 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee Different, Think Better: Visual Variations Mitigating Hallucinations in LVLMs
Jul 30, 2025Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in visual understanding and multimodal reasoning. However, LVLMs frequently exhibit hallucination phenomena, manifesting as the generated textual responses that demonstrate inconsistencies with the provided visual content. Existing hallucination mitigation methods are predominantly text-centric, the challenges of visual-semantic alignment significantly limit their effectiveness, especially when confronted with fine-grained visual understanding scenarios. To this end, this paper presents ViHallu, a Vision-Centric Hallucination mitigation framework that enhances visual-semantic alignment through Visual Variation Image Generation and Visual Instruction Construction. ViHallu introduces visual variation images with controllable visual alterations while maintaining the overall image structure. These images, combined with carefully constructed visual instructions, enable LVLMs to better understand fine-grained visual content through fine-tuning, allowing models to more precisely capture the correspondence between visual content and text, thereby enhancing visual-semantic alignment. Extensive experiments on multiple benchmarks show that ViHallu effectively enhances models' fine-grained visual understanding while significantly reducing hallucination tendencies. Furthermore, we release ViHallu-Instruction, a visual instruction dataset specifically designed for hallucination mitigation and visual-semantic alignment. Code is available at https://github.com/oliviadzy/ViHallu.
* Accepted by ACM MM25
MathMistake Checker: A Comprehensive Demonstration for Step-by-Step Math Problem Mistake Finding by Prompt-Guided LLMs
Mar 06, 2025We propose a novel system, MathMistake Checker, designed to automate step-by-step mistake finding in mathematical problems with lengthy answers through a two-stage process. The system aims to simplify grading, increase efficiency, and enhance learning experiences from a pedagogical perspective. It integrates advanced technologies, including computer vision and the chain-of-thought capabilities of the latest large language models (LLMs). Our system supports open-ended grading without reference answers and promotes personalized learning by providing targeted feedback. We demonstrate its effectiveness across various types of math problems, such as calculation and word problems.
Rethinking Masked Language Modeling for Chinese Spelling Correction
May 28, 2023In this paper, we study Chinese Spelling Correction (CSC) as a joint decision made by two separate models: a language model and an error model. Through empirical analysis, we find that fine-tuning BERT tends to over-fit the error model while under-fit the language model, resulting in poor generalization to out-of-distribution error patterns. Given that BERT is the backbone of most CSC models, this phenomenon has a significant negative impact. To address this issue, we are releasing a multi-domain benchmark LEMON, with higher quality and diversity than existing benchmarks, to allow a comprehensive assessment of the open domain generalization of CSC models. Then, we demonstrate that a very simple strategy, randomly masking 20\% non-error tokens from the input sequence during fine-tuning is sufficient for learning a much better language model without sacrificing the error model. This technique can be applied to any model architecture and achieves new state-of-the-art results on SIGHAN, ECSpell, and LEMON.
