 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Geometry-Enhanced Parameter-Efficient Fine-Tuning for 3D Scene Segmentation
May 28, 2025The emergence of large-scale pre-trained point cloud models has significantly advanced 3D scene understanding, but adapting these models to specific downstream tasks typically demands full fine-tuning, incurring high computational and storage costs. Parameter-efficient fine-tuning (PEFT) techniques, successful in natural language processing and 2D vision tasks, would underperform when naively applied to 3D point cloud models due to significant geometric and spatial distribution shifts. Existing PEFT methods commonly treat points as orderless tokens, neglecting important local spatial structures and global geometric contexts in 3D modeling. To bridge this gap, we introduce the Geometric Encoding Mixer (GEM), a novel geometry-aware PEFT module specifically designed for 3D point cloud transformers. GEM explicitly integrates fine-grained local positional encodings with a lightweight latent attention mechanism to capture comprehensive global context, thereby effectively addressing the spatial and geometric distribution mismatch. Extensive experiments demonstrate that GEM achieves performance comparable to or sometimes even exceeding full fine-tuning, while only updating 1.6% of the model's parameters, fewer than other PEFT methods. With significantly reduced training time and memory requirements, our approach thus sets a new benchmark for efficient, scalable, and geometry-aware fine-tuning of large-scale 3D point cloud models. Code will be released.
Towards Modality-agnostic Label-efficient Segmentation with Entropy-Regularized Distribution Alignment
Aug 29, 2024



Label-efficient segmentation aims to perform effective segmentation on input data using only sparse and limited ground-truth labels for training. This topic is widely studied in 3D point cloud segmentation due to the difficulty of annotating point clouds densely, while it is also essential for cost-effective segmentation on 2D images. Until recently, pseudo-labels have been widely employed to facilitate training with limited ground-truth labels, and promising progress has been witnessed in both the 2D and 3D segmentation. However, existing pseudo-labeling approaches could suffer heavily from the noises and variations in unlabelled data, which would result in significant discrepancies between generated pseudo-labels and current model predictions during training. We analyze that this can further confuse and affect the model learning process, which shows to be a shared problem in label-efficient learning across both 2D and 3D modalities. To address this issue, we propose a novel learning strategy to regularize the pseudo-labels generated for training, thus effectively narrowing the gaps between pseudo-labels and model predictions. More specifically, our method introduces an Entropy Regularization loss and a Distribution Alignment loss for label-efficient learning, resulting in an ERDA learning strategy. Interestingly, by using KL distance to formulate the distribution alignment loss, ERDA reduces to a deceptively simple cross-entropy-based loss which optimizes both the pseudo-label generation module and the segmentation model simultaneously. In addition, we innovate in the pseudo-label generation to make our ERDA consistently effective across both 2D and 3D data modalities for segmentation. Enjoying simplicity and more modality-agnostic pseudo-label generation, our method has shown outstanding performance in fully utilizing all unlabeled data points for training across ...
Cross-modal & Cross-domain Learning for Unsupervised LiDAR Semantic Segmentation
Aug 05, 2023In recent years, cross-modal domain adaptation has been studied on the paired 2D image and 3D LiDAR data to ease the labeling costs for 3D LiDAR semantic segmentation (3DLSS) in the target domain. However, in such a setting the paired 2D and 3D data in the source domain are still collected with additional effort. Since the 2D-3D projections can enable the 3D model to learn semantic information from the 2D counterpart, we ask whether we could further remove the need of source 3D data and only rely on the source 2D images. To answer it, this paper studies a new 3DLSS setting where a 2D dataset (source) with semantic annotations and a paired but unannotated 2D image and 3D LiDAR data (target) are available. To achieve 3DLSS in this scenario, we propose Cross-Modal and Cross-Domain Learning (CoMoDaL). Specifically, our CoMoDaL aims at modeling 1) inter-modal cross-domain distillation between the unpaired source 2D image and target 3D LiDAR data, and 2) the intra-domain cross-modal guidance between the target 2D image and 3D LiDAR data pair. In CoMoDaL, we propose to apply several constraints, such as point-to-pixel and prototype-to-pixel alignments, to associate the semantics in different modalities and domains by constructing mixed samples in two modalities. The experimental results on several datasets show that in the proposed setting, the developed CoMoDaL can achieve segmentation without the supervision of labeled LiDAR data. Ablations are also conducted to provide more analysis. Code will be available publicly.
