 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVC 2025: the First Multimodal Deception Detection Challenge
Aug 06, 2025Deception detection is a critical task in real-world applications such as security screening, fraud prevention, and credibility assessment. While deep learning methods have shown promise in surpassing human-level performance, their effectiveness often depends on the availability of high-quality and diverse deception samples. Existing research predominantly focuses on single-domain scenarios, overlooking the significant performance degradation caused by domain shifts. To address this gap, we present the SVC 2025 Multimodal Deception Detection Challenge, a new benchmark designed to evaluate cross-domain generalization in audio-visual deception detection. Participants are required to develop models that not only perform well within individual domains but also generalize across multiple heterogeneous datasets. By leveraging multimodal data, including audio, video, and text, this challenge encourages the design of models capable of capturing subtle and implicit deceptive cues. Through this benchmark, we aim to foster the development of more adaptable, explainable, and practically deployable deception detection systems, advancing the broader field of multimodal learning. By the conclusion of the workshop competition, a total of 21 teams had submitted their final results. https://sites.google.com/view/svc-mm25 for more information.
MACS: Multi-source Audio-to-image Generation with Contextual Significance and Semantic Alignment
Mar 13, 2025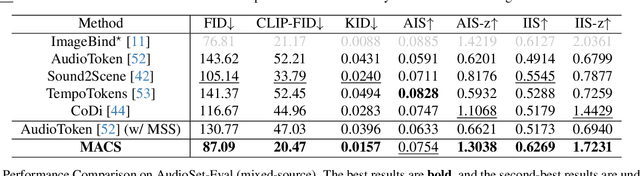
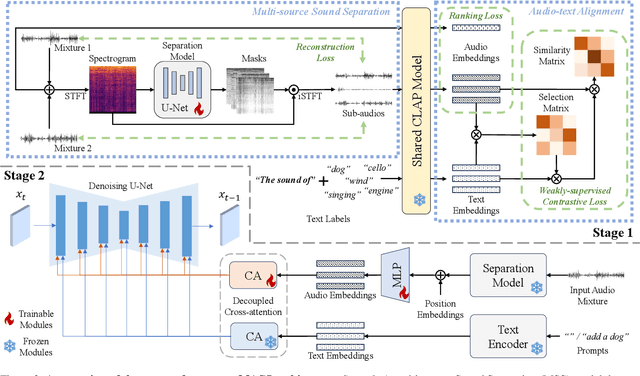
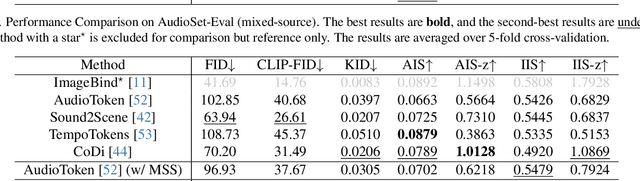
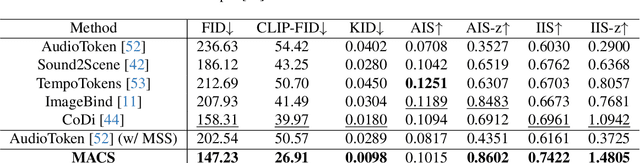
Propelled by the breakthrough in deep generative models, audio-to-image generation has emerged as a pivotal cross-model task that converts complex auditory signals into rich visual representations. However, previous works only focus on single-source audio inputs for image generation, ignoring the multi-source characteristic in natural auditory scenes, thus limiting the performance in generating comprehensive visual content. To bridge this gap, a method called MACS is proposed to conduct multi-source audio-to-image generation. This is the first work that explicitly separates multi-source audio to capture the rich audio components before image generation. MACS is a two-stage method. In the first stage, multi-source audio inputs are separated by a weakly supervised method, where the audio and text labels are semantically aligned by casting into a common space using the large pre-trained CLAP model. We introduce a ranking loss to consider the contextual significance of the separated audio signals. In the second stage, efficient image generation is achieved by mapping the separated audio signals to the generation condition using only a trainable adapter and a MLP layer. We preprocess the LLP dataset as the first full multi-source audio-to-image generation benchmark. The experiments are conducted on multi-source, mixed-source, and single-source audio-to-image generation tasks. The proposed MACS outperforms the current state-of-the-art methods in 17 of the 21 evaluation indexes on all tasks and delivers superior visual quality. The code will be publicly available.
