 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Multi-Turn Search Agent via Contrastive Dynamic Branch Sampling
Feb 03, 2026Agentic reinforcement learning has enabled large language models to perform complex multi-turn planning and tool use. However, learning in long-horizon settings remains challenging due to sparse, trajectory-level outcome rewards. While prior tree-based methods attempt to mitigate this issue, they often suffer from high variance and computational inefficiency. Through empirical analysis of search agents, We identify a common pattern: performance diverges mainly due to decisions near the tail. Motivated by this observation, we propose Branching Relative Policy Optimization (BranPO), a value-free method that provides step-level contrastive supervision without dense rewards. BranPO truncates trajectories near the tail and resamples alternative continuations to construct contrastive suffixes over shared prefixes, reducing credit ambiguity in long-horizon rollouts. To further boost efficiency and stabilize training, we introduce difficulty-aware branch sampling to adapt branching frequency across tasks, and redundant step masking to suppress uninformative actions. Extensive experiments on various question answering benchmarks demonstrate that BranPO consistently outperforms strong baselines, achieving significant accuracy gains on long-horizon tasks without increasing the overall training budget. Our code is available at \href{https://github.com/YubaoZhao/BranPO}{code}.
DR-Arena: an Automated Evaluation Framework for Deep Research Agents
Jan 15, 2026As Large Language Models (LLMs) increasingly operate as Deep Research (DR) Agents capable of autonomous investigation and information synthesis, reliable evaluation of their task performance has become a critical bottleneck. Current benchmarks predominantly rely on static datasets, which suffer from several limitations: limited task generality, temporal misalignment, and data contamination. To address these, we introduce DR-Arena, a fully automated evaluation framework that pushes DR agents to their capability limits through dynamic investigation. DR-Arena constructs real-time Information Trees from fresh web trends to ensure the evaluation rubric is synchronized with the live world state, and employs an automated Examiner to generate structured tasks testing two orthogonal capabilities: Deep reasoning and Wide coverage. DR-Arena further adopts Adaptive Evolvement Loop, a state-machine controller that dynamically escalates task complexity based on real-time performance, demanding deeper deduction or wider aggregation until a decisive capability boundary emerges. Experiments with six advanced DR agents demonstrate that DR-Arena achieves a Spearman correlation of 0.94 with the LMSYS Search Arena leaderboard. This represents the state-of-the-art alignment with human preferences without any manual efforts, validating DR-Arena as a reliable alternative for costly human adjudication.
AgREE: Agentic Reasoning for Knowledge Graph Completion on Emerging Entities
Aug 06, 2025Open-domain Knowledge Graph Completion (KGC) faces significant challenges in an ever-changing world, especially when considering the continual emergence of new entities in daily news. Existing approaches for KGC mainly rely on pretrained language models' parametric knowledge, pre-constructed queries, or single-step retrieval, typically requiring substantial supervision and training data. Even so, they often fail to capture comprehensive and up-to-date information about unpopular and/or emerging entities. To this end, we introduce Agentic Reasoning for Emerging Entities (AgREE), a novel agent-based framework that combines iterative retrieval actions and multi-step reasoning to dynamically construct rich knowledge graph triplets. Experiments show that, despite requiring zero training efforts, AgREE significantly outperforms existing methods in constructing knowledge graph triplets, especially for emerging entities that were not seen during language models' training processes, outperforming previous methods by up to 13.7%. Moreover, we propose a new evaluation methodology that addresses a fundamental weakness of existing setups and a new benchmark for KGC on emerging entities. Our work demonstrates the effectiveness of combining agent-based reasoning with strategic information retrieval for maintaining up-to-date knowledge graphs in dynamic information environments.
Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents
Oct 25, 2024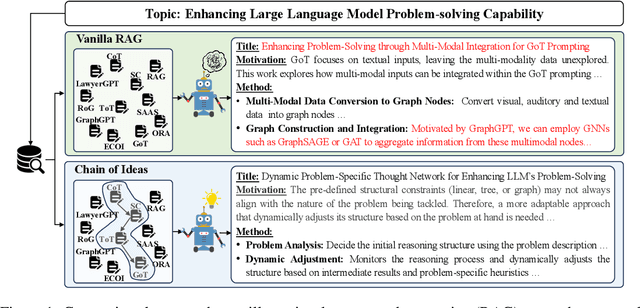

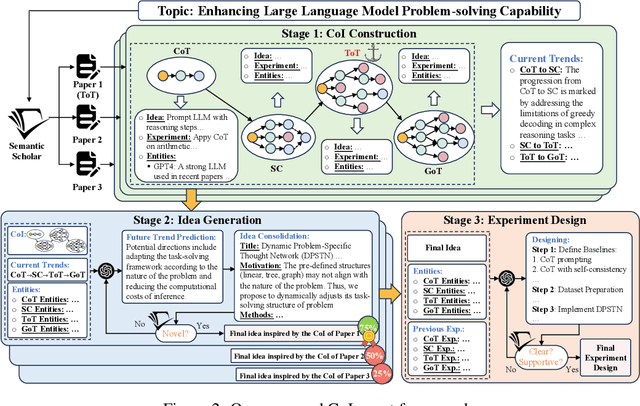
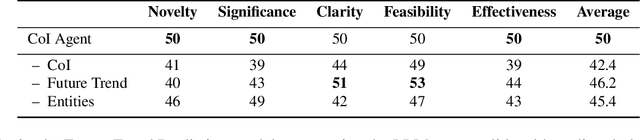
Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
Chain of Ideas: Revolutionizing Research in Novel Idea Development with LLM Agents
Oct 17, 2024Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
Can We Further Elicit Reasoning in LLMs? Critic-Guided Planning with Retrieval-Augmentation for Solving Challenging Tasks
Oct 02, 2024State-of-the-art large language models (LLMs) exhibit impressive problem-solving capabilities but may struggle with complex reasoning and factual correctness. Existing methods harness the strengths of chain-of-thought and retrieval-augmented generation (RAG) to decompose a complex problem into simpler steps and apply retrieval to improve factual correctness. These methods work well on straightforward reasoning tasks but often falter on challenging tasks such as competitive programming and mathematics, due to frequent reasoning errors and irrelevant knowledge retrieval. To address this, we introduce Critic-guided planning with Retrieval-augmentation, CR-Planner, a novel framework that leverages fine-tuned critic models to guide both reasoning and retrieval processes through planning. CR-Planner solves a problem by iteratively selecting and executing sub-goals. Initially, it identifies the most promising sub-goal from reasoning, query generation, and retrieval, guided by rewards given by a critic model named sub-goal critic. It then executes this sub-goal through sampling and selecting the optimal output based on evaluations from another critic model named execution critic. This iterative process, informed by retrieved information and critic models, enables CR-Planner to effectively navigate the solution space towards the final answer. We employ Monte Carlo Tree Search to collect the data for training the critic models, allowing for a systematic exploration of action sequences and their long-term impacts. We validate CR-Planner on challenging domain-knowledge-intensive and reasoning-heavy tasks, including competitive programming, theorem-driven math reasoning, and complex domain retrieval problems. Our experiments demonstrate that CR-Planner significantly outperforms baselines, highlighting its effectiveness in addressing challenging problems by improving both reasoning and retrieval.
Auto Arena of LLMs: Automating LLM Evaluations with Agent Peer-battles and Committee Discussions
May 30, 2024
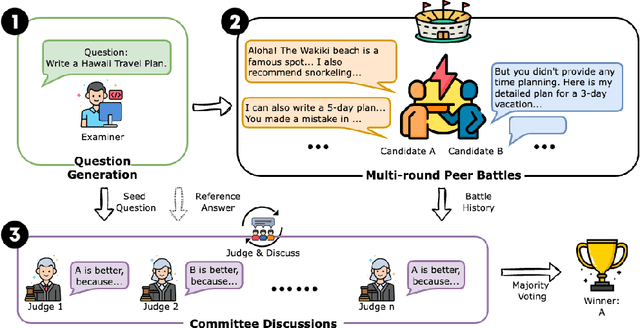
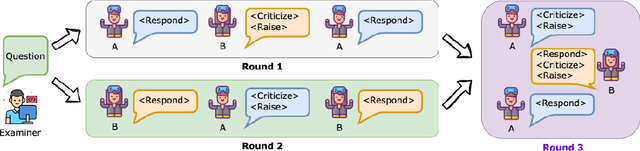
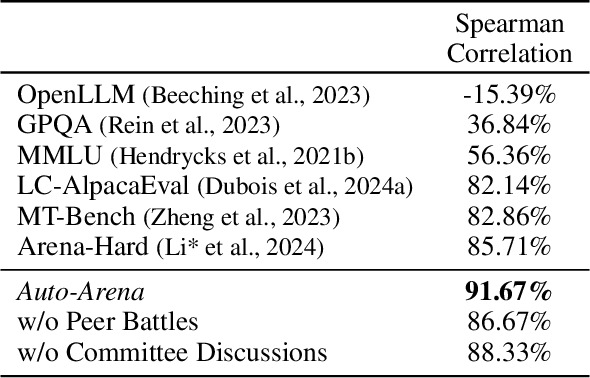
As LLMs evolve on a daily basis, there is an urgent need for a trustworthy evaluation method that can provide robust evaluation results in a timely fashion. Currently, as static benchmarks are prone to contamination concerns, users tend to trust human voting platforms, such as Chatbot Arena. However, human annotations require extensive manual efforts. To provide an automatic, robust, and trustworthy evaluation framework, we innovatively propose the Auto-Arena of LLMs, which automates the entire evaluation process with LLM agents. Firstly, an examiner LLM devises queries. Then, a pair of candidate LLMs engage in a multi-round peer-battle around the query, during which the LLM's true performance gaps become visible. Finally, a committee of LLM judges collectively discuss and determine the winner, which alleviates bias and promotes fairness. In our extensive experiment on the 17 newest LLMs, Auto-Arena shows the highest correlation with human preferences, providing a promising alternative to human evaluation platforms.
