 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtDAT: A Unified Framework for Protein Sequence Design from Any Protein Text Description
Dec 05, 2024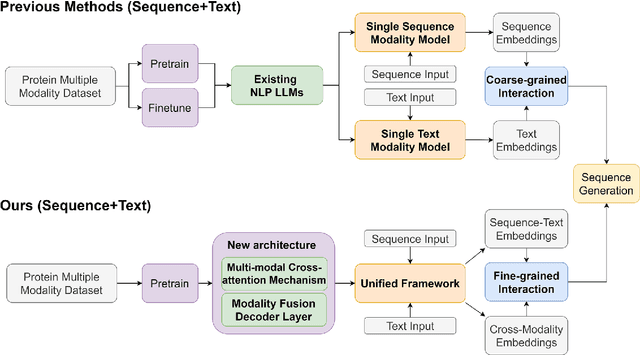
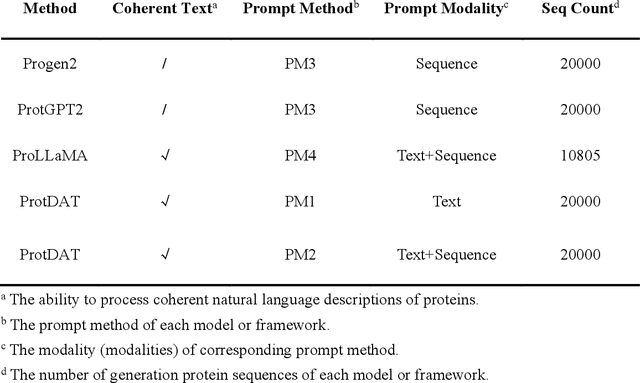
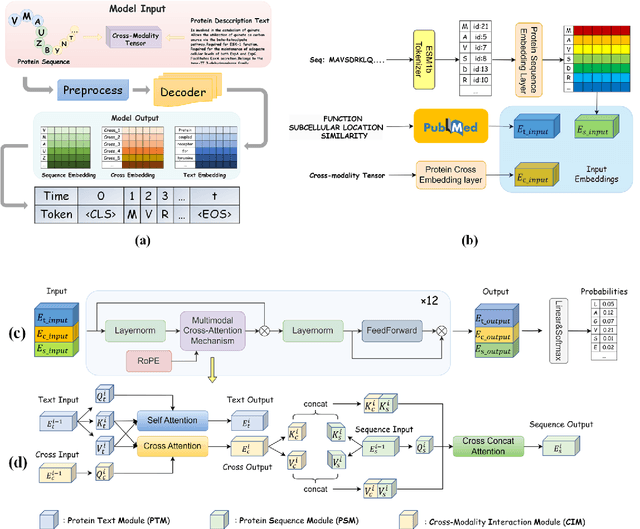
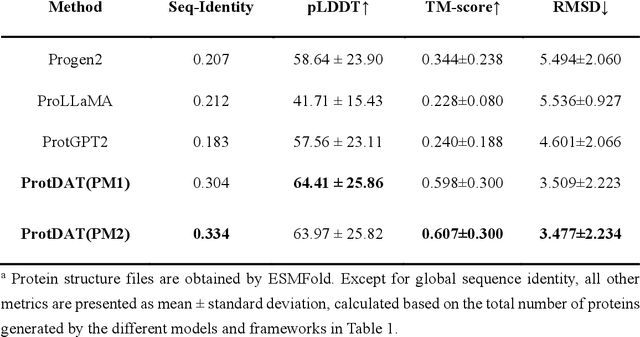
Protein design has become a critical method in advancing significant potential for various applications such as drug development and enzyme engineering. However, protein design methods utilizing large language models with solely pretraining and fine-tuning struggle to capture relationships in multi-modal protein data. To address this, we propose ProtDAT, a de novo fine-grained framework capable of designing proteins from any descriptive protein text input. ProtDAT builds upon the inherent characteristics of protein data to unify sequences and text as a cohesive whole rather than separate entities. It leverages an innovative multi-modal cross-attention, integrating protein sequences and textual information for a foundational level and seamless integration. Experimental results demonstrate that ProtDAT achieves the state-of-the-art performance in protein sequence generation, excelling in rationality, functionality, structural similarity, and validity. On 20,000 text-sequence pairs from Swiss-Prot, it improves pLDDT by 6%, TM-score by 0.26, and reduces RMSD by 1.2 {\AA}, highlighting its potential to advance protein design.
