 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Collaborative Process Parameter Recommender System for Fleets of Networked Manufacturing Machines -- with Application to 3D Printing
Jun 13, 2025Fleets of networked manufacturing machines of the same type, that are collocated or geographically distributed, are growing in popularity. An excellent example is the rise of 3D printing farms, which consist of multiple networked 3D printers operating in parallel, enabling faster production and efficient mass customization. However, optimizing process parameters across a fleet of manufacturing machines, even of the same type, remains a challenge due to machine-to-machine variability. Traditional trial-and-error approaches are inefficient, requiring extensive testing to determine optimal process parameters for an entire fleet. In this work, we introduce a machine learning-based collaborative recommender system that optimizes process parameters for each machine in a fleet by modeling the problem as a sequential matrix completion task. Our approach leverages spectral clustering and alternating least squares to iteratively refine parameter predictions, enabling real-time collaboration among the machines in a fleet while minimizing the number of experimental trials. We validate our method using a mini 3D printing farm consisting of ten 3D printers for which we optimize acceleration and speed settings to maximize print quality and productivity. Our approach achieves significantly faster convergence to optimal process parameters compared to non-collaborative matrix completion.
Composable and adaptive design of machine learning interatomic potentials guided by Fisher-information analysis
Apr 27, 2025An adaptive physics-informed model design strategy for machine-learning interatomic potentials (MLIPs) is proposed. This strategy follows an iterative reconfiguration of composite models from single-term models, followed by a unified training procedure. A model evaluation method based on the Fisher information matrix (FIM) and multiple-property error metrics is proposed to guide model reconfiguration and hyperparameter optimization. Combining the model reconfiguration and the model evaluation subroutines, we provide an adaptive MLIP design strategy that balances flexibility and extensibility. In a case study of designing models against a structurally diverse niobium dataset, we managed to obtain an optimal configuration with 75 parameters generated by our framework that achieved a force RMSE of 0.172 eV/{\AA} and an energy RMSE of 0.013 eV/atom.
Personalized Binomial DAGs Learning with Network Structured Covariates
Jun 10, 2024



The causal dependence in data is often characterized by Directed Acyclic Graphical (DAG) models, widely used in many areas. Causal discovery aims to recover the DAG structure using observational data. This paper focuses on causal discovery with multi-variate count data. We are motivated by real-world web visit data, recording individual user visits to multiple websites. Building a causal diagram can help understand user behavior in transitioning between websites, inspiring operational strategy. A challenge in modeling is user heterogeneity, as users with different backgrounds exhibit varied behaviors. Additionally, social network connections can result in similar behaviors among friends. We introduce personalized Binomial DAG models to address heterogeneity and network dependency between observations, which are common in real-world applications. To learn the proposed DAG model, we develop an algorithm that embeds the network structure into a dimension-reduced covariate, learns each node's neighborhood to reduce the DAG search space, and explores the variance-mean relation to determine the ordering. Simulations show our algorithm outperforms state-of-the-art competitors in heterogeneous data. We demonstrate its practical usefulness on a real-world web visit dataset.
RAP-Gen: Retrieval-Augmented Patch Generation with CodeT5 for Automatic Program Repair
Sep 12, 2023



Automatic program repair (APR) is crucial to reduce manual debugging efforts for developers and improve software reliability. While conventional search-based techniques typically rely on heuristic rules or a redundancy assumption to mine fix patterns, recent years have witnessed the surge of deep learning (DL) based approaches to automate the program repair process in a data-driven manner. However, their performance is often limited by a fixed set of parameters to model the highly complex search space of APR. To ease such burden on the parametric models, in this work, we propose a novel Retrieval-Augmented Patch Generation framework (RAP-Gen) by explicitly leveraging relevant fix patterns retrieved from a codebase of previous bug-fix pairs. Specifically, we build a hybrid patch retriever to account for both lexical and semantic matching based on the raw source code in a language-agnostic manner, which does not rely on any code-specific features. In addition, we adapt a code-aware language model CodeT5 as our foundation model to facilitate both patch retrieval and generation tasks in a unified manner. We adopt a stage-wise approach where the patch retriever first retrieves a relevant external bug-fix pair to augment the buggy input for the CodeT5 patch generator, which synthesizes a ranked list of repair patch candidates. Notably, RAP-Gen is a generic APR framework that can flexibly integrate different patch retrievers and generators to repair various types of bugs. We thoroughly evaluate RAP-Gen on three benchmarks in two programming languages, including the TFix benchmark in JavaScript, and Code Refinement and Defects4J benchmarks in Java, where the bug localization information may or may not be provided. Experimental results show that RAP-Gen significantly outperforms previous state-of-the-art approaches on all benchmarks, e.g., repairing 15 more bugs on 818 Defects4J bugs.
Retrieving Multimodal Information for Augmented Generation: A Survey
Mar 20, 2023

In this survey, we review methods that retrieve multimodal knowledge to assist and augment generative models. This group of works focuses on retrieving grounding contexts from external sources, including images, codes, tables, graphs, and audio. As multimodal learning and generative AI have become more and more impactful, such retrieval augmentation offers a promising solution to important concerns such as factuality, reasoning, interpretability, and robustness. We provide an in-depth review of retrieval-augmented generation in different modalities and discuss potential future directions. As this is an emerging field, we continue to add new papers and methods.
xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval
Mar 06, 2023



