 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPACT: A Dataset for Multi-Granularity Human Procedural Action Understanding in Industrial Assembly
Apr 12, 2026We introduce IMPACT, a synchronized five-view RGB-D dataset for deployment-oriented industrial procedural understanding, built around real assembly and disassembly of a commercial angle grinder with professional-grade tools. To our knowledge, IMPACT is the first real industrial assembly benchmark that jointly provides synchronized ego-exo RGB-D capture, decoupled bimanual annotation, compliance-aware state tracking, and explicit anomaly--recovery supervision within a single real industrial workflow. It comprises 112 trials from 13 participants totaling 39.5 hours, with multi-route execution governed by a partial-order prerequisite graph, a six-category anomaly taxonomy, and operator cognitive load measured via NASA-TLX. The annotation hierarchy links hand-specific atomic actions to coarse procedural steps, component assembly states, and per-hand compliance phases, with synchronized null spans across views to decouple perceptual limitations from algorithmic failure. Systematic baselines reveal fundamental limitations that remain invisible to single-task benchmarks, particularly under realistic deployment conditions that involve incomplete observations, flexible execution paths, and corrective behavior. The full dataset, annotations, and evaluation code are available at https://github.com/Kratos-Wen/IMPACT.
CompliantVLA-adaptor: VLM-Guided Variable Impedance Action for Safe Contact-Rich Manipulation
Jan 21, 2026We propose a CompliantVLA-adaptor that augments the state-of-the-art Vision-Language-Action (VLA) models with vision-language model (VLM)-informed context-aware variable impedance control (VIC) to improve the safety and effectiveness of contact-rich robotic manipulation tasks. Existing VLA systems (e.g., RDT, Pi0, OpenVLA-oft) typically output position, but lack force-aware adaptation, leading to unsafe or failed interactions in physical tasks involving contact, compliance, or uncertainty. In the proposed CompliantVLA-adaptor, a VLM interprets task context from images and natural language to adapt the stiffness and damping parameters of a VIC controller. These parameters are further regulated using real-time force/torque feedback to ensure interaction forces remain within safe thresholds. We demonstrate that our method outperforms the VLA baselines on a suite of complex contact-rich tasks, both in simulation and on real hardware, with improved success rates and reduced force violations. The overall success rate across all tasks increases from 9.86\% to 17.29\%, presenting a promising path towards safe contact-rich manipulation using VLAs. We release our code, prompts, and force-torque-impedance-scenario context datasets at https://sites.google.com/view/compliantvla.
Graph-based Online Monitoring of Train Driver States via Facial and Skeletal Features
May 09, 2025Driver fatigue poses a significant challenge to railway safety, with traditional systems like the dead-man switch offering limited and basic alertness checks. This study presents an online behavior-based monitoring system utilizing a customised Directed-Graph Neural Network (DGNN) to classify train driver's states into three categories: alert, not alert, and pathological. To optimize input representations for the model, an ablation study was performed, comparing three feature configurations: skeletal-only, facial-only, and a combination of both. Experimental results show that combining facial and skeletal features yields the highest accuracy (80.88%) in the three-class model, outperforming models using only facial or skeletal features. Furthermore, this combination achieves over 99% accuracy in the binary alertness classification. Additionally, we introduced a novel dataset that, for the first time, incorporates simulated pathological conditions into train driver monitoring, broadening the scope for assessing risks related to fatigue and health. This work represents a step forward in enhancing railway safety through advanced online monitoring using vision-based technologies.
Semantic Visual Simultaneous Localization and Mapping: A Survey
Sep 14, 2022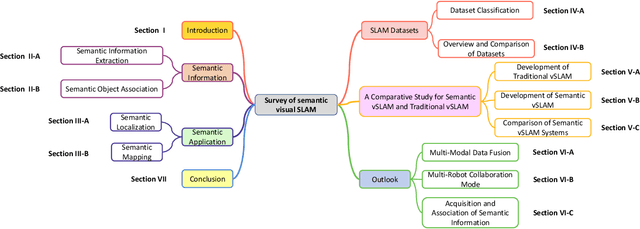
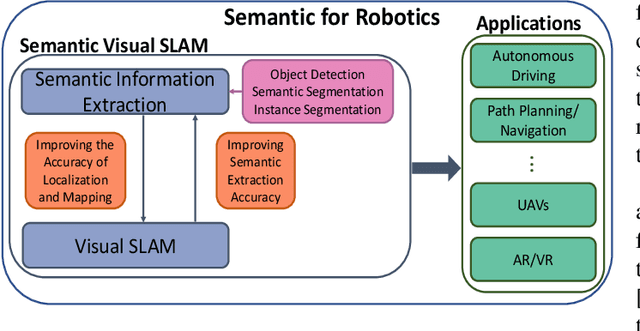

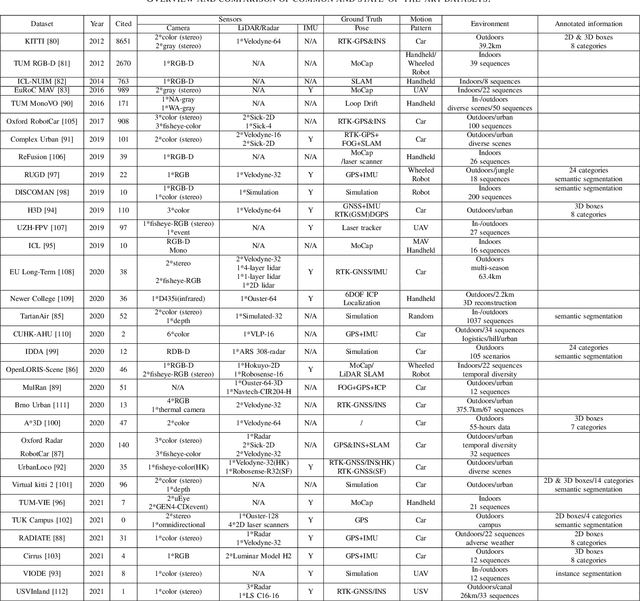
Visual Simultaneous Localization and Mapping (vSLAM) has achieved great progress in the computer vision and robotics communities, and has been successfully used in many fields such as autonomous robot navigation and AR/VR. However, vSLAM cannot achieve good localization in dynamic and complex environments. Numerous publications have reported that, by combining with the semantic information with vSLAM, the semantic vSLAM systems have the capability of solving the above problems in recent years. Nevertheless, there is no comprehensive survey about semantic vSLAM. To fill the gap, this paper first reviews the development of semantic vSLAM, explicitly focusing on its strengths and differences. Secondly, we explore three main issues of semantic vSLAM: the extraction and association of semantic information, the application of semantic information, and the advantages of semantic vSLAM. Then, we collect and analyze the current state-of-the-art SLAM datasets which have been widely used in semantic vSLAM systems. Finally, we discuss future directions that will provide a blueprint for the future development of semantic vSLAM.