Blind Inverse Gamma Correction with Maximized Differential Entropy
Jul 05, 2020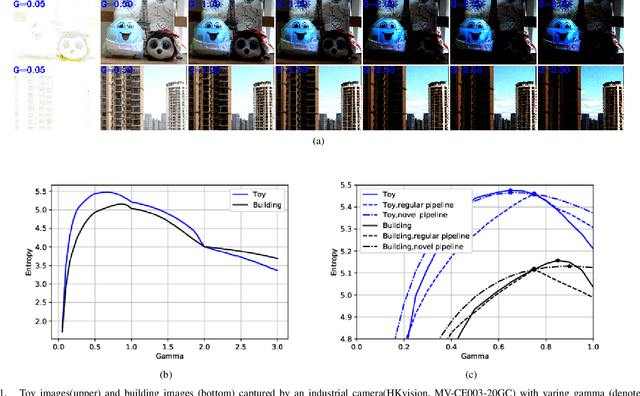
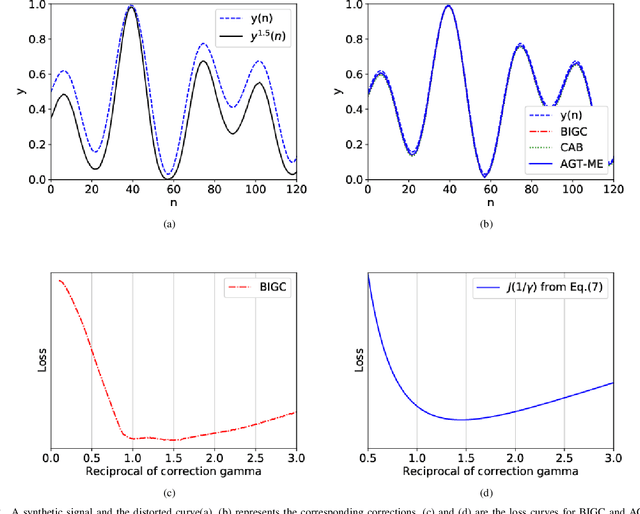

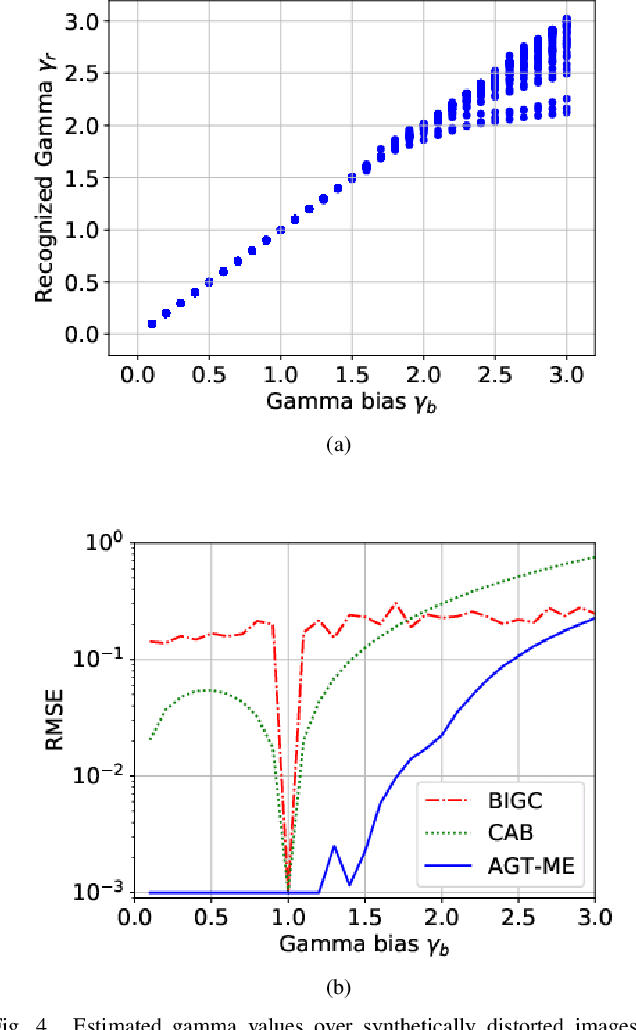
Unwanted nonlinear gamma distortion frequently occurs in a great diversity of images during the procedures of image acquisition, processing, and/or display. And the gamma distortion often varies with capture setup change and luminance variation. Blind inverse gamma correction, which automatically determines a proper restoration gamma value from a given image, is of paramount importance to attenuate the distortion. For blind inverse gamma correction, an adaptive gamma transformation method (AGT-ME) is proposed directly from a maximized differential entropy model. And the corresponding optimization has a mathematical concise closed-form solution, resulting in efficient implementation and accurate gamma restoration of AGT-ME. Considering the human eye has a non-linear perception sensitivity, a modified version AGT-ME-VISUAL is also proposed to achieve better visual performance. Tested on variable datasets, AGT-ME could obtain an accurate estimation of a large range of gamma distortion (0.1 to 3.0), outperforming the state-of-the-art methods. Besides, the proposed AGT-ME and AGT-ME-VISUAL were applied to three typical applications, including automatic gamma adjustment, natural/medical image contrast enhancement, and fringe projection profilometry image restoration. Furthermore, the AGT-ME/ AGT-ME-VISUAL is general and can be seamlessly extended to the masked image, multi-channel (color or spectrum) image, or multi-frame video, and free of the arbitrary tuning parameter. Besides, the corresponding Python code (https://github.com/yongleex/AGT-ME) is also provided for interested users.