The ability to solve problems is a hallmark of intelligence and has been an enduring goal in AI. AI systems that can create programs as solutions to problems or assist developers in writing programs can increase productivity and make programming more accessible. Recently, pre-trained large language models have shown impressive abilities in generating new codes from natural language descriptions, repairing buggy codes, translating codes between languages, and retrieving relevant code segments. However, the evaluation of these models has often been performed in a scattered way on only one or two specific tasks, in a few languages, at a partial granularity (e.g., function) level and in many cases without proper training data. Even more concerning is that in most cases the evaluation of generated codes has been done in terms of mere lexical overlap rather than actual execution whereas semantic similarity (or equivalence) of two code segments depends only on their ``execution similarity'', i.e., being able to get the same output for a given input.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation
Sep 02, 2021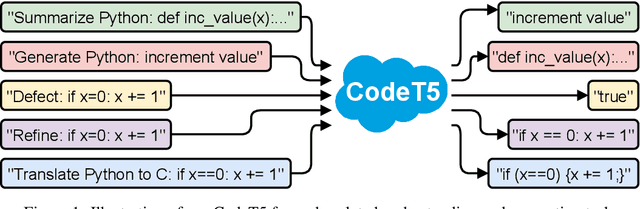

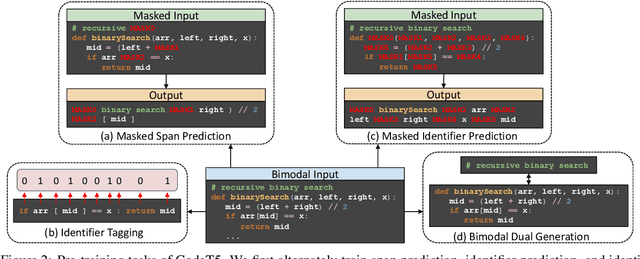
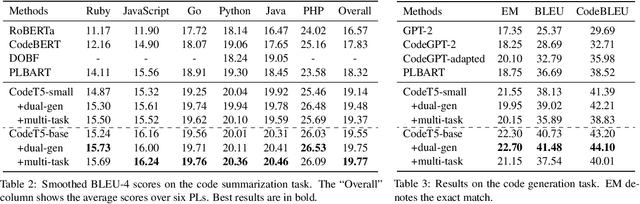
Pre-trained models for Natural Languages (NL) like BERT and GPT have been recently shown to transfer well to Programming Languages (PL) and largely benefit a broad set of code-related tasks. Despite their success, most current methods either rely on an encoder-only (or decoder-only) pre-training that is suboptimal for generation (resp. understanding) tasks or process the code snippet in the same way as NL, neglecting the special characteristics of PL such as token types. We present CodeT5, a unified pre-trained encoder-decoder Transformer model that better leverages the code semantics conveyed from the developer-assigned identifiers. Our model employs a unified framework to seamlessly support both code understanding and generation tasks and allows for multi-task learning. Besides, we propose a novel identifier-aware pre-training task that enables the model to distinguish which code tokens are identifiers and to recover them when they are masked. Furthermore, we propose to exploit the user-written code comments with a bimodal dual generation task for better NL-PL alignment. Comprehensive experiments show that CodeT5 significantly outperforms prior methods on understanding tasks such as code defect detection and clone detection, and generation tasks across various directions including PL-NL, NL-PL, and PL-PL. Further analysis reveals that our model can better capture semantic information from code. Our code and pre-trained models are released at https: //github.com/salesforce/CodeT5 .
Response Selection for Multi-Party Conversations with Dynamic Topic Tracking
Oct 15, 2020
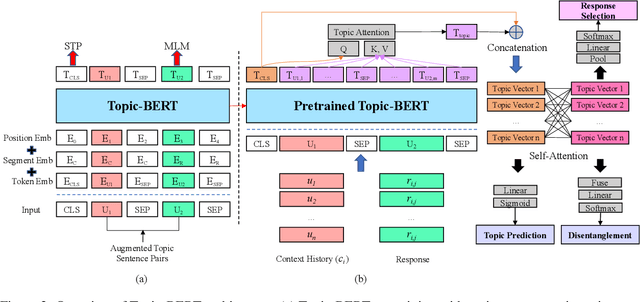
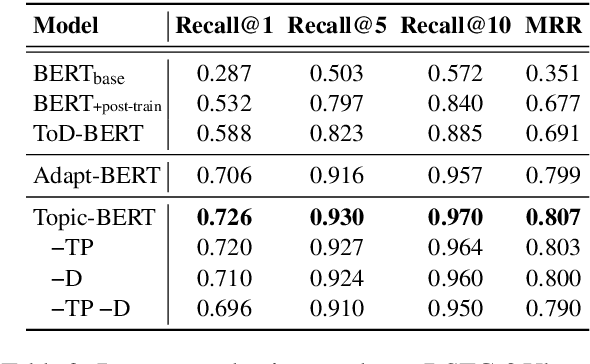
While participants in a multi-party multi-turn conversation simultaneously engage in multiple conversation topics, existing response selection methods are developed mainly focusing on a two-party single-conversation scenario. Hence, the prolongation and transition of conversation topics are ignored by current methods. In this work, we frame response selection as a dynamic topic tracking task to match the topic between the response and relevant conversation context. With this new formulation, we propose a novel multi-task learning framework that supports efficient encoding through large pretrained models with only two utterances at once to perform dynamic topic disentanglement and response selection. We also propose Topic-BERT an essential pretraining step to embed topic information into BERT with self-supervised learning. Experimental results on the DSTC-8 Ubuntu IRC dataset show state-of-the-art results in response selection and topic disentanglement tasks outperforming existing methods by a good margin.