 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Uncertainty Prediction for Deep-Learning-based Particle Image Velocimetry
Jul 27, 2025Particle Image Velocimetry (PIV) is a widely used technique for flow measurement that traditionally relies on cross-correlation to track the displacement. Recent advances in deep learning-based methods have significantly improved the accuracy and efficiency of PIV measurements. However, despite its importance, reliable uncertainty quantification for deep learning-based PIV remains a critical and largely overlooked challenge. This paper explores three methods for quantifying uncertainty in deep learning-based PIV: the Uncertainty neural network (UNN), Multiple models (MM), and Multiple transforms (MT). We evaluate the three methods across multiple datasets. The results show that all three methods perform well under mild perturbations. Among the three evaluation metrics, the UNN method consistently achieves the best performance, providing accurate uncertainty estimates and demonstrating strong potential for uncertainty quantification in deep learning-based PIV. This study provides a comprehensive framework for uncertainty quantification in PIV, offering insights for future research and practical implementation.
PIV-FlowDiffuser:Transfer-learning-based denoising diffusion models for PIV
Apr 21, 2025Deep learning algorithms have significantly reduced the computational time and improved the spatial resolution of particle image velocimetry~(PIV). However, the models trained on synthetic datasets might have a degraded performance on practical particle images due to domain gaps. As a result, special residual patterns are often observed for the vector fields of deep learning-based estimators. To reduce the special noise step-by-step, we employ a denoising diffusion model~(FlowDiffuser) for PIV analysis. And the data-hungry iterative denoising diffusion model is trained via a transfer learning strategy, resulting in our PIV-FlowDiffuser method. Specifically, (1) pre-training a FlowDiffuser model with multiple optical flow datasets of the computer vision community, such as Sintel, KITTI, etc; (2) fine-tuning the pre-trained model on synthetic PIV datasets. Note that the PIV images are upsampled by a factor of two to resolve the small-scale turbulent flow structures. The visualized results indicate that our PIV-FlowDiffuser effectively suppresses the noise patterns. Therefore, the denoising diffusion model reduces the average end-point error~($AEE$) by 59.4% over RAFT256-PIV baseline on the classic Cai's dataset. Besides, PIV-FlowDiffuser exhibits enhanced generalization performance on unseen particle images due to transfer learning. Overall, this study highlights the transfer-learning-based denoising diffusion models for PIV. And a detailed implementation is recommended for interested readers in the repository https://github.com/Zhu-Qianyu/PIV-FlowDiffuser.
