 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Open Discrete Audio Foundation Models with Interleaved Semantic, Acoustic, and Text Tokens
Feb 18, 2026Current audio language models are predominantly text-first, either extending pre-trained text LLM backbones or relying on semantic-only audio tokens, limiting general audio modeling. This paper presents a systematic empirical study of native audio foundation models that apply next-token prediction to audio at scale, jointly modeling semantic content, acoustic details, and text to support both general audio generation and cross-modal capabilities. We provide comprehensive empirical insights for building such models: (1) We systematically investigate design choices -- data sources, text mixture ratios, and token composition -- establishing a validated training recipe. (2) We conduct the first scaling law study for discrete audio models via IsoFLOP analysis on 64 models spanning $3{\times}10^{18}$ to $3{\times}10^{20}$ FLOPs, finding that optimal data grows 1.6$\times$ faster than optimal model size. (3) We apply these lessons to train SODA (Scaling Open Discrete Audio), a suite of models from 135M to 4B parameters on 500B tokens, comparing against our scaling predictions and existing models. SODA serves as a flexible backbone for diverse audio/text tasks -- we demonstrate this by fine-tuning for voice-preserving speech-to-speech translation, using the same unified architecture.
Typhoon ASR Real-time: FastConformer-Transducer for Thai Automatic Speech Recognition
Jan 19, 2026Large encoder-decoder models like Whisper achieve strong offline transcription but remain impractical for streaming applications due to high latency. However, due to the accessibility of pre-trained checkpoints, the open Thai ASR landscape remains dominated by these offline architectures, leaving a critical gap in efficient streaming solutions. We present Typhoon ASR Real-time, a 115M-parameter FastConformer-Transducer model for low-latency Thai speech recognition. We demonstrate that rigorous text normalization can match the impact of model scaling: our compact model achieves a 45x reduction in computational cost compared to Whisper Large-v3 while delivering comparable accuracy. Our normalization pipeline resolves systemic ambiguities in Thai transcription --including context-dependent number verbalization and repetition markers (mai yamok) --creating consistent training targets. We further introduce a two-stage curriculum learning approach for Isan (north-eastern) dialect adaptation that preserves Central Thai performance. To address reproducibility challenges in Thai ASR, we release the Typhoon ASR Benchmark, a gold-standard human-labeled datasets with transcriptions following established Thai linguistic conventions, providing standardized evaluation protocols for the research community.
Granular feedback merits sophisticated aggregation
Jul 16, 2025Human feedback is increasingly used across diverse applications like training AI models, developing recommender systems, and measuring public opinion -- with granular feedback often being preferred over binary feedback for its greater informativeness. While it is easy to accurately estimate a population's distribution of feedback given feedback from a large number of individuals, cost constraints typically necessitate using smaller groups. A simple method to approximate the population distribution is regularized averaging: compute the empirical distribution and regularize it toward a prior. Can we do better? As we will discuss, the answer to this question depends on feedback granularity. Suppose one wants to predict a population's distribution of feedback using feedback from a limited number of individuals. We show that, as feedback granularity increases, one can substantially improve upon predictions of regularized averaging by combining individuals' feedback in ways more sophisticated than regularized averaging. Our empirical analysis using questions on social attitudes confirms this pattern. In particular, with binary feedback, sophistication barely reduces the number of individuals required to attain a fixed level of performance. By contrast, with five-point feedback, sophisticated methods match the performance of regularized averaging with about half as many individuals.
