 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Generalized Linear Models with MLWeaving: A One-Size-Fits-All System for Any-precision Learning (Technical Report)
Paper and Code
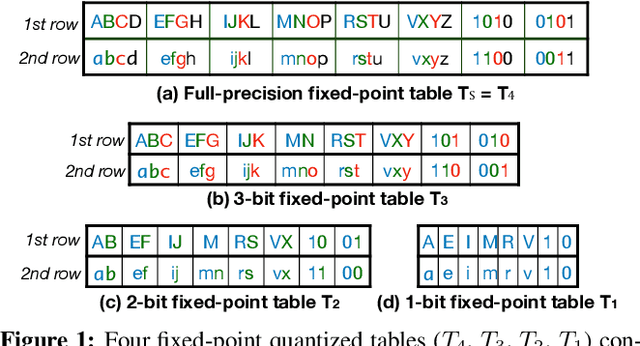
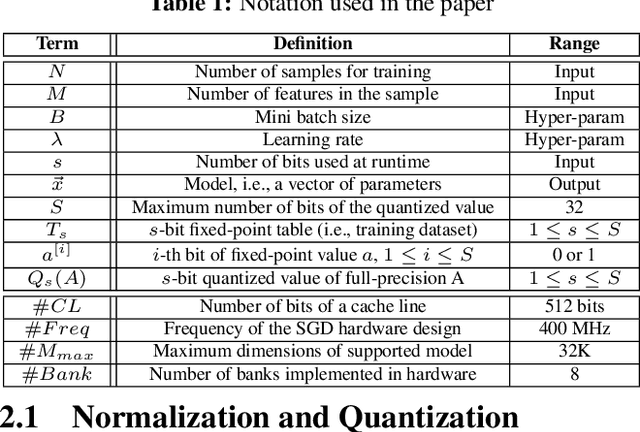
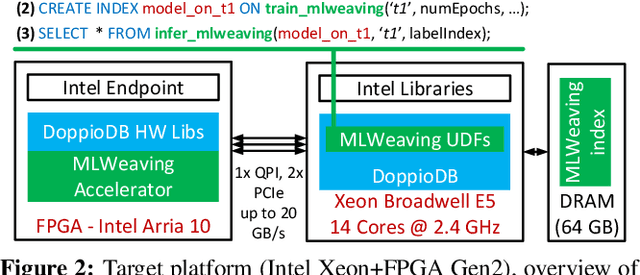
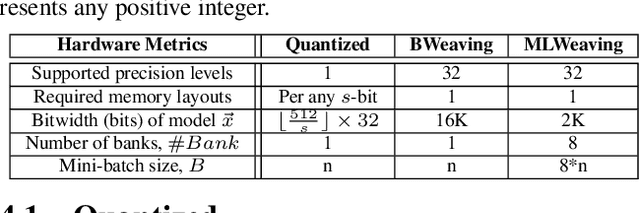
Learning from the data stored in a database is an important function increasingly available in relational engines. Methods using lower precision input data are of special interest given their overall higher efficiency but, in databases, these methods have a hidden cost: the quantization of the real value into a smaller number is an expensive step. To address the issue, in this paper we present MLWeaving, a data structure and hardware acceleration technique intended to speed up learning of generalized linear models in databases. ML-Weaving provides a compact, in-memory representation enabling the retrieval of data at any level of precision. MLWeaving also takes advantage of the increasing availability of FPGA-based accelerators to provide a highly efficient implementation of stochastic gradient descent. The solution adopted in MLWeaving is more efficient than existing designs in terms of space (since it can process any resolution on the same design) and resources (via the use of bit-serial multipliers). MLWeaving also enables the runtime tuning of precision, instead of a fixed precision level during the training. We illustrate this using a simple, dynamic precision schedule. Experimental results show MLWeaving achieves up to16 performance improvement over low-precision CPU implementations of first-order methods.