 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto Arena of LLMs: Automating LLM Evaluations with Agent Peer-battles and Committee Discussions
Paper and Code

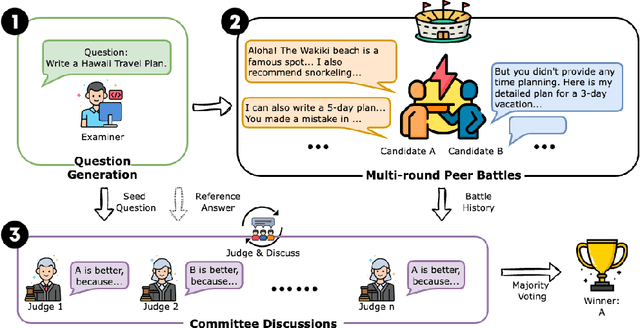
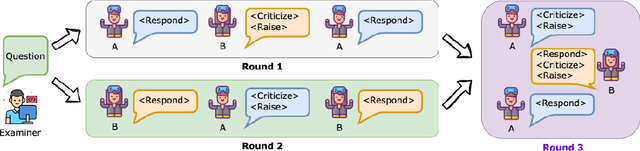
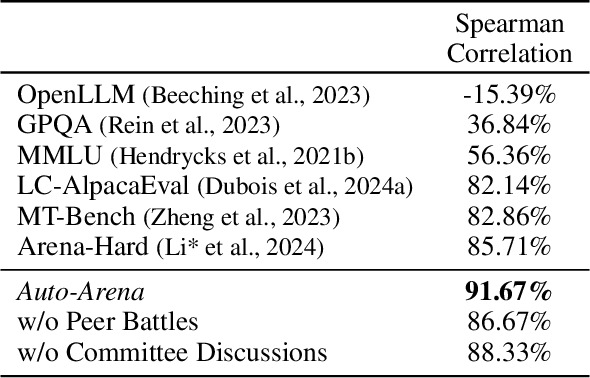
As LLMs evolve on a daily basis, there is an urgent need for a trustworthy evaluation method that can provide robust evaluation results in a timely fashion. Currently, as static benchmarks are prone to contamination concerns, users tend to trust human voting platforms, such as Chatbot Arena. However, human annotations require extensive manual efforts. To provide an automatic, robust, and trustworthy evaluation framework, we innovatively propose the Auto-Arena of LLMs, which automates the entire evaluation process with LLM agents. Firstly, an examiner LLM devises queries. Then, a pair of candidate LLMs engage in a multi-round peer-battle around the query, during which the LLM's true performance gaps become visible. Finally, a committee of LLM judges collectively discuss and determine the winner, which alleviates bias and promotes fairness. In our extensive experiment on the 17 newest LLMs, Auto-Arena shows the highest correlation with human preferences, providing a promising alternative to human evaluation platforms.