SparseMamba-PCL: Scribble-Supervised Medical Image Segmentation via SAM-Guided Progressive Collaborative Learning
Mar 03, 2025Scribble annotations significantly reduce the cost and labor required for dense labeling in large medical datasets with complex anatomical structures. However, current scribble-supervised learning methods are limited in their ability to effectively propagate sparse annotation labels to dense segmentation masks and accurately segment object boundaries. To address these issues, we propose a Progressive Collaborative Learning framework that leverages novel algorithms and the Med-SAM foundation model to enhance information quality during training. (1) We enrich ground truth scribble segmentation labels through a new algorithm, propagating scribbles to estimate object boundaries. (2) We enhance feature representation by optimizing Med-SAM-guided training through the fusion of feature embeddings from Med-SAM and our proposed Sparse Mamba network. This enriched representation also facilitates the fine-tuning of the Med-SAM decoder with enriched scribbles. (3) For inference, we introduce a Sparse Mamba network, which is highly capable of capturing local and global dependencies by replacing the traditional sequential patch processing method with a skip-sampling procedure. Experiments on the ACDC, CHAOS, and MSCMRSeg datasets validate the effectiveness of our framework, outperforming nine state-of-the-art methods. Our code is available at \href{https://github.com/QLYCode/SparseMamba-PCL}{SparseMamba-PCL.git}.
Benchmarking Cross-Domain Audio-Visual Deception Detection
May 11, 2024



Automated deception detection is crucial for assisting humans in accurately assessing truthfulness and identifying deceptive behavior. Conventional contact-based techniques, like polygraph devices, rely on physiological signals to determine the authenticity of an individual's statements. Nevertheless, recent developments in automated deception detection have demonstrated that multimodal features derived from both audio and video modalities may outperform human observers on publicly available datasets. Despite these positive findings, the generalizability of existing audio-visual deception detection approaches across different scenarios remains largely unexplored. To close this gap, we present the first cross-domain audio-visual deception detection benchmark, that enables us to assess how well these methods generalize for use in real-world scenarios. We used widely adopted audio and visual features and different architectures for benchmarking, comparing single-to-single and multi-to-single domain generalization performance. To further exploit the impacts using data from multiple source domains for training, we investigate three types of domain sampling strategies, including domain-simultaneous, domain-alternating, and domain-by-domain for multi-to-single domain generalization evaluation. Furthermore, we proposed the Attention-Mixer fusion method to improve performance, and we believe that this new cross-domain benchmark will facilitate future research in audio-visual deception detection. Protocols and source code are available at \href{https://github.com/Redaimao/cross_domain_DD}{https://github.com/Redaimao/cross\_domain\_DD}.