Unsupervised Difference Learning for Noisy Rigid Image Alignment
May 24, 2022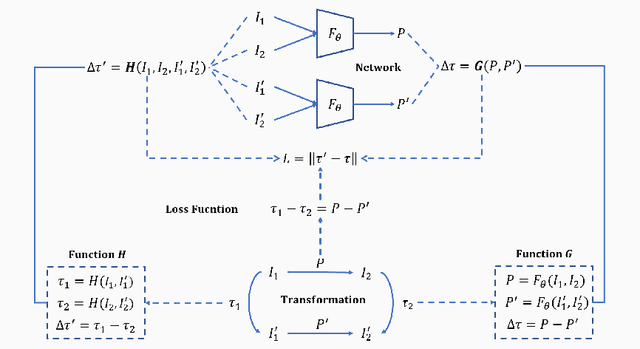
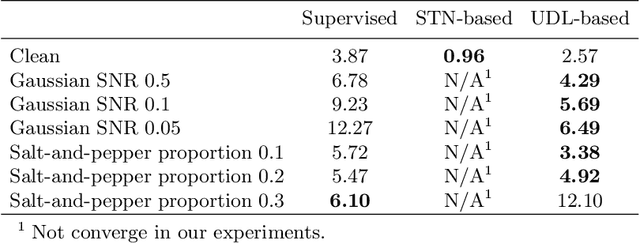
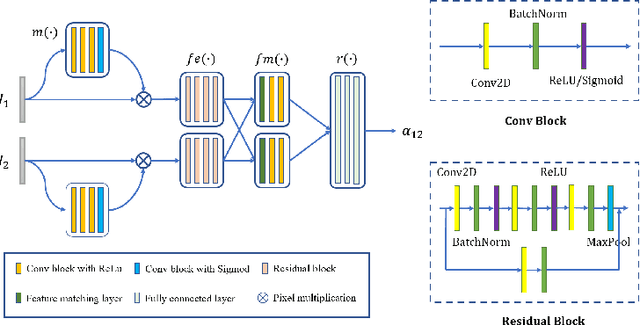

Rigid image alignment is a fundamental task in computer vision, while the traditional algorithms are either too sensitive to noise or time-consuming. Recent unsupervised image alignment methods developed based on spatial transformer networks show an improved performance on clean images but will not achieve satisfactory performance on noisy images due to its heavy reliance on pixel value comparations. To handle such challenging applications, we report a new unsupervised difference learning (UDL) strategy and apply it to rigid image alignment. UDL exploits the quantitative properties of regression tasks and converts the original unsupervised problem to pseudo supervised problem. Under the new UDL-based image alignment pipeline, rotation can be accurately estimated on both clean and noisy images and translations can then be easily solved. Experimental results on both nature and cryo-EM images demonstrate the efficacy of our UDL-based unsupervised rigid image alignment method.
Symbolic Expression Transformer: A Computer Vision Approach for Symbolic Regression
May 24, 2022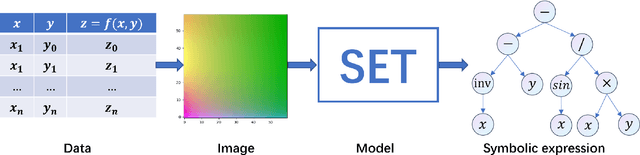
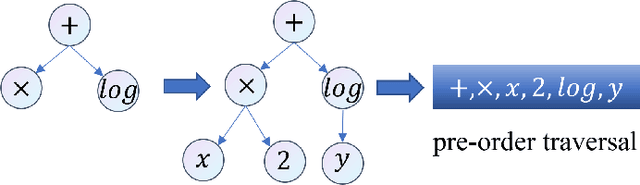
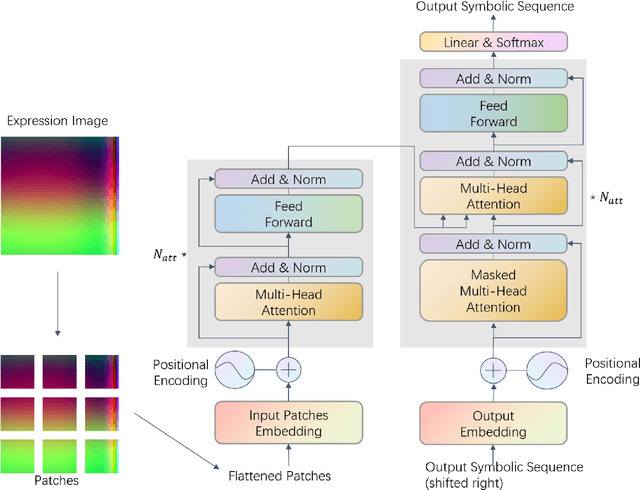
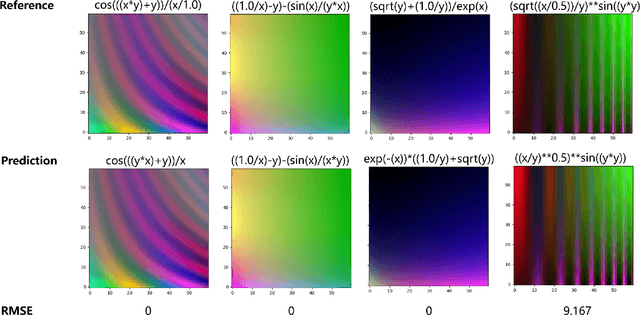
Symbolic Regression (SR) is a type of regression analysis to automatically find the mathematical expression that best fits the data. Currently, SR still basically relies on various searching strategies so that a sample-specific model is required to be optimized for every expression, which significantly limits the model's generalization and efficiency. Inspired by the fact that human beings can infer a mathematical expression based on the curve of it, we propose Symbolic Expression Transformer (SET), a sample-agnostic model from the perspective of computer vision for SR. Specifically, the collected data is represented as images and an image caption model is employed for translating images to symbolic expressions. A large-scale dataset without overlap between training and testing sets in the image domain is released. Our results demonstrate the effectiveness of SET and suggest the promising direction of image-based model for solving the challenging SR problem.