Risks and Opportunities of Open-Source Generative AI
May 14, 2024



Applications of Generative AI (Gen AI) are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about the potential risks of the technology, and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open-source generative AI. Using a three-stage framework for Gen AI development (near, mid and long-term), we analyze the risks and opportunities of open-source generative AI models with similar capabilities to the ones currently available (near to mid-term) and with greater capabilities (long-term). We argue that, overall, the benefits of open-source Gen AI outweigh its risks. As such, we encourage the open sourcing of models, training and evaluation data, and provide a set of recommendations and best practices for managing risks associated with open-source generative AI.
Surrogate-based cross-correlation for particle image velocimetry
Dec 10, 2021
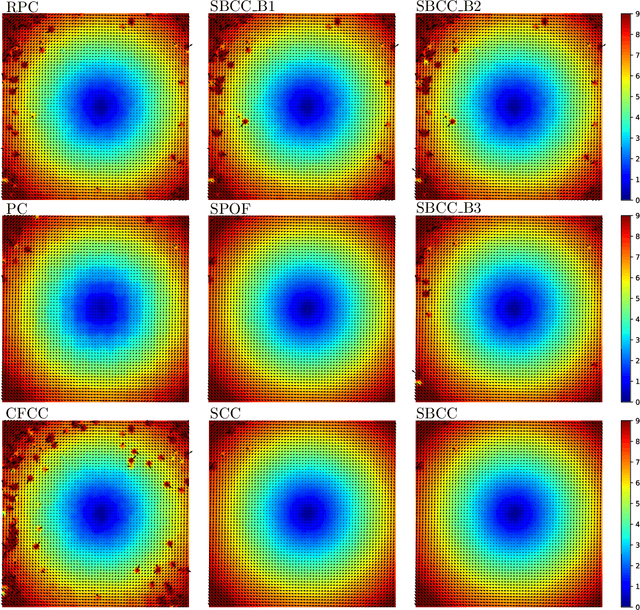
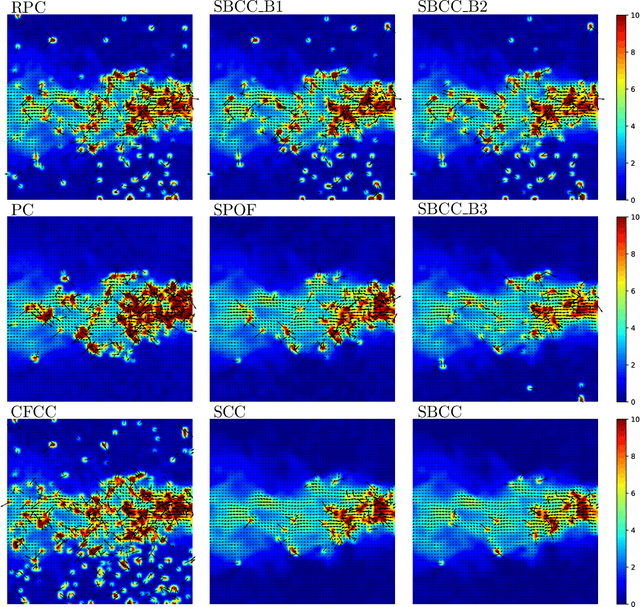
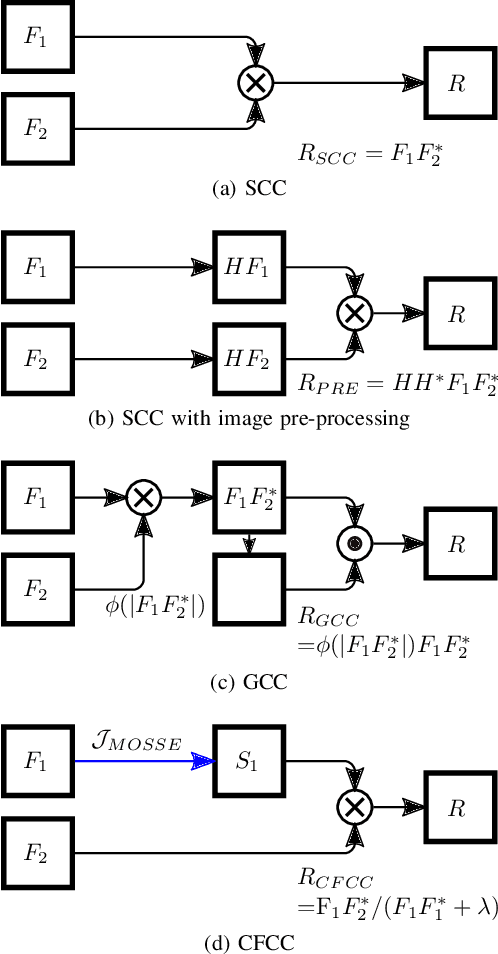
This paper presents a novel surrogate-based cross-correlation (SBCC) framework to improve the correlation performance between two image signals. The basic idea behind the SBCC is that an optimized surrogate filter/image, supplanting one original image, will produce a more robust and more accurate correlation signal. The cross-correlation estimation of the SBCC is formularized with an objective function composed of surrogate loss and correlation consistency loss. The closed-form solution provides an efficient estimation. To our surprise, the SBCC framework could provide an alternative view to explain a set of generalized cross-correlation (GCC) methods and comprehend the meaning of parameters. With the help of our SBCC framework, we further propose four new specific cross-correlation methods, and provide some suggestions for improving existing GCC methods. A noticeable fact is that the SBCC could enhance the correlation robustness by incorporating other negative context images. Considering the sub-pixel accuracy and robustness requirement of particle image velocimetry (PIV), the contribution of each term in the objective function is investigated with particles' images. Compared with the state-of-the-art baseline methods, the SBCC methods exhibit improved performance (accuracy and robustness) on the synthetic dataset and several challenging real experimental PIV cases.