Spelling Error Correction with Soft-Masked BERT
May 15, 2020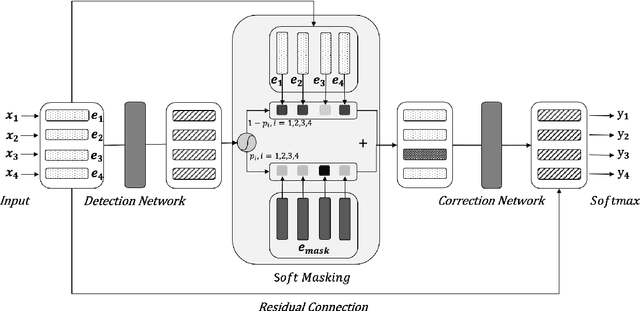
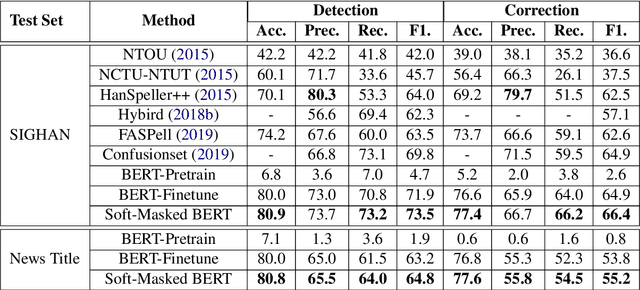
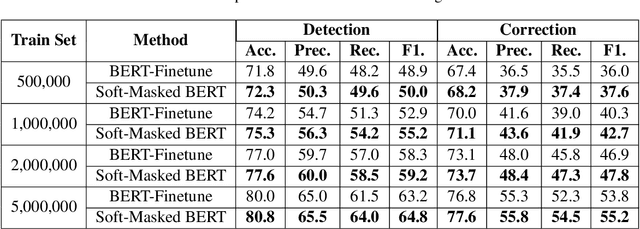
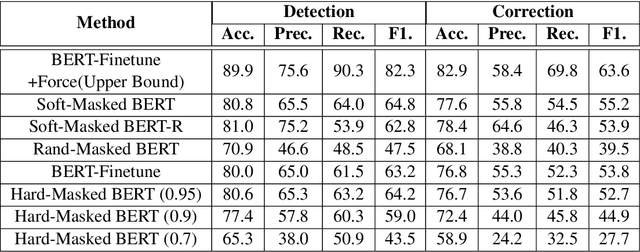
Spelling error correction is an important yet challenging task because a satisfactory solution of it essentially needs human-level language understanding ability. Without loss of generality we consider Chinese spelling error correction (CSC) in this paper. A state-of-the-art method for the task selects a character from a list of candidates for correction (including non-correction) at each position of the sentence on the basis of BERT, the language representation model. The accuracy of the method can be sub-optimal, however, because BERT does not have sufficient capability to detect whether there is an error at each position, apparently due to the way of pre-training it using mask language modeling. In this work, we propose a novel neural architecture to address the aforementioned issue, which consists of a network for error detection and a network for error correction based on BERT, with the former being connected to the latter with what we call soft-masking technique. Our method of using `Soft-Masked BERT' is general, and it may be employed in other language detection-correction problems. Experimental results on two datasets demonstrate that the performance of our proposed method is significantly better than the baselines including the one solely based on BERT.