 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Language-Action Model for Unified World Modeling, Language Reasoning, and Action Synthesis
Jun 04, 2026We propose world-language-action (WLA) models as a new class of embodied foundation models. WLA takes textual instructions, images, and robot states as inputs to jointly predict textual subtasks, subgoal images, and robot actions, conjoining the \emph{world modeling interface} to learn from extensive egocentric videos as in the world-action model (WAM) and the \emph{language reasoning} capacities to solve complex long-horizon tasks as in vision-language-action (VLA) models. At the core of WLA lies an \emph{autoregressive (AR)} Transformer backbone, instead of a bidirectional diffusion Transformer as in WAMs, to predict the \emph{next state}, comprising the \emph{semantic-level} textual intention and complementary \emph{fine-grained} physical dynamics. The physical dynamics are supervised by the world modeling objective based on a dedicated World Expert, and are leveraged to ease the characterization of the state-action correlation for the Action Expert. WLA leverages meta-queries to make the world prediction \emph{implicitly} impact the action generation so that the former can be disabled during inference. The world prediction can also be activated to enable test-time scaling for improved robot control. Our WLA-0 prototype, with 2B active parameters, achieves 40 ms per inference on an NVIDIA RTX 5090. Evaluations across simulated and real-world environments demonstrate that WLA-0 achieves state-of-the-art multi-task and long-horizon learning abilities, e.g., 92.94\% success rate on RoboTwin2.0 Clean and 56.5\% success rate on RMBench. WLA-0 also holds the promise to learn novel tasks directly from \emph{cross-embodiment robot videos} without action annotations.
SACRED: A Faithful Annotated Multimedia Multimodal Multilingual Dataset for Classifying Connectedness Types in Online Spirituality
Mar 28, 2026In religion and theology studies, spirituality has garnered significant research attention for the reason that it not only transcends culture but offers unique experience to each individual. However, social scientists often rely on limited datasets, which are basically unavailable online. In this study, we collaborated with social scientists to develop a high-quality multimedia multi-modal datasets, \textbf{SACRED}, in which the faithfulness of classification is guaranteed. Using \textbf{SACRED}, we evaluated the performance of 13 popular LLMs as well as traditional rule-based and fine-tuned approaches. The result suggests DeepSeek-V3 model performs well in classifying such abstract concepts (i.e., 79.19\% accuracy in the Quora test set), and the GPT-4o-mini model surpassed the other models in the vision tasks (63.99\% F1 score). Purportedly, this is the first annotated multi-modal dataset from online spirituality communication. Our study also found a new type of connectedness which is valuable for communication science studies.
A Deployable Bio-inspired Compliant Leg Design for Enhanced Leaping in Quadruped Robots
Mar 01, 2026Quadruped robots are becoming increasingly essential for various applications, including industrial inspection and catastrophe search and rescue. These scenarios require robots to possess enhanced agility and obstacle-navigation skills. Nonetheless, the performance of current platforms is often constrained by insufficient peak motor power, limiting their ability to perform explosive jumps. To address this challenge, this paper proposes a bio-inspired method that emulates the energy-storage mechanism found in froghopper legs. We designed a Deployable Compliant Leg (DCL) utilizing a specialized 3D-printed elastic material, Polyether block amide (PEBA), featuring a lightweight internal lattice structure. This structure functions analogously to biological tendons, storing elastic energy during the robot's squatting phase and rapidly releasing it to augment motor output during the leap. The proposed mechanical design significantly enhances the robot's vertical jumping capability. Through finite element analysis (FEA) and experimental validation, we demonstrate a relative performance improvement of 17.1% in vertical jumping height.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Sampling Strategy Design for Model Predictive Path Integral Control on Legged Robot Locomotion
Jan 04, 2026Model Predictive Path Integral (MPPI) control has emerged as a powerful sampling-based optimal control method for complex, nonlinear, and high-dimensional systems. However, directly applying MPPI to legged robotic systems presents several challenges. This paper systematically investigates the role of sampling strategy design within the MPPI framework for legged robot locomotion. Based upon the idea of structured control parameterization, we explore and compare multiple sampling strategies within the framework, including both unstructured and spline-based approaches. Through extensive simulations on a quadruped robot platform, we evaluate how different sampling strategies affect control smoothness, task performance, robustness, and sample efficiency. The results provide new insights into the practical implications of sampling design for deploying MPPI on complex legged systems.
LibContinual: A Comprehensive Library towards Realistic Continual Learning
Dec 26, 2025A fundamental challenge in Continual Learning (CL) is catastrophic forgetting, where adapting to new tasks degrades the performance on previous ones. While the field has evolved with diverse methods, this rapid surge in diverse methodologies has culminated in a fragmented research landscape. The lack of a unified framework, including inconsistent implementations, conflicting dependencies, and varying evaluation protocols, makes fair comparison and reproducible research increasingly difficult. To address this challenge, we propose LibContinual, a comprehensive and reproducible library designed to serve as a foundational platform for realistic CL. Built upon a high-cohesion, low-coupling modular architecture, LibContinual integrates 19 representative algorithms across five major methodological categories, providing a standardized execution environment. Meanwhile, leveraging this unified framework, we systematically identify and investigate three implicit assumptions prevalent in mainstream evaluation: (1) offline data accessibility, (2) unregulated memory resources, and (3) intra-task semantic homogeneity. We argue that these assumptions often overestimate the real-world applicability of CL methods. Through our comprehensive analysis using strict online CL settings, a novel unified memory budget protocol, and a proposed category-randomized setting, we reveal significant performance drops in many representative CL methods when subjected to these real-world constraints. Our study underscores the necessity of resource-aware and semantically robust CL strategies, and offers LibContinual as a foundational toolkit for future research in realistic continual learning. The source code is available from \href{https://github.com/RL-VIG/LibContinual}{https://github.com/RL-VIG/LibContinual}.