Diffeomorphic Particle Image Velocimetry
Aug 17, 2021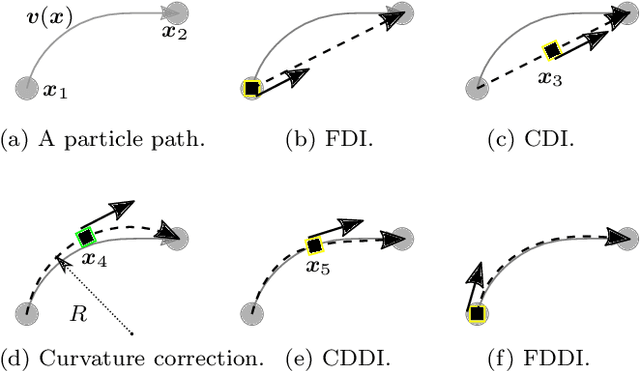
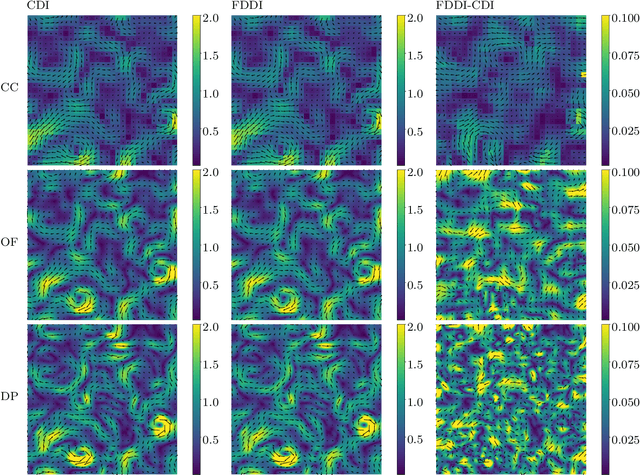
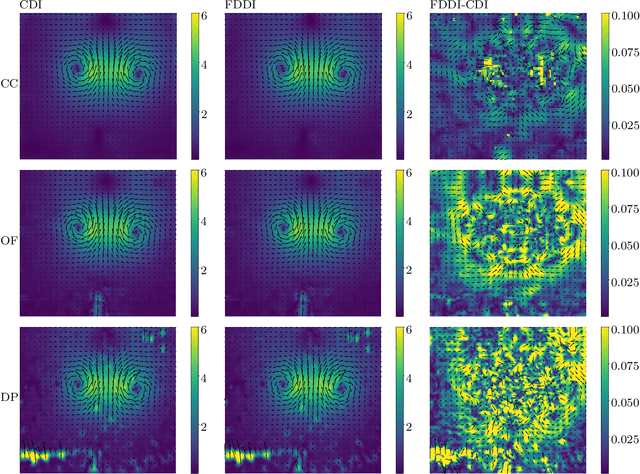
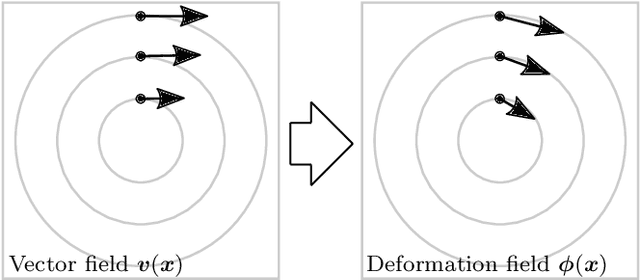
The existing particle image velocimetry (PIV) do not consider the curvature effect of the non-straight particle trajectory, because it seems to be impossible to obtain the curvature information from a pair of particle images. As a result, the computed vector underestimates the real velocity due to the straight-line approximation, that further causes a systematic error for the PIV instrument. In this work, the particle curved trajectory between two recordings is firstly explained with the streamline segment of a steady flow (diffeomorphic transformation) instead of a single vector, and this idea is termed as diffeomorphic PIV. Specifically, a deformation field is introduced to describe the particle displacement, i.e., we try to find the optimal velocity field, of which the corresponding deformation vector field agrees with the particle displacement. Because the variation of the deformation function can be approximated with the variation of the velocity function, the diffeomorphic PIV can be implemented as iterative PIV. That says, the diffeomorphic PIV warps the images with deformation vector field instead of the velocity, and keeps the rest as same as iterative PIVs. Two diffeomorphic deformation schemes -- forward diffeomorphic deformation interrogation (FDDI) and central diffeomorphic deformation interrogation (CDDI) -- are proposed. Tested on synthetic images, the FDDI achieves significant accuracy improvement across different one-pass displacement estimators (cross-correlation, optical flow, deep learning flow). Besides, the results on three real PIV image pairs demonstrate the non-negligible curvature effect for CDI-based PIV, and our FDDI provides larger velocity estimation (more accurate) in the fast curvy streamline areas. The accuracy improvement of the combination of FDDI and accurate dense estimator means that our diffeomorphic PIV paves a new way for complex flow measurement.
