and optimize high-level topology, leading to a severe architectural coupling that degrades overall system efficacy. To bridge this gap, we propose Unified-MAS that decouples granular node implementation from topological orchestration via offline node synthesis. Unified-MAS operates in two stages: (1) Search-Based Node Generation retrieves external open-world knowledge to synthesize specialized node blueprints, overcoming the internal knowledge limits of LLMs; and (2) Reward-Based Node Optimization utilizes a perplexity-guided reward to iteratively enhance the internal logic of bottleneck nodes. Extensive experiments across four specialized domains demonstrate that integrating Unified-MAS into four Automatic-MAS baselines yields a better performance-cost trade-off, achieving up to a 14.2% gain while significantly reducing costs. Further analysis reveals its robustness across different designer LLMs and its effectiveness on conventional tasks such as mathematical reasoning.
A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
Apr 12, 2025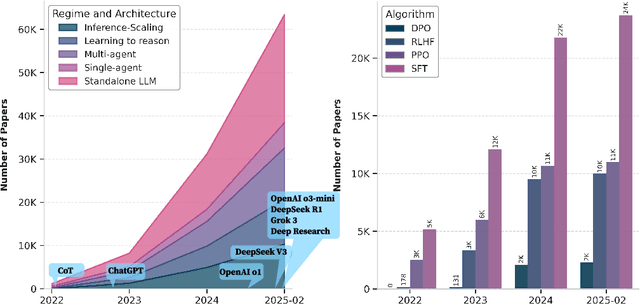

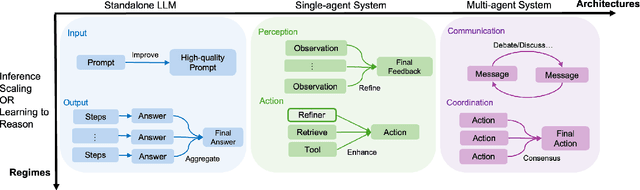

Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multi-agent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. ...
Mind the Gap! Static and Interactive Evaluations of Large Audio Models
Feb 21, 2025As AI chatbots become ubiquitous, voice interaction presents a compelling way to enable rapid, high-bandwidth communication for both semantic and social signals. This has driven research into Large Audio Models (LAMs) to power voice-native experiences. However, aligning LAM development with user goals requires a clear understanding of user needs and preferences to establish reliable progress metrics. This study addresses these challenges by introducing an interactive approach to evaluate LAMs and collecting 7,500 LAM interactions from 484 participants. Through topic modeling of user queries, we identify primary use cases for audio interfaces. We then analyze user preference rankings and qualitative feedback to determine which models best align with user needs. Finally, we evaluate how static benchmarks predict interactive performance - our analysis reveals no individual benchmark strongly correlates with interactive results ($\tau \leq 0.33$ for all benchmarks). While combining multiple coarse-grained features yields modest predictive power ($R^2$=$0.30$), only two out of twenty datasets on spoken question answering and age prediction show significantly positive correlations. This suggests a clear need to develop LAM evaluations that better correlate with user preferences.
Decompose and Aggregate: A Step-by-Step Interpretable Evaluation Framework
May 24, 2024



The acceleration of Large Language Models (LLMs) research has opened up new possibilities for evaluating generated texts. They serve as scalable and economical evaluators, but the question of how reliable these evaluators are has emerged as a crucial research question. Prior research efforts in the meta-evaluation of LLMs as judges limit the prompting of an LLM to a single use to obtain a final evaluation decision. They then compute the agreement between LLMs' outputs and human labels. This lacks interpretability in understanding the evaluation capability of LLMs. In light of this challenge, we propose Decompose and Aggregate, which breaks down the evaluation process into different stages based on pedagogical practices. Our experiments illustrate that it not only provides a more interpretable window for how well LLMs evaluate, but also leads to improvements up to 39.6% for different LLMs on a variety of meta-evaluation benchmarks.
CoAnnotating: Uncertainty-Guided Work Allocation between Human and Large Language Models for Data Annotation
Oct 24, 2023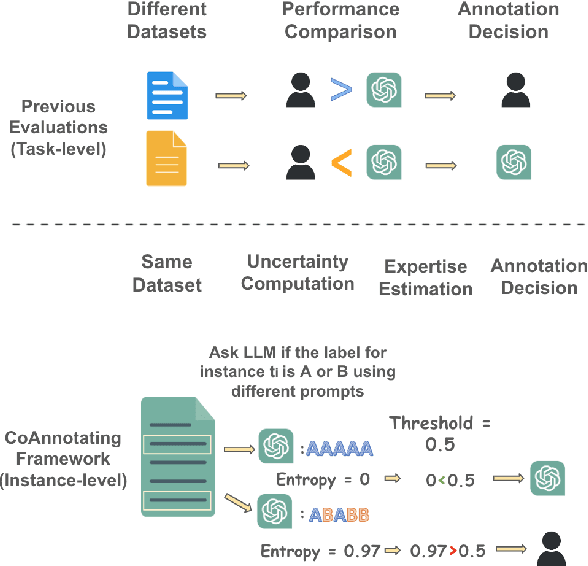