Improving Concept Alignment in Vision-Language Concept Bottleneck Models
May 03, 2024
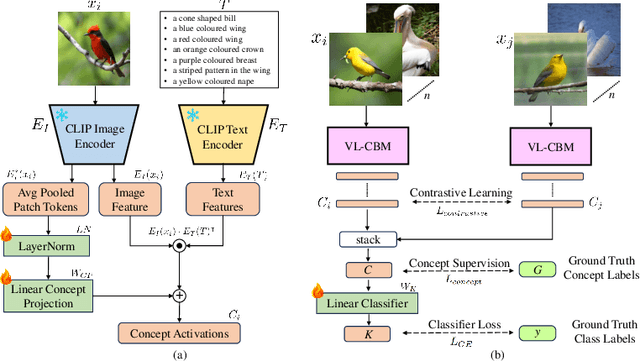


Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
MIMIC: Mask Image Pre-training with Mix Contrastive Fine-tuning for Facial Expression Recognition
Jan 14, 2024Cutting-edge research in facial expression recognition (FER) currently favors the utilization of convolutional neural networks (CNNs) backbone which is supervisedly pre-trained on face recognition datasets for feature extraction. However, due to the vast scale of face recognition datasets and the high cost associated with collecting facial labels, this pre-training paradigm incurs significant expenses. Towards this end, we propose to pre-train vision Transformers (ViTs) through a self-supervised approach on a mid-scale general image dataset. In addition, when compared with the domain disparity existing between face datasets and FER datasets, the divergence between general datasets and FER datasets is more pronounced. Therefore, we propose a contrastive fine-tuning approach to effectively mitigate this domain disparity. Specifically, we introduce a novel FER training paradigm named Mask Image pre-training with MIx Contrastive fine-tuning (MIMIC). In the initial phase, we pre-train the ViT via masked image reconstruction on general images. Subsequently, in the fine-tuning stage, we introduce a mix-supervised contrastive learning process, which enhances the model with a more extensive range of positive samples by the mixing strategy. Through extensive experiments conducted on three benchmark datasets, we demonstrate that our MIMIC outperforms the previous training paradigm, showing its capability to learn better representations. Remarkably, the results indicate that the vanilla ViT can achieve impressive performance without the need for intricate, auxiliary-designed modules. Moreover, when scaling up the model size, MIMIC exhibits no performance saturation and is superior to the current state-of-the-art methods.
Retrieving Multimodal Information for Augmented Generation: A Survey
Mar 20, 2023

In this survey, we review methods that retrieve multimodal knowledge to assist and augment generative models. This group of works focuses on retrieving grounding contexts from external sources, including images, codes, tables, graphs, and audio. As multimodal learning and generative AI have become more and more impactful, such retrieval augmentation offers a promising solution to important concerns such as factuality, reasoning, interpretability, and robustness. We provide an in-depth review of retrieval-augmented generation in different modalities and discuss potential future directions. As this is an emerging field, we continue to add new papers and methods.
Adapter Incremental Continual Learning of Efficient Audio Spectrogram Transformers
Feb 28, 2023Continual learning involves training neural networks incrementally for new tasks while retaining the knowledge of previous tasks. However, efficiently fine-tuning the model for sequential tasks with minimal computational resources remains a challenge. In this paper, we propose Task Incremental Continual Learning (TI-CL) of audio classifiers with both parameter-efficient and compute-efficient Audio Spectrogram Transformers (AST). To reduce the trainable parameters without performance degradation for TI-CL, we compare several Parameter Efficient Transfer (PET) methods and propose AST with Convolutional Adapters for TI-CL, which has less than 5% of trainable parameters of the fully fine-tuned counterparts. To reduce the computational complexity, we introduce a novel Frequency-Time factorized Attention (FTA) method that replaces the traditional self-attention in transformers for audio spectrograms. FTA achieves competitive performance with only a factor of the computations required by Global Self-Attention (GSA). Finally, we formulate our method for TI-CL, called Adapter Incremental Continual Learning (AI-CL), as a combination of the "parameter-efficient" Convolutional Adapter and the "compute-efficient" FTA. Experiments on ESC-50, SpeechCommandsV2 (SCv2), and Audio-Visual Event (AVE) benchmarks show that our proposed method prevents catastrophic forgetting in TI-CL while maintaining a lower computational budget.
