 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchGT: A Holistic System for Large-scale Graph Transformer Training
Jul 19, 2024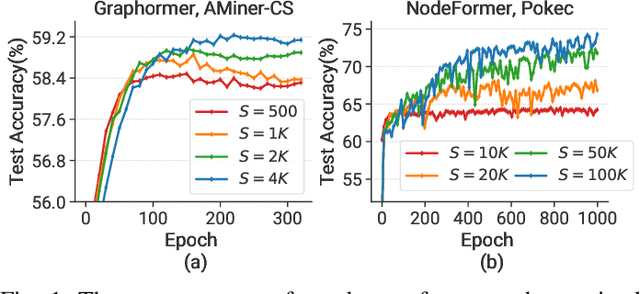
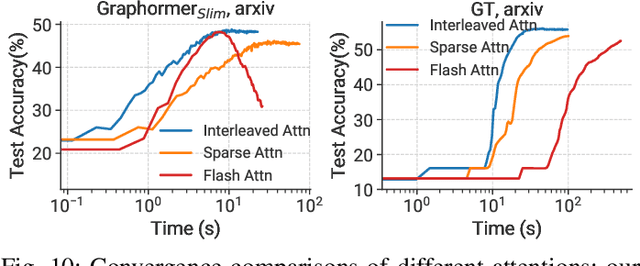
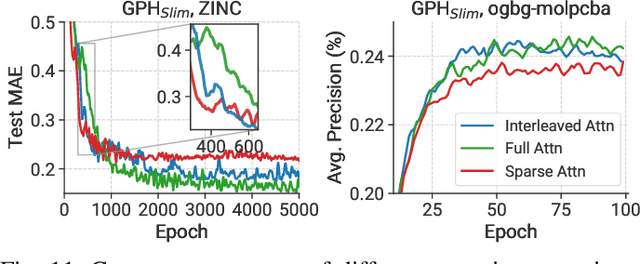
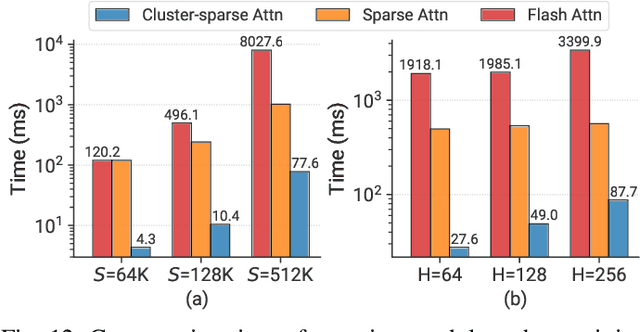
Graph Transformer is a new architecture that surpasses GNNs in graph learning. While there emerge inspiring algorithm advancements, their practical adoption is still limited, particularly on real-world graphs involving up to millions of nodes. We observe existing graph transformers fail on large-scale graphs mainly due to heavy computation, limited scalability and inferior model quality. Motivated by these observations, we propose TorchGT, the first efficient, scalable, and accurate graph transformer training system. TorchGT optimizes training at different levels. At algorithm level, by harnessing the graph sparsity, TorchGT introduces a Dual-interleaved Attention which is computation-efficient and accuracy-maintained. At runtime level, TorchGT scales training across workers with a communication-light Cluster-aware Graph Parallelism. At kernel level, an Elastic Computation Reformation further optimizes the computation by reducing memory access latency in a dynamic way. Extensive experiments demonstrate that TorchGT boosts training by up to 62.7x and supports graph sequence lengths of up to 1M.
DeFT: Flash Tree-attention with IO-Awareness for Efficient Tree-search-based LLM Inference
Mar 30, 2024Decoding using tree search can greatly enhance the inference quality for transformer-based Large Language Models (LLMs). Depending on the guidance signal, it searches for the best path from root to leaf in the tree by forming LLM outputs to improve controllability, reasoning ability, alignment, et cetera. However, current tree decoding strategies and their inference systems do not suit each other well due to redundancy in computation, memory footprints, and memory access, resulting in inefficient inference. To address this issue, we propose DeFT, an IO-aware tree attention algorithm that maintains memory-efficient attention calculation with low memory footprints in two stages: (1) QKV Preparation: we propose a KV-Guided Tree Split strategy to group QKV wisely for high utilization of GPUs and reduction of memory reads/writes for the KV cache between GPU global memory and on-chip shared memory as much as possible; (2) Attention Calculation: we calculate partial attention of each QKV groups in a fused kernel then apply a Tree-topology-aware Global Reduction strategy to get final attention. Thanks to a reduction in KV cache IO by 3.6-4.5$\times$, along with an additional reduction in IO for $\mathbf{Q} \mathbf{K}^\top$ and Softmax equivalent to 25% of the total KV cache IO, DeFT can achieve a speedup of 1.7-2.4$\times$ in end-to-end latency across two practical reasoning tasks over the SOTA attention algorithms.