Multi-Modal Mutual Information (MuMMI) Training for Robust Self-Supervised Deep Reinforcement Learning
Jul 06, 2021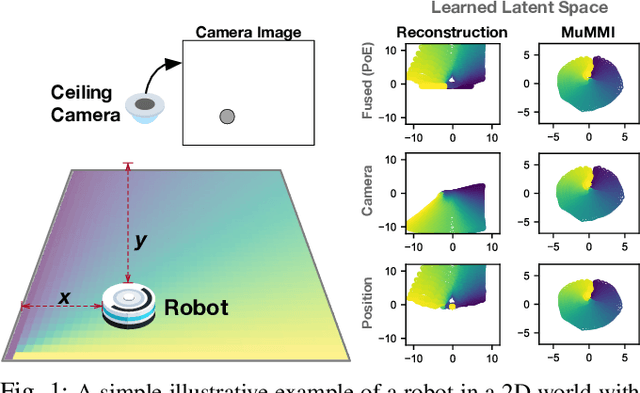
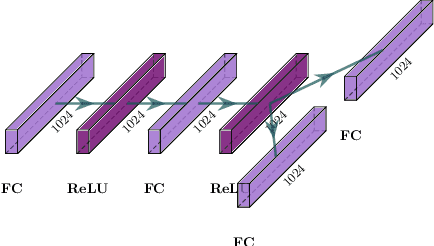
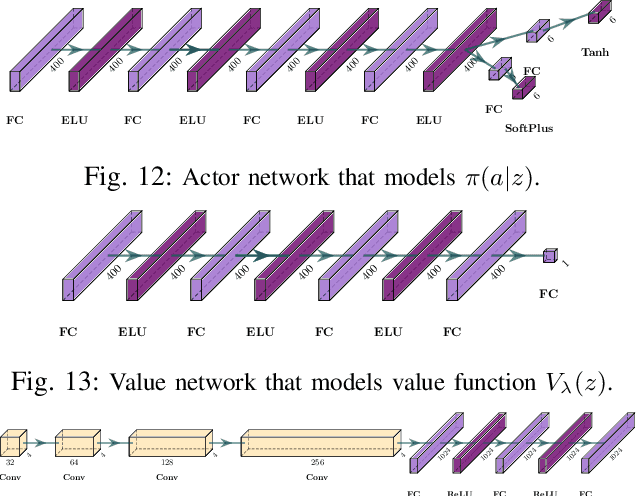
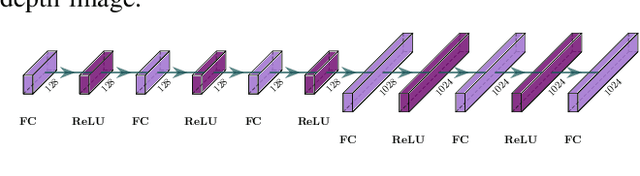
This work focuses on learning useful and robust deep world models using multiple, possibly unreliable, sensors. We find that current methods do not sufficiently encourage a shared representation between modalities; this can cause poor performance on downstream tasks and over-reliance on specific sensors. As a solution, we contribute a new multi-modal deep latent state-space model, trained using a mutual information lower-bound. The key innovation is a specially-designed density ratio estimator that encourages consistency between the latent codes of each modality. We tasked our method to learn policies (in a self-supervised manner) on multi-modal Natural MuJoCo benchmarks and a challenging Table Wiping task. Experiments show our method significantly outperforms state-of-the-art deep reinforcement learning methods, particularly in the presence of missing observations.