Flexible-modal Deception Detection with Audio-Visual Adapter
Feb 11, 2023



Detecting deception by human behaviors is vital in many fields such as custom security and multimedia anti-fraud. Recently, audio-visual deception detection attracts more attention due to its better performance than using only a single modality. However, in real-world multi-modal settings, the integrity of data can be an issue (e.g., sometimes only partial modalities are available). The missing modality might lead to a decrease in performance, but the model still learns the features of the missed modality. In this paper, to further improve the performance and overcome the missing modality problem, we propose a novel Transformer-based framework with an Audio-Visual Adapter (AVA) to fuse temporal features across two modalities efficiently. Extensive experiments conducted on two benchmark datasets demonstrate that the proposed method can achieve superior performance compared with other multi-modal fusion methods under flexible-modal (multiple and missing modalities) settings.
Towards Photo-Realistic Virtual Try-On by Adaptively Generating$\leftrightarrow$Preserving Image Content
Mar 12, 2020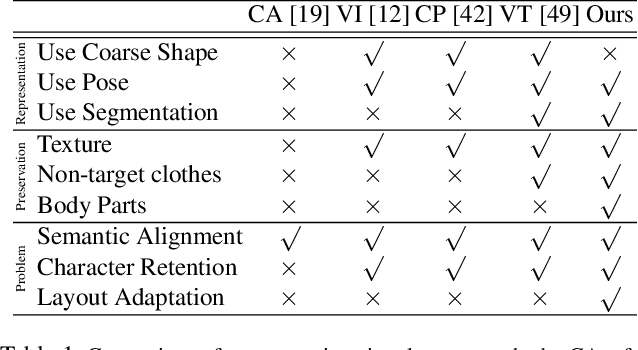
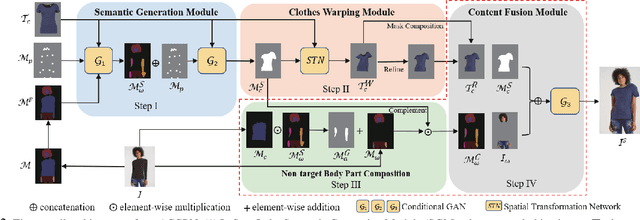
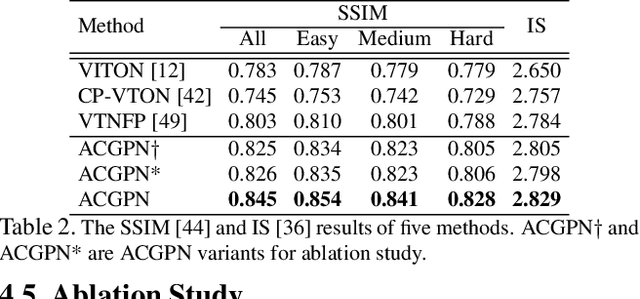

Image visual try-on aims at transferring a target clothing image onto a reference person, and has become a hot topic in recent years. Prior arts usually focus on preserving the character of a clothing image (e.g. texture, logo, embroidery) when warping it to arbitrary human pose. However, it remains a big challenge to generate photo-realistic try-on images when large occlusions and human poses are presented in the reference person. To address this issue, we propose a novel visual try-on network, namely Adaptive Content Generating and Preserving Network (ACGPN). In particular, ACGPN first predicts semantic layout of the reference image that will be changed after try-on (e.g. long sleeve shirt$\rightarrow$arm, arm$\rightarrow$jacket), and then determines whether its image content needs to be generated or preserved according to the predicted semantic layout, leading to photo-realistic try-on and rich clothing details. ACGPN generally involves three major modules. First, a semantic layout generation module utilizes semantic segmentation of the reference image to progressively predict the desired semantic layout after try-on. Second, a clothes warping module warps clothing images according to the generated semantic layout, where a second-order difference constraint is introduced to stabilize the warping process during training. Third, an inpainting module for content fusion integrates all information (e.g. reference image, semantic layout, warped clothes) to adaptively produce each semantic part of human body. In comparison to the state-of-the-art methods, ACGPN can generate photo-realistic images with much better perceptual quality and richer fine-details.