 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtDAT: A Unified Framework for Protein Sequence Design from Any Protein Text Description
Dec 05, 2024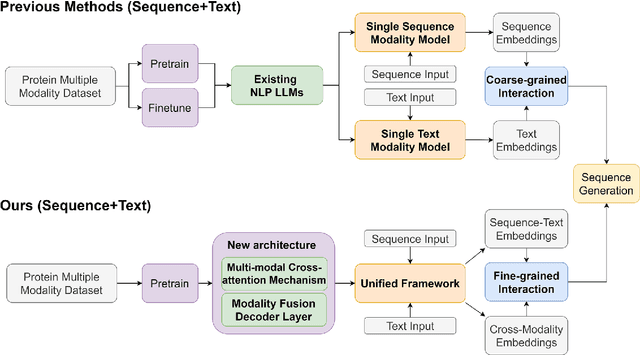
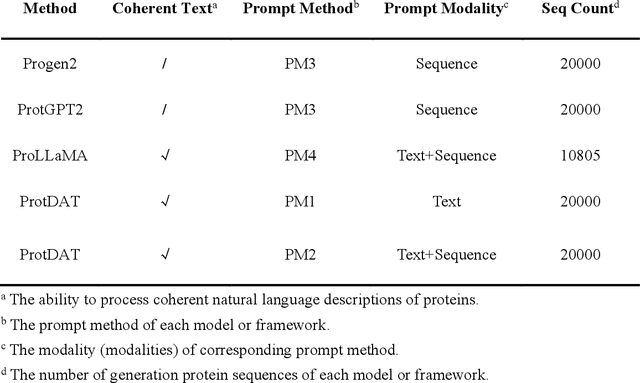
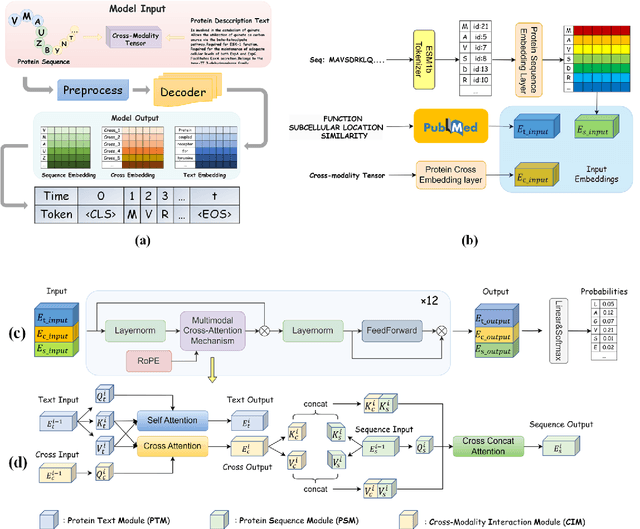
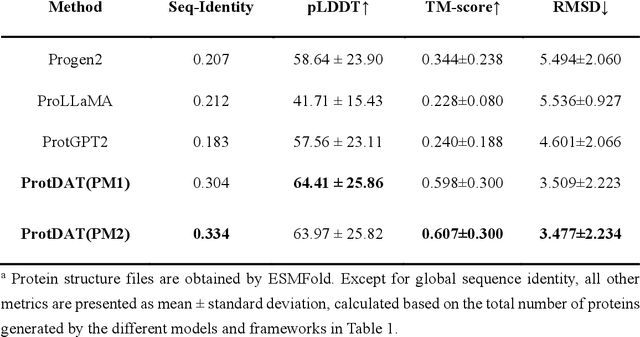
Protein design has become a critical method in advancing significant potential for various applications such as drug development and enzyme engineering. However, protein design methods utilizing large language models with solely pretraining and fine-tuning struggle to capture relationships in multi-modal protein data. To address this, we propose ProtDAT, a de novo fine-grained framework capable of designing proteins from any descriptive protein text input. ProtDAT builds upon the inherent characteristics of protein data to unify sequences and text as a cohesive whole rather than separate entities. It leverages an innovative multi-modal cross-attention, integrating protein sequences and textual information for a foundational level and seamless integration. Experimental results demonstrate that ProtDAT achieves the state-of-the-art performance in protein sequence generation, excelling in rationality, functionality, structural similarity, and validity. On 20,000 text-sequence pairs from Swiss-Prot, it improves pLDDT by 6%, TM-score by 0.26, and reduces RMSD by 1.2 {\AA}, highlighting its potential to advance protein design.
