 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACS: Multi-source Audio-to-image Generation with Contextual Significance and Semantic Alignment
Paper and Code
Mar 13, 2025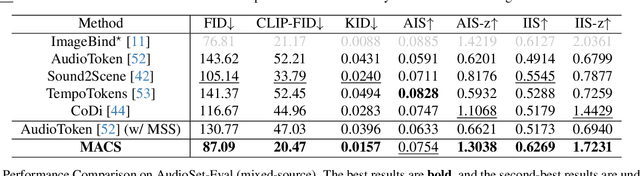
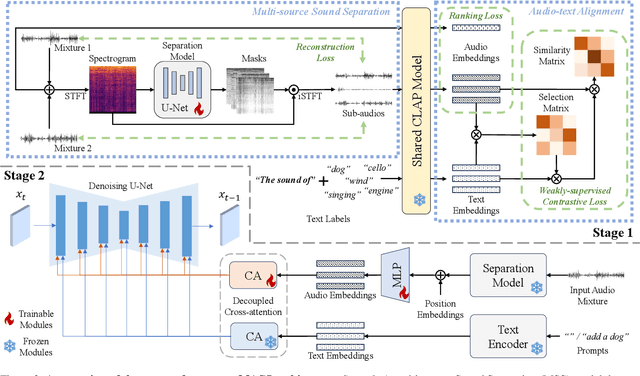
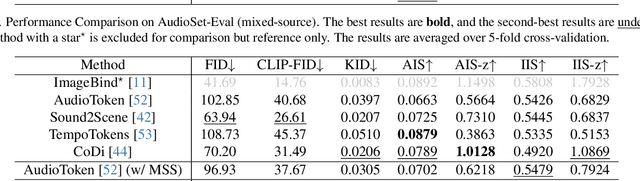
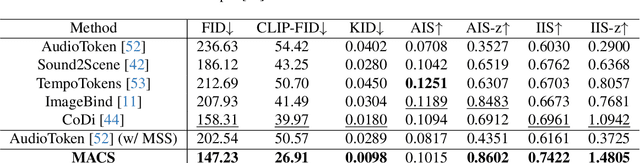
Propelled by the breakthrough in deep generative models, audio-to-image generation has emerged as a pivotal cross-model task that converts complex auditory signals into rich visual representations. However, previous works only focus on single-source audio inputs for image generation, ignoring the multi-source characteristic in natural auditory scenes, thus limiting the performance in generating comprehensive visual content. To bridge this gap, a method called MACS is proposed to conduct multi-source audio-to-image generation. This is the first work that explicitly separates multi-source audio to capture the rich audio components before image generation. MACS is a two-stage method. In the first stage, multi-source audio inputs are separated by a weakly supervised method, where the audio and text labels are semantically aligned by casting into a common space using the large pre-trained CLAP model. We introduce a ranking loss to consider the contextual significance of the separated audio signals. In the second stage, efficient image generation is achieved by mapping the separated audio signals to the generation condition using only a trainable adapter and a MLP layer. We preprocess the LLP dataset as the first full multi-source audio-to-image generation benchmark. The experiments are conducted on multi-source, mixed-source, and single-source audio-to-image generation tasks. The proposed MACS outperforms the current state-of-the-art methods in 17 of the 21 evaluation indexes on all tasks and delivers superior visual quality. The code will be publicly available.