Blind Inverse Gamma Correction with Maximized Differential Entropy
Jul 05, 2020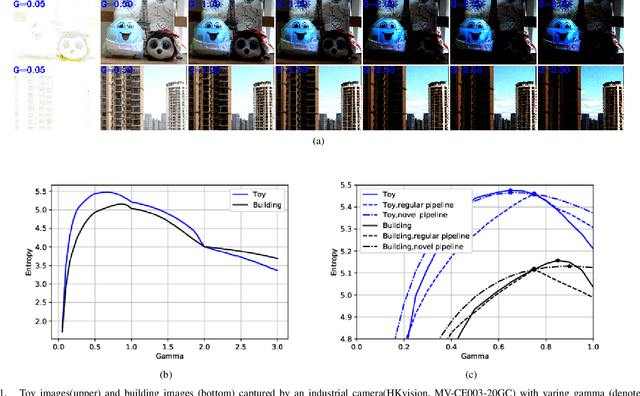
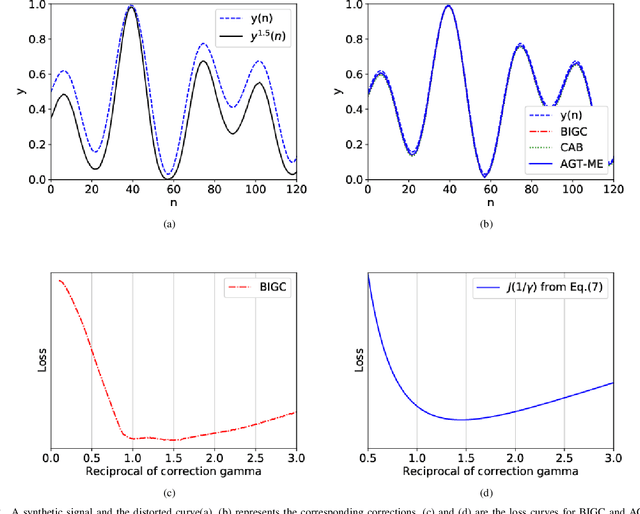

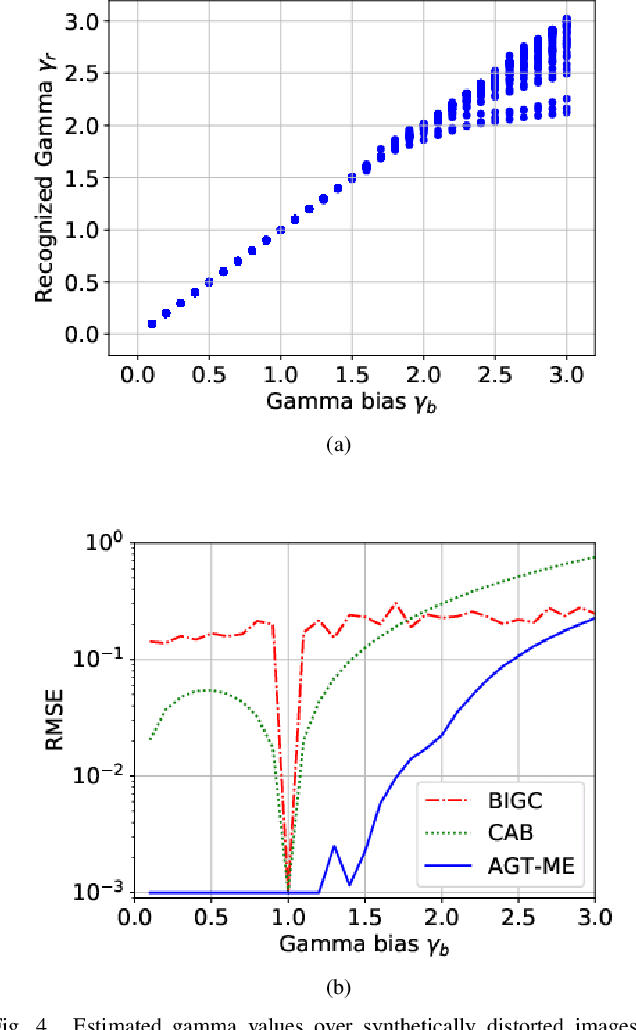
Unwanted nonlinear gamma distortion frequently occurs in a great diversity of images during the procedures of image acquisition, processing, and/or display. And the gamma distortion often varies with capture setup change and luminance variation. Blind inverse gamma correction, which automatically determines a proper restoration gamma value from a given image, is of paramount importance to attenuate the distortion. For blind inverse gamma correction, an adaptive gamma transformation method (AGT-ME) is proposed directly from a maximized differential entropy model. And the corresponding optimization has a mathematical concise closed-form solution, resulting in efficient implementation and accurate gamma restoration of AGT-ME. Considering the human eye has a non-linear perception sensitivity, a modified version AGT-ME-VISUAL is also proposed to achieve better visual performance. Tested on variable datasets, AGT-ME could obtain an accurate estimation of a large range of gamma distortion (0.1 to 3.0), outperforming the state-of-the-art methods. Besides, the proposed AGT-ME and AGT-ME-VISUAL were applied to three typical applications, including automatic gamma adjustment, natural/medical image contrast enhancement, and fringe projection profilometry image restoration. Furthermore, the AGT-ME/ AGT-ME-VISUAL is general and can be seamlessly extended to the masked image, multi-channel (color or spectrum) image, or multi-frame video, and free of the arbitrary tuning parameter. Besides, the corresponding Python code (https://github.com/yongleex/AGT-ME) is also provided for interested users.