Using Human-like Mechanism to Weaken Effect of Pre-training Weight Bias in Face-Recognition Convolutional Neural Network
Oct 20, 2023



Convolutional neural network (CNN), as an important model in artificial intelligence, has been widely used and studied in different disciplines. The computational mechanisms of CNNs are still not fully revealed due to the their complex nature. In this study, we focused on 4 extensively studied CNNs (AlexNet, VGG11, VGG13, and VGG16) which has been analyzed as human-like models by neuroscientists with ample evidence. We trained these CNNs to emotion valence classification task by transfer learning. Comparing their performance with human data, the data unveiled that these CNNs would partly perform as human does. We then update the object-based AlexNet using self-attention mechanism based on neuroscience and behavioral data. The updated FE-AlexNet outperformed all the other tested CNNs and closely resembles human perception. The results further unveil the computational mechanisms of these CNNs. Moreover, this study offers a new paradigm to better understand and improve CNN performance via human data.
Towards Self-Adaptive Metric Learning On the Fly
Apr 03, 2021
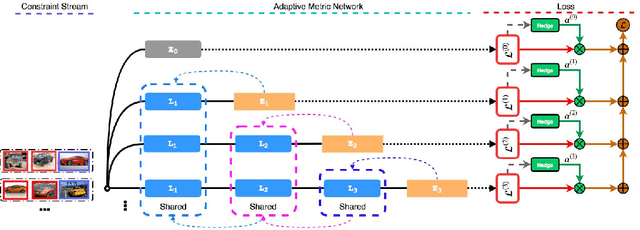
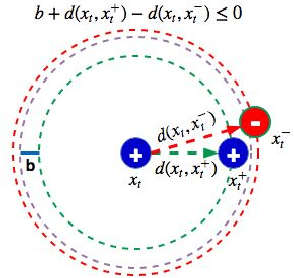
Good quality similarity metrics can significantly facilitate the performance of many large-scale, real-world applications. Existing studies have proposed various solutions to learn a Mahalanobis or bilinear metric in an online fashion by either restricting distances between similar (dissimilar) pairs to be smaller (larger) than a given lower (upper) bound or requiring similar instances to be separated from dissimilar instances with a given margin. However, these linear metrics learned by leveraging fixed bounds or margins may not perform well in real-world applications, especially when data distributions are complex. We aim to address the open challenge of "Online Adaptive Metric Learning" (OAML) for learning adaptive metric functions on the fly. Unlike traditional online metric learning methods, OAML is significantly more challenging since the learned metric could be non-linear and the model has to be self-adaptive as more instances are observed. In this paper, we present a new online metric learning framework that attempts to tackle the challenge by learning an ANN-based metric with adaptive model complexity from a stream of constraints. In particular, we propose a novel Adaptive-Bound Triplet Loss (ABTL) to effectively utilize the input constraints and present a novel Adaptive Hedge Update (AHU) method for online updating the model parameters. We empirically validate the effectiveness and efficacy of our framework on various applications such as real-world image classification, facial verification, and image retrieval.
