 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchGT: A Holistic System for Large-scale Graph Transformer Training
Paper and Code
Jul 19, 2024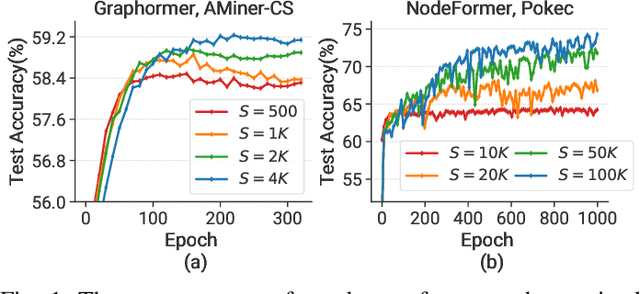
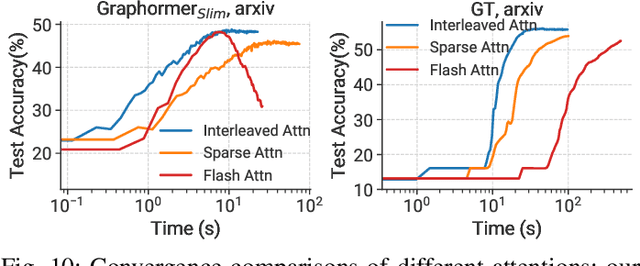
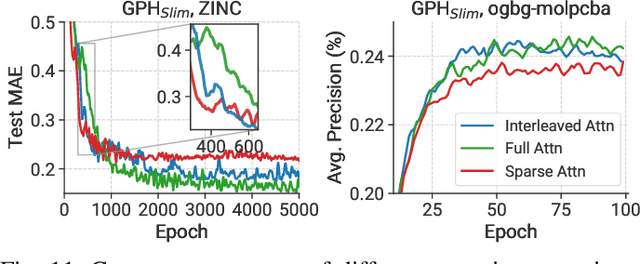
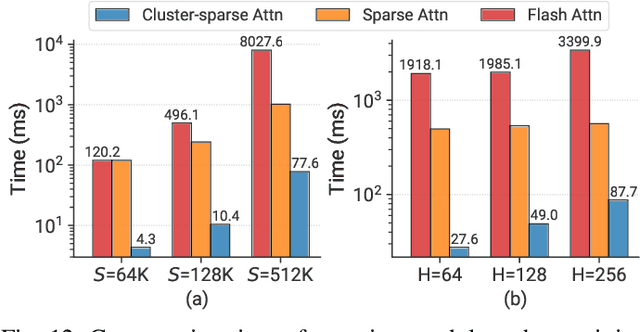
Graph Transformer is a new architecture that surpasses GNNs in graph learning. While there emerge inspiring algorithm advancements, their practical adoption is still limited, particularly on real-world graphs involving up to millions of nodes. We observe existing graph transformers fail on large-scale graphs mainly due to heavy computation, limited scalability and inferior model quality. Motivated by these observations, we propose TorchGT, the first efficient, scalable, and accurate graph transformer training system. TorchGT optimizes training at different levels. At algorithm level, by harnessing the graph sparsity, TorchGT introduces a Dual-interleaved Attention which is computation-efficient and accuracy-maintained. At runtime level, TorchGT scales training across workers with a communication-light Cluster-aware Graph Parallelism. At kernel level, an Elastic Computation Reformation further optimizes the computation by reducing memory access latency in a dynamic way. Extensive experiments demonstrate that TorchGT boosts training by up to 62.7x and supports graph sequence lengths of up to 1M.