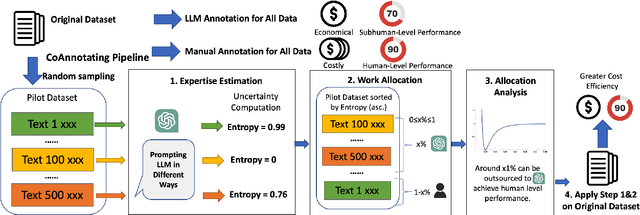
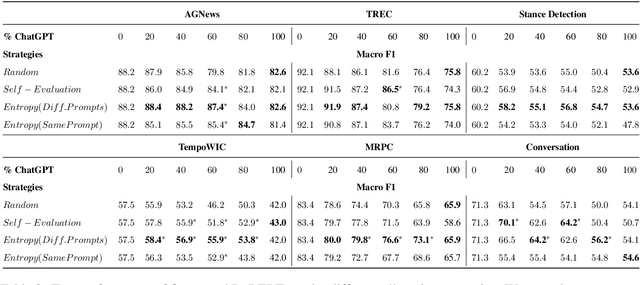
Annotated data plays a critical role in Natural Language Processing (NLP) in training models and evaluating their performance. Given recent developments in Large Language Models (LLMs), models such as ChatGPT demonstrate zero-shot capability on many text-annotation tasks, comparable with or even exceeding human annotators. Such LLMs can serve as alternatives for manual annotation, due to lower costs and higher scalability. However, limited work has leveraged LLMs as complementary annotators, nor explored how annotation work is best allocated among humans and LLMs to achieve both quality and cost objectives. We propose CoAnnotating, a novel paradigm for Human-LLM co-annotation of unstructured texts at scale. Under this framework, we utilize uncertainty to estimate LLMs' annotation capability. Our empirical study shows CoAnnotating to be an effective means to allocate work from results on different datasets, with up to 21% performance improvement over random baseline. For code implementation, see https://github.com/SALT-NLP/CoAnnotating.
Retrieving Multimodal Information for Augmented Generation: A Survey
Mar 20, 2023

In this survey, we review methods that retrieve multimodal knowledge to assist and augment generative models. This group of works focuses on retrieving grounding contexts from external sources, including images, codes, tables, graphs, and audio. As multimodal learning and generative AI have become more and more impactful, such retrieval augmentation offers a promising solution to important concerns such as factuality, reasoning, interpretability, and robustness. We provide an in-depth review of retrieval-augmented generation in different modalities and discuss potential future directions. As this is an emerging field, we continue to add new papers and methods.
Inducing Positive Perspectives with Text Reframing
Apr 06, 2022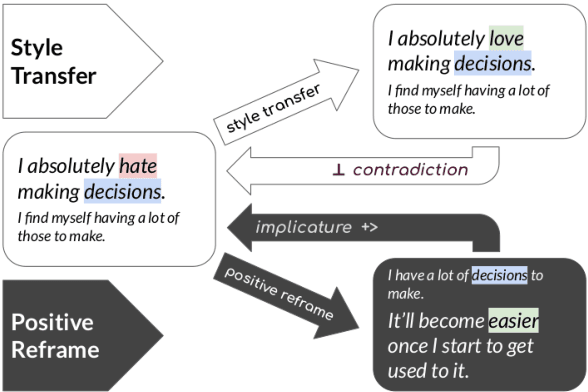
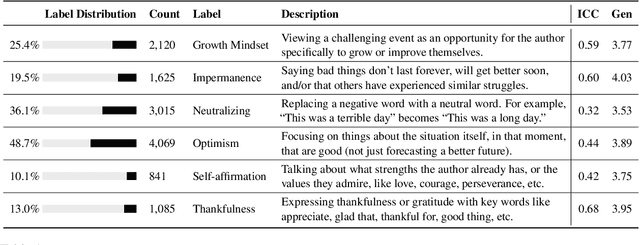
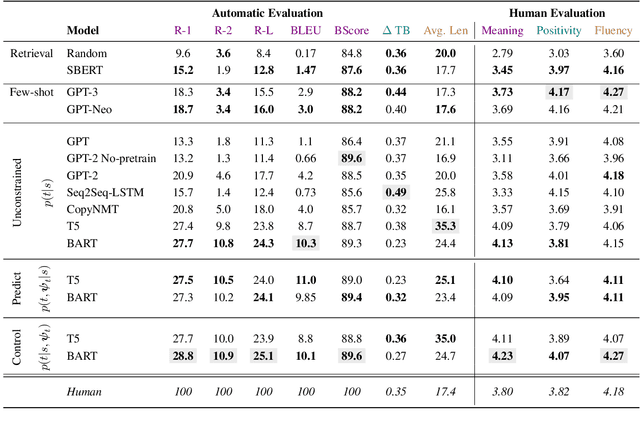
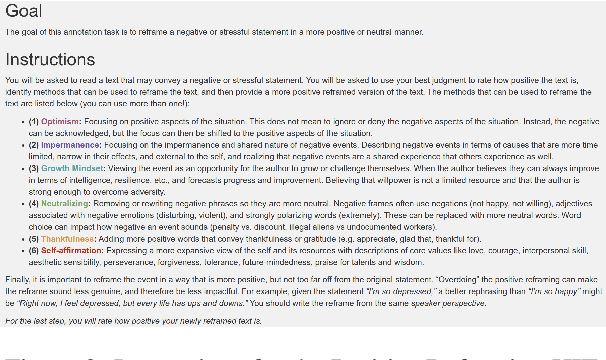
Sentiment transfer is one popular example of a text style transfer task, where the goal is to reverse the sentiment polarity of a text. With a sentiment reversal comes also a reversal in meaning. We introduce a different but related task called positive reframing in which we neutralize a negative point of view and generate a more positive perspective for the author without contradicting the original meaning. Our insistence on meaning preservation makes positive reframing a challenging and semantically rich task. To facilitate rapid progress, we introduce a large-scale benchmark, Positive Psychology Frames, with 8,349 sentence pairs and 12,755 structured annotations to explain positive reframing in terms of six theoretically-motivated reframing strategies. Then we evaluate a set of state-of-the-art text style transfer models, and conclude by discussing key challenges and directions for future work.