Lifelong Event Detection with Embedding Space Separation and Compaction
Apr 03, 2024



To mitigate forgetting, existing lifelong event detection methods typically maintain a memory module and replay the stored memory data during the learning of a new task. However, the simple combination of memory data and new-task samples can still result in substantial forgetting of previously acquired knowledge, which may occur due to the potential overlap between the feature distribution of new data and the previously learned embedding space. Moreover, the model suffers from overfitting on the few memory samples rather than effectively remembering learned patterns. To address the challenges of forgetting and overfitting, we propose a novel method based on embedding space separation and compaction. Our method alleviates forgetting of previously learned tasks by forcing the feature distribution of new data away from the previous embedding space. It also mitigates overfitting by a memory calibration mechanism that encourages memory data to be close to its prototype to enhance intra-class compactness. In addition, the learnable parameters of the new task are initialized by drawing upon acquired knowledge from the previously learned task to facilitate forward knowledge transfer. With extensive experiments, we demonstrate that our method can significantly outperform previous state-of-the-art approaches.
How Much are LLMs Contaminated? A Comprehensive Survey and the LLMSanitize Library
Mar 31, 2024With the rise of Large Language Models (LLMs) in recent years, new opportunities are emerging, but also new challenges, and contamination is quickly becoming critical. Business applications and fundraising in AI have reached a scale at which a few percentage points gained on popular question-answering benchmarks could translate into dozens of millions of dollars, placing high pressure on model integrity. At the same time, it is becoming harder and harder to keep track of the data that LLMs have seen; if not impossible with closed-source models like GPT-4 and Claude-3 not divulging any information on the training set. As a result, contamination becomes a critical issue: LLMs' performance may not be reliable anymore, as the high performance may be at least partly due to their previous exposure to the data. This limitation jeopardizes the entire progress in the field of NLP, yet, there remains a lack of methods on how to efficiently address contamination, or a clear consensus on prevention, mitigation and classification of contamination. In this paper, we survey all recent work on contamination with LLMs, and help the community track contamination levels of LLMs by releasing an open-source Python library named LLMSanitize implementing major contamination detection algorithms, which link is: https://github.com/ntunlp/LLMSanitize.
Data Augmentation using LLMs: Data Perspectives, Learning Paradigms and Challenges
Mar 05, 2024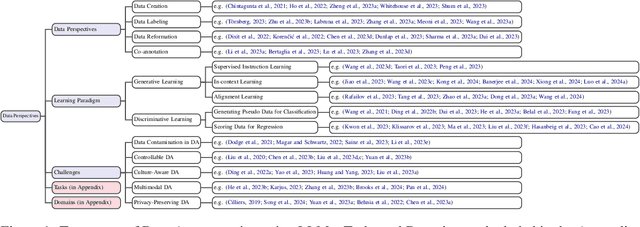
In the rapidly evolving field of machine learning (ML), data augmentation (DA) has emerged as a pivotal technique for enhancing model performance by diversifying training examples without the need for additional data collection. This survey explores the transformative impact of Large Language Models (LLMs) on DA, particularly addressing the unique challenges and opportunities they present in the context of natural language processing (NLP) and beyond. From a data perspective and a learning perspective, we examine various strategies that utilize Large Language Models for data augmentation, including a novel exploration of learning paradigms where LLM-generated data is used for further training. Additionally, this paper delineates the primary challenges faced in this domain, ranging from controllable data augmentation to multi modal data augmentation. This survey highlights the paradigm shift introduced by LLMs in DA, aims to serve as a foundational guide for researchers and practitioners in this field.