Prior Prompt Engineering for Reinforcement Fine-Tuning
May 20, 2025This paper investigates prior prompt engineering (pPE) in the context of reinforcement fine-tuning (RFT), where language models (LMs) are incentivized to exhibit behaviors that maximize performance through reward signals. While existing RFT research has primarily focused on algorithms, reward shaping, and data curation, the design of the prior prompt--the instructions prepended to queries during training to elicit behaviors such as step-by-step reasoning--remains underexplored. We investigate whether different pPE approaches can guide LMs to internalize distinct behaviors after RFT. Inspired by inference-time prompt engineering (iPE), we translate five representative iPE strategies--reasoning, planning, code-based reasoning, knowledge recall, and null-example utilization--into corresponding pPE approaches. We experiment with Qwen2.5-7B using each of the pPE approaches, then evaluate performance on in-domain and out-of-domain benchmarks (e.g., AIME2024, HumanEval+, and GPQA-Diamond). Our results show that all pPE-trained models surpass their iPE-prompted counterparts, with the null-example pPE approach achieving the largest average performance gain and the highest improvement on AIME2024 and GPQA-Diamond, surpassing the commonly used reasoning approach. Furthermore, by adapting a behavior-classification framework, we demonstrate that different pPE strategies instill distinct behavioral styles in the resulting models. These findings position pPE as a powerful yet understudied axis for RFT.
Unlearning vs. Obfuscation: Are We Truly Removing Knowledge?
May 05, 2025Unlearning has emerged as a critical capability for large language models (LLMs) to support data privacy, regulatory compliance, and ethical AI deployment. Recent techniques often rely on obfuscation by injecting incorrect or irrelevant information to suppress knowledge. Such methods effectively constitute knowledge addition rather than true removal, often leaving models vulnerable to probing. In this paper, we formally distinguish unlearning from obfuscation and introduce a probing-based evaluation framework to assess whether existing approaches genuinely remove targeted information. Moreover, we propose DF-MCQ, a novel unlearning method that flattens the model predictive distribution over automatically generated multiple-choice questions using KL-divergence, effectively removing knowledge about target individuals and triggering appropriate refusal behaviour. Experimental results demonstrate that DF-MCQ achieves unlearning with over 90% refusal rate and a random choice-level uncertainty that is much higher than obfuscation on probing questions.
Assessing Thai Dialect Performance in LLMs with Automatic Benchmarks and Human Evaluation
Apr 08, 2025



Large language models show promising results in various NLP tasks. Despite these successes, the robustness and consistency of LLMs in underrepresented languages remain largely unexplored, especially concerning local dialects. Existing benchmarks also focus on main dialects, neglecting LLMs' ability on local dialect texts. In this paper, we introduce a Thai local dialect benchmark covering Northern (Lanna), Northeastern (Isan), and Southern (Dambro) Thai, evaluating LLMs on five NLP tasks: summarization, question answering, translation, conversation, and food-related tasks. Furthermore, we propose a human evaluation guideline and metric for Thai local dialects to assess generation fluency and dialect-specific accuracy. Results show that LLM performance declines significantly in local Thai dialects compared to standard Thai, with only proprietary models like GPT-4o and Gemini2 demonstrating some fluency
Towards Better Understanding of Program-of-Thought Reasoning in Cross-Lingual and Multilingual Environments
Feb 25, 2025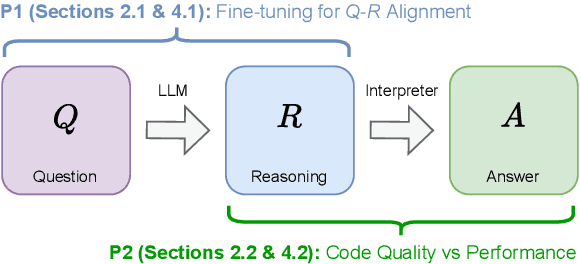

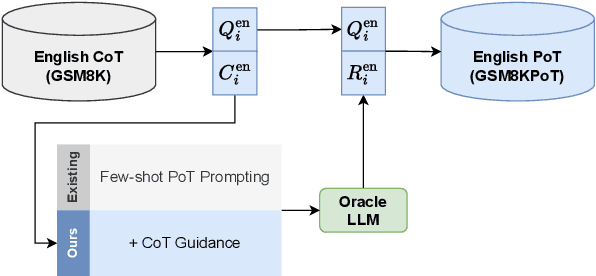

Multi-step reasoning is essential for large language models (LLMs), yet multilingual performance remains challenging. While Chain-of-Thought (CoT) prompting improves reasoning, it struggles with non-English languages due to the entanglement of reasoning and execution. Program-of-Thought (PoT) prompting separates reasoning from execution, offering a promising alternative but shifting the challenge to generating programs from non-English questions. We propose a framework to evaluate PoT by separating multilingual reasoning from code execution to examine (i) the impact of fine-tuning on question-reasoning alignment and (ii) how reasoning quality affects answer correctness. Our findings demonstrate that PoT fine-tuning substantially enhances multilingual reasoning, outperforming CoT fine-tuned models. We further demonstrate a strong correlation between reasoning quality (measured through code quality) and answer accuracy, highlighting its potential as a test-time performance improvement heuristic.