All Points Matter: Entropy-Regularized Distribution Alignment for Weakly-supervised 3D Segmentation
May 25, 2023Pseudo-labels are widely employed in weakly supervised 3D segmentation tasks where only sparse ground-truth labels are available for learning. Existing methods often rely on empirical label selection strategies, such as confidence thresholding, to generate beneficial pseudo-labels for model training. This approach may, however, hinder the comprehensive exploitation of unlabeled data points. We hypothesize that this selective usage arises from the noise in pseudo-labels generated on unlabeled data. The noise in pseudo-labels may result in significant discrepancies between pseudo-labels and model predictions, thus confusing and affecting the model training greatly. To address this issue, we propose a novel learning strategy to regularize the generated pseudo-labels and effectively narrow the gaps between pseudo-labels and model predictions. More specifically, our method introduces an Entropy Regularization loss and a Distribution Alignment loss for weakly supervised learning in 3D segmentation tasks, resulting in an ERDA learning strategy. Interestingly, by using KL distance to formulate the distribution alignment loss, it reduces to a deceptively simple cross-entropy-based loss which optimizes both the pseudo-label generation network and the 3D segmentation network simultaneously. Despite the simplicity, our method promisingly improves the performance. We validate the effectiveness through extensive experiments on various baselines and large-scale datasets. Results show that ERDA effectively enables the effective usage of all unlabeled data points for learning and achieves state-of-the-art performance under different settings. Remarkably, our method can outperform fully-supervised baselines using only 1% of true annotations. Code and model will be made publicly available.
Contrastive Boundary Learning for Point Cloud Segmentation
Mar 11, 2022
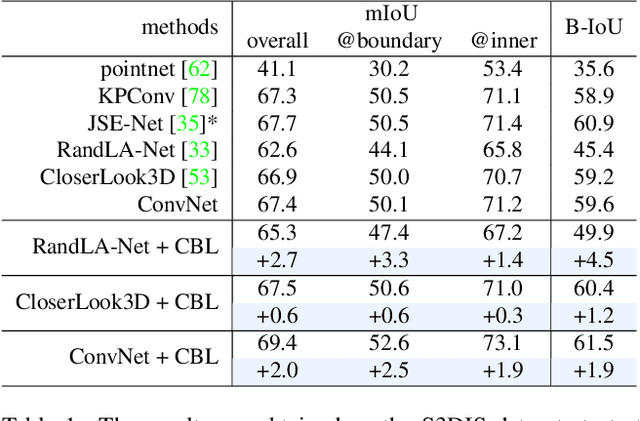

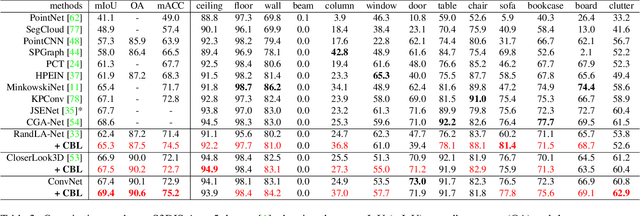
Point cloud segmentation is fundamental in understanding 3D environments. However, current 3D point cloud segmentation methods usually perform poorly on scene boundaries, which degenerates the overall segmentation performance. In this paper, we focus on the segmentation of scene boundaries. Accordingly, we first explore metrics to evaluate the segmentation performance on scene boundaries. To address the unsatisfactory performance on boundaries, we then propose a novel contrastive boundary learning (CBL) framework for point cloud segmentation. Specifically, the proposed CBL enhances feature discrimination between points across boundaries by contrasting their representations with the assistance of scene contexts at multiple scales. By applying CBL on three different baseline methods, we experimentally show that CBL consistently improves different baselines and assists them to achieve compelling performance on boundaries, as well as the overall performance, eg in mIoU. The experimental results demonstrate the effectiveness of our method and the importance of boundaries for 3D point cloud segmentation. Code and model will be made publicly available at https://github.com/LiyaoTang/contrastBoundary.