SDialog: A Python Toolkit for End-to-End Agent Building, User Simulation, Dialog Generation, and Evaluation
Dec 12, 2025We present SDialog, an MIT-licensed open-source Python toolkit that unifies dialog generation, evaluation and mechanistic interpretability into a single end-to-end framework for building and analyzing LLM-based conversational agents. Built around a standardized \texttt{Dialog} representation, SDialog provides: (1) persona-driven multi-agent simulation with composable orchestration for controlled, synthetic dialog generation, (2) comprehensive evaluation combining linguistic metrics, LLM-as-a-judge and functional correctness validators, (3) mechanistic interpretability tools for activation inspection and steering via feature ablation and induction, and (4) audio generation with full acoustic simulation including 3D room modeling and microphone effects. The toolkit integrates with all major LLM backends, enabling mixed-backend experiments under a unified API. By coupling generation, evaluation, and interpretability in a dialog-centric architecture, SDialog enables researchers to build, benchmark and understand conversational systems more systematically.
Latency Minimization for Multi-AAV-Enabled ISCC Systems with Movable Antenna
Aug 07, 2025This paper investigates an autonomous aerial vehicle (AAV)-enabled integrated sensing, communication, and computation system, with a particular focus on integrating movable antennas (MAs) into the system for enhancing overall system performance. Specifically, multiple MA-enabled AVVs perform sensing tasks and simultaneously transmit the generated computational tasks to the base station for processing. To minimize the maximum latency under the sensing and resource constraints, we formulate an optimization problem that jointly coordinates the position of the MAs, the computation resource allocation, and the transmit beamforming. Due to the non-convexity of the objective function and strong coupling among variables, we propose a two-layer iterative algorithm leveraging particle swarm optimization and convex optimization to address it. The simulation results demonstrate that the proposed scheme achieves significant latency improvements compared to the baseline schemes.
Full-Duplex ISCC for Low-Altitude Networks: Resource Allocation and Coordinated Beamforming
Apr 25, 2025This paper investigates an integrated sensing, communication, and computing system deployed over low-altitude networks for enabling applications within the low-altitude economy. In the considered system, a full-duplex enabled unmanned aerial vehicle (UAV) is dispatched in the airspace, functioning as a UAV-enabled low-altitude platform (ULAP). The ULAP is capable of achieving simultaneous information transmission, target sensing, and mobile edge computing services. To reduce the overall energy consumption of the system while meeting the sensing beampattern threshold and user computation requirements, we formulate an energy consumption minimization problem by jointly optimizing the task allocation, computation resource allocation, transmit beamforming, and receive beamforming. Since the problem is non-convex and involves highly coupled variables, we propose an efficient algorithm based on alternation optimization, which decomposes the original problem into tractable convex subproblems. Moreover, we analyze the convergence and complexity of the proposed algorithm. Numerical results demonstrate that the proposed scheme saves up to 54.12\% energy consumption performance compared to the benchmark schemes.
SG-NeRF: Neural Surface Reconstruction with Scene Graph Optimization
Jul 17, 2024
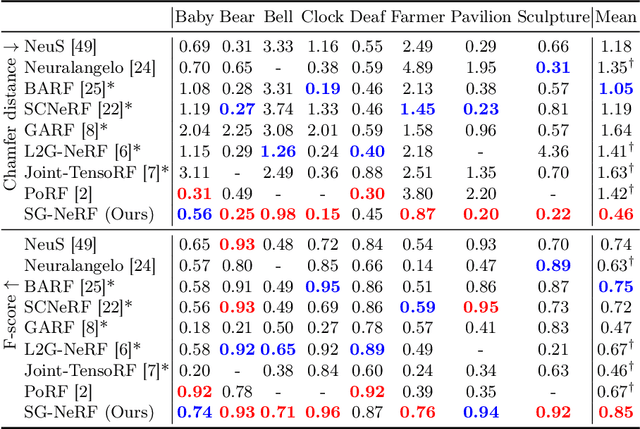


3D surface reconstruction from images is essential for numerous applications. Recently, Neural Radiance Fields (NeRFs) have emerged as a promising framework for 3D modeling. However, NeRFs require accurate camera poses as input, and existing methods struggle to handle significantly noisy pose estimates (i.e., outliers), which are commonly encountered in real-world scenarios. To tackle this challenge, we present a novel approach that optimizes radiance fields with scene graphs to mitigate the influence of outlier poses. Our method incorporates an adaptive inlier-outlier confidence estimation scheme based on scene graphs, emphasizing images of high compatibility with the neighborhood and consistency in the rendering quality. We also introduce an effective intersection-over-union (IoU) loss to optimize the camera pose and surface geometry, together with a coarse-to-fine strategy to facilitate the training. Furthermore, we propose a new dataset containing typical outlier poses for a detailed evaluation. Experimental results on various datasets consistently demonstrate the effectiveness and superiority of our method over existing approaches, showcasing its robustness in handling outliers and producing high-quality 3D reconstructions. Our code and data are available at: \url{https://github.com/Iris-cyy/SG-NeRF}.