MARS: Exploiting Multi-Level Parallelism for DNN Workloads on Adaptive Multi-Accelerator Systems
Jul 23, 2023



Along with the fast evolution of deep neural networks, the hardware system is also developing rapidly. As a promising solution achieving high scalability and low manufacturing cost, multi-accelerator systems widely exist in data centers, cloud platforms, and SoCs. Thus, a challenging problem arises in multi-accelerator systems: selecting a proper combination of accelerators from available designs and searching for efficient DNN mapping strategies. To this end, we propose MARS, a novel mapping framework that can perform computation-aware accelerator selection, and apply communication-aware sharding strategies to maximize parallelism. Experimental results show that MARS can achieve 32.2% latency reduction on average for typical DNN workloads compared to the baseline, and 59.4% latency reduction on heterogeneous models compared to the corresponding state-of-the-art method.
Accelerating Generalized Linear Models with MLWeaving: A One-Size-Fits-All System for Any-precision Learning (Technical Report)
Mar 28, 2019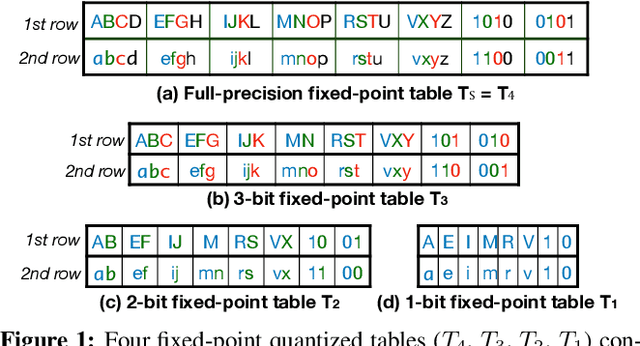
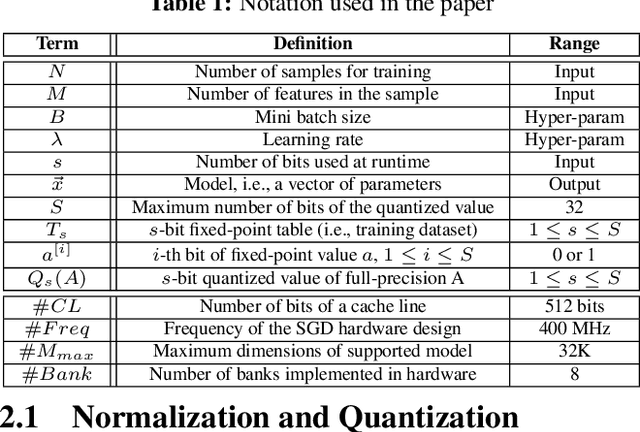
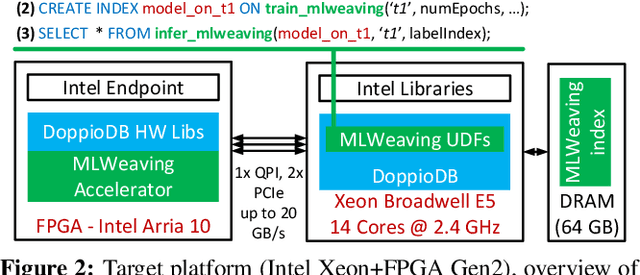
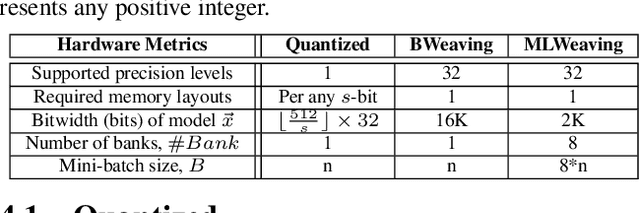
Learning from the data stored in a database is an important function increasingly available in relational engines. Methods using lower precision input data are of special interest given their overall higher efficiency but, in databases, these methods have a hidden cost: the quantization of the real value into a smaller number is an expensive step. To address the issue, in this paper we present MLWeaving, a data structure and hardware acceleration technique intended to speed up learning of generalized linear models in databases. ML-Weaving provides a compact, in-memory representation enabling the retrieval of data at any level of precision. MLWeaving also takes advantage of the increasing availability of FPGA-based accelerators to provide a highly efficient implementation of stochastic gradient descent. The solution adopted in MLWeaving is more efficient than existing designs in terms of space (since it can process any resolution on the same design) and resources (via the use of bit-serial multipliers). MLWeaving also enables the runtime tuning of precision, instead of a fixed precision level during the training. We illustrate this using a simple, dynamic precision schedule. Experimental results show MLWeaving achieves up to16 performance improvement over low-precision CPU implementations of first-order methods.
* 18 pages