Mind the Gap! Static and Interactive Evaluations of Large Audio Models
Feb 21, 2025As AI chatbots become ubiquitous, voice interaction presents a compelling way to enable rapid, high-bandwidth communication for both semantic and social signals. This has driven research into Large Audio Models (LAMs) to power voice-native experiences. However, aligning LAM development with user goals requires a clear understanding of user needs and preferences to establish reliable progress metrics. This study addresses these challenges by introducing an interactive approach to evaluate LAMs and collecting 7,500 LAM interactions from 484 participants. Through topic modeling of user queries, we identify primary use cases for audio interfaces. We then analyze user preference rankings and qualitative feedback to determine which models best align with user needs. Finally, we evaluate how static benchmarks predict interactive performance - our analysis reveals no individual benchmark strongly correlates with interactive results ($\tau \leq 0.33$ for all benchmarks). While combining multiple coarse-grained features yields modest predictive power ($R^2$=$0.30$), only two out of twenty datasets on spoken question answering and age prediction show significantly positive correlations. This suggests a clear need to develop LAM evaluations that better correlate with user preferences.
An Open Recipe: Adapting Language-Specific LLMs to a Reasoning Model in One Day via Model Merging
Feb 13, 2025This paper investigates data selection and model merging methodologies aimed at incorporating advanced reasoning capabilities such as those of DeepSeek R1 into language-specific large language models (LLMs), with a particular focus on the Thai LLM. Our goal is to enhance the reasoning capabilities of language-specific LLMs while maintaining their target language abilities. DeepSeek R1 excels in reasoning but primarily benefits high-resource languages such as English and Chinese. However, low-resource languages remain underserved due to the dominance of English-centric training data and model optimizations, which limit performance in these languages. This limitation results in unreliable code-switching and diminished effectiveness on tasks in low-resource languages. Meanwhile, local and regional LLM initiatives have attempted to bridge this gap by developing language-specific LLMs that focus on improving local linguistic fidelity. We demonstrate that, with only publicly available datasets and a computational budget of $120, it is possible to enhance the reasoning capabilities of language-specific LLMs to match the level of DeepSeek R1, without compromising their performance on target language tasks.
Typhoon T1: An Open Thai Reasoning Model
Feb 13, 2025This paper introduces Typhoon T1, an open effort to develop an open Thai reasoning model. A reasoning model is a relatively new type of generative model built on top of large language models (LLMs). A reasoning model generates a long chain of thought before arriving at a final answer, an approach found to improve performance on complex tasks. However, details on developing such a model are limited, especially for reasoning models that can generate traces in a low-resource language. Typhoon T1 presents an open effort that dives into the details of developing a reasoning model in a more cost-effective way by leveraging supervised fine-tuning using open datasets, instead of reinforcement learning. This paper shares the details about synthetic data generation and training, as well as our dataset and model weights. Additionally, we provide insights gained from developing a reasoning model that generalizes across domains and is capable of generating reasoning traces in a low-resource language, using Thai as an example. We hope this open effort provides a foundation for further research in this field.