 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Cross-Domain Audio-Visual Deception Detection
May 11, 2024



Automated deception detection is crucial for assisting humans in accurately assessing truthfulness and identifying deceptive behavior. Conventional contact-based techniques, like polygraph devices, rely on physiological signals to determine the authenticity of an individual's statements. Nevertheless, recent developments in automated deception detection have demonstrated that multimodal features derived from both audio and video modalities may outperform human observers on publicly available datasets. Despite these positive findings, the generalizability of existing audio-visual deception detection approaches across different scenarios remains largely unexplored. To close this gap, we present the first cross-domain audio-visual deception detection benchmark, that enables us to assess how well these methods generalize for use in real-world scenarios. We used widely adopted audio and visual features and different architectures for benchmarking, comparing single-to-single and multi-to-single domain generalization performance. To further exploit the impacts using data from multiple source domains for training, we investigate three types of domain sampling strategies, including domain-simultaneous, domain-alternating, and domain-by-domain for multi-to-single domain generalization evaluation. Furthermore, we proposed the Attention-Mixer fusion method to improve performance, and we believe that this new cross-domain benchmark will facilitate future research in audio-visual deception detection. Protocols and source code are available at \href{https://github.com/Redaimao/cross_domain_DD}{https://github.com/Redaimao/cross\_domain\_DD}.
Improving Concept Alignment in Vision-Language Concept Bottleneck Models
May 03, 2024
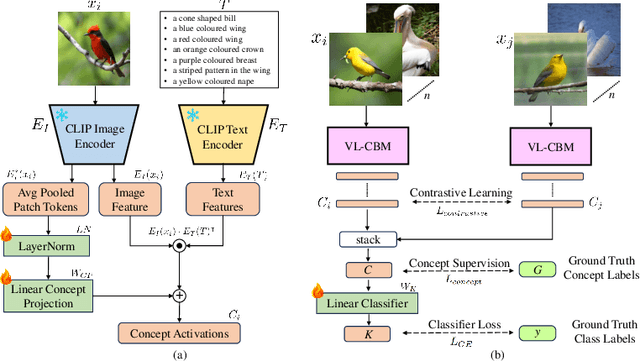


Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
Adapter Incremental Continual Learning of Efficient Audio Spectrogram Transformers
Feb 28, 2023Continual learning involves training neural networks incrementally for new tasks while retaining the knowledge of previous tasks. However, efficiently fine-tuning the model for sequential tasks with minimal computational resources remains a challenge. In this paper, we propose Task Incremental Continual Learning (TI-CL) of audio classifiers with both parameter-efficient and compute-efficient Audio Spectrogram Transformers (AST). To reduce the trainable parameters without performance degradation for TI-CL, we compare several Parameter Efficient Transfer (PET) methods and propose AST with Convolutional Adapters for TI-CL, which has less than 5% of trainable parameters of the fully fine-tuned counterparts. To reduce the computational complexity, we introduce a novel Frequency-Time factorized Attention (FTA) method that replaces the traditional self-attention in transformers for audio spectrograms. FTA achieves competitive performance with only a factor of the computations required by Global Self-Attention (GSA). Finally, we formulate our method for TI-CL, called Adapter Incremental Continual Learning (AI-CL), as a combination of the "parameter-efficient" Convolutional Adapter and the "compute-efficient" FTA. Experiments on ESC-50, SpeechCommandsV2 (SCv2), and Audio-Visual Event (AVE) benchmarks show that our proposed method prevents catastrophic forgetting in TI-CL while maintaining a lower computational budget.
Flexible-modal Deception Detection with Audio-Visual Adapter
Feb 11, 2023



Detecting deception by human behaviors is vital in many fields such as custom security and multimedia anti-fraud. Recently, audio-visual deception detection attracts more attention due to its better performance than using only a single modality. However, in real-world multi-modal settings, the integrity of data can be an issue (e.g., sometimes only partial modalities are available). The missing modality might lead to a decrease in performance, but the model still learns the features of the missed modality. In this paper, to further improve the performance and overcome the missing modality problem, we propose a novel Transformer-based framework with an Audio-Visual Adapter (AVA) to fuse temporal features across two modalities efficiently. Extensive experiments conducted on two benchmark datasets demonstrate that the proposed method can achieve superior performance compared with other multi-modal fusion methods under flexible-modal (multiple and missing modalities) settings.