 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Photo-Realistic Virtual Try-On by Adaptively Generating$\leftrightarrow$Preserving Image Content
Paper and Code
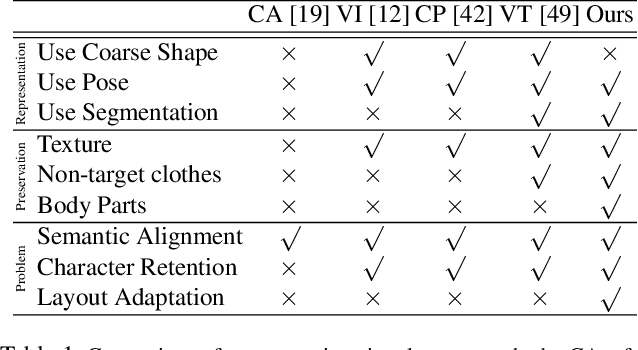
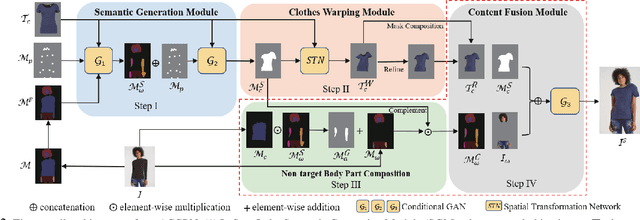
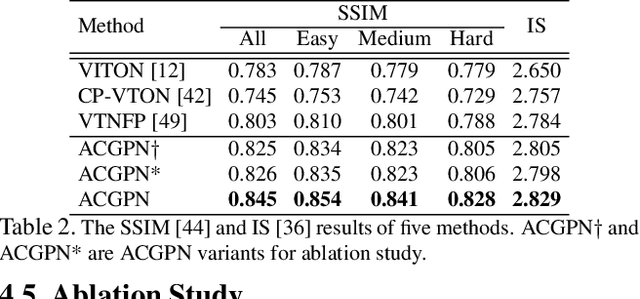

Image visual try-on aims at transferring a target clothing image onto a reference person, and has become a hot topic in recent years. Prior arts usually focus on preserving the character of a clothing image (e.g. texture, logo, embroidery) when warping it to arbitrary human pose. However, it remains a big challenge to generate photo-realistic try-on images when large occlusions and human poses are presented in the reference person. To address this issue, we propose a novel visual try-on network, namely Adaptive Content Generating and Preserving Network (ACGPN). In particular, ACGPN first predicts semantic layout of the reference image that will be changed after try-on (e.g. long sleeve shirt$\rightarrow$arm, arm$\rightarrow$jacket), and then determines whether its image content needs to be generated or preserved according to the predicted semantic layout, leading to photo-realistic try-on and rich clothing details. ACGPN generally involves three major modules. First, a semantic layout generation module utilizes semantic segmentation of the reference image to progressively predict the desired semantic layout after try-on. Second, a clothes warping module warps clothing images according to the generated semantic layout, where a second-order difference constraint is introduced to stabilize the warping process during training. Third, an inpainting module for content fusion integrates all information (e.g. reference image, semantic layout, warped clothes) to adaptively produce each semantic part of human body. In comparison to the state-of-the-art methods, ACGPN can generate photo-realistic images with much better perceptual quality and richer fine-details.