SetConv: A New Approach for Learning from Imbalanced Data
Apr 03, 2021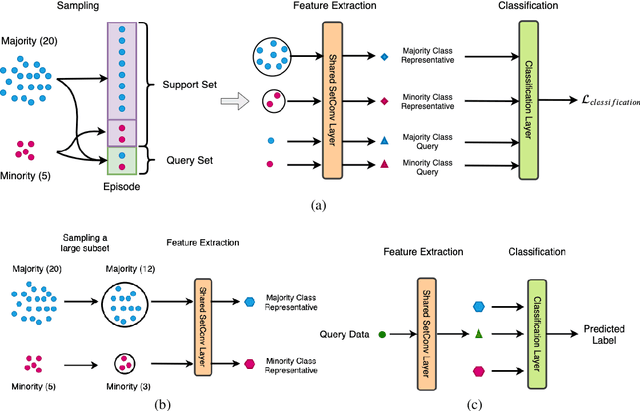
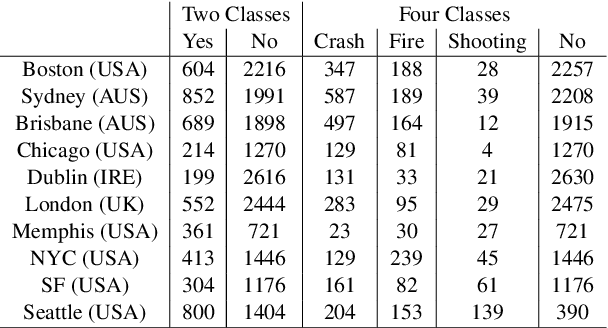
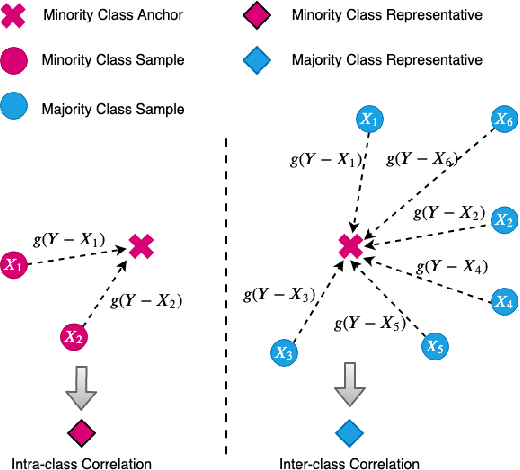
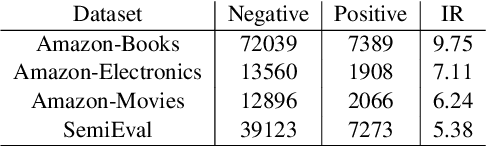
For many real-world classification problems, e.g., sentiment classification, most existing machine learning methods are biased towards the majority class when the Imbalance Ratio (IR) is high. To address this problem, we propose a set convolution (SetConv) operation and an episodic training strategy to extract a single representative for each class, so that classifiers can later be trained on a balanced class distribution. We prove that our proposed algorithm is permutation-invariant despite the order of inputs, and experiments on multiple large-scale benchmark text datasets show the superiority of our proposed framework when compared to other SOTA methods.
Deep Learning on Knowledge Graph for Recommender System: A Survey
Mar 25, 2020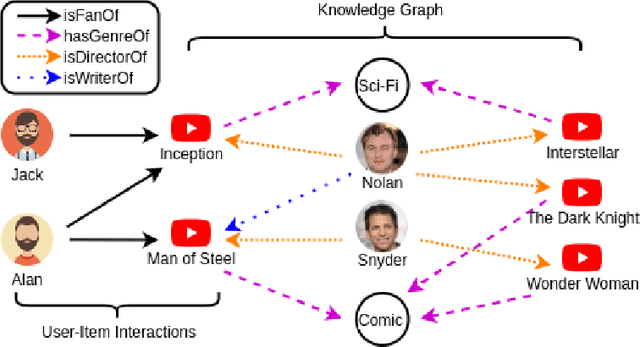



Recent advances in research have demonstrated the effectiveness of knowledge graphs (KG) in providing valuable external knowledge to improve recommendation systems (RS). A knowledge graph is capable of encoding high-order relations that connect two objects with one or multiple related attributes. With the help of the emerging Graph Neural Networks (GNN), it is possible to extract both object characteristics and relations from KG, which is an essential factor for successful recommendations. In this paper, we provide a comprehensive survey of the GNN-based knowledge-aware deep recommender systems. Specifically, we discuss the state-of-the-art frameworks with a focus on their core component, i.e., the graph embedding module, and how they address practical recommendation issues such as scalability, cold-start and so on. We further summarize the commonly-used benchmark datasets, evaluation metrics as well as open-source codes. Finally, we conclude the survey and propose potential research directions in this rapidly growing field.