 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZEST: Attention-based Zero-Shot Learning for Unseen IoT Device Classification
Oct 12, 2023Recent research works have proposed machine learning models for classifying IoT devices connected to a network. However, there is still a practical challenge of not having all devices (and hence their traffic) available during the training of a model. This essentially means, during the operational phase, we need to classify new devices not seen during the training phase. To address this challenge, we propose ZEST -- a ZSL (zero-shot learning) framework based on self-attention for classifying both seen and unseen devices. ZEST consists of i) a self-attention based network feature extractor, termed SANE, for extracting latent space representations of IoT traffic, ii) a generative model that trains a decoder using latent features to generate pseudo data, and iii) a supervised model that is trained on the generated pseudo data for classifying devices. We carry out extensive experiments on real IoT traffic data; our experiments demonstrate i) ZEST achieves significant improvement (in terms of accuracy) over the baselines; ii) ZEST is able to better extract meaningful representations than LSTM which has been commonly used for modeling network traffic.
Hardware-oriented Approximation of Convolutional Neural Networks
Oct 20, 2016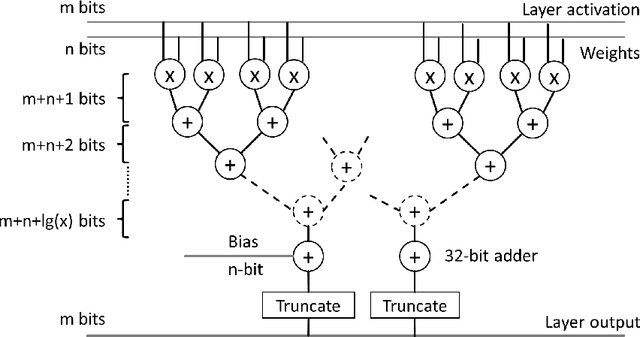
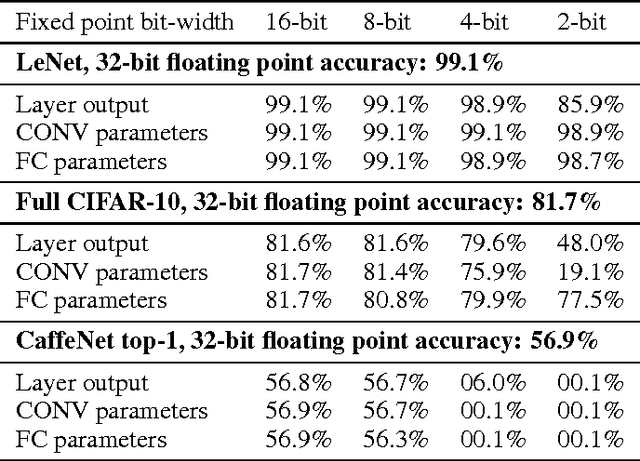
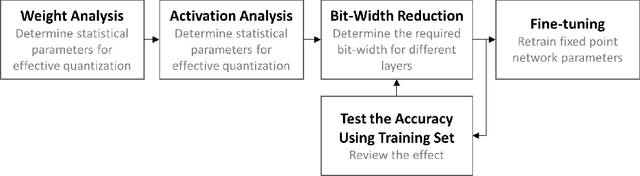
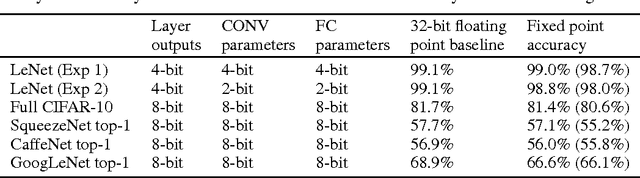
High computational complexity hinders the widespread usage of Convolutional Neural Networks (CNNs), especially in mobile devices. Hardware accelerators are arguably the most promising approach for reducing both execution time and power consumption. One of the most important steps in accelerator development is hardware-oriented model approximation. In this paper we present Ristretto, a model approximation framework that analyzes a given CNN with respect to numerical resolution used in representing weights and outputs of convolutional and fully connected layers. Ristretto can condense models by using fixed point arithmetic and representation instead of floating point. Moreover, Ristretto fine-tunes the resulting fixed point network. Given a maximum error tolerance of 1%, Ristretto can successfully condense CaffeNet and SqueezeNet to 8-bit. The code for Ristretto is available.
Ristretto: Hardware-Oriented Approximation of Convolutional Neural Networks
May 20, 2016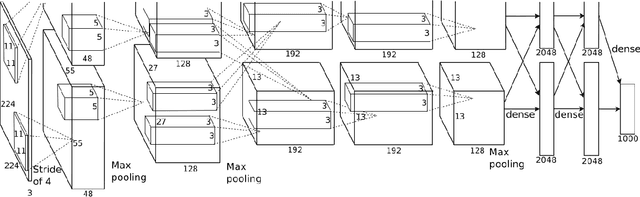
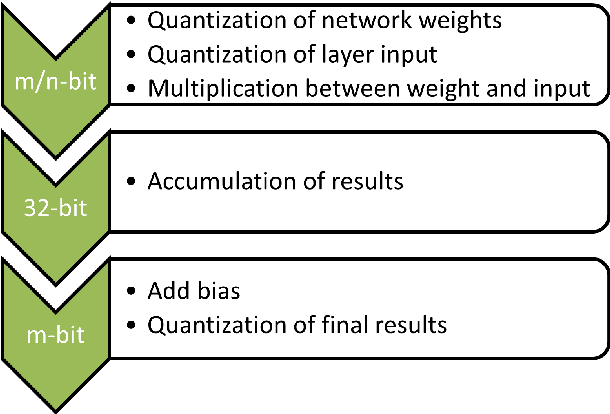
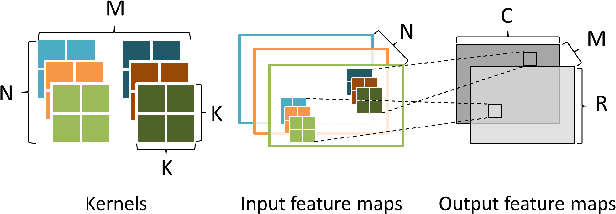

Convolutional neural networks (CNN) have achieved major breakthroughs in recent years. Their performance in computer vision have matched and in some areas even surpassed human capabilities. Deep neural networks can capture complex non-linear features; however this ability comes at the cost of high computational and memory requirements. State-of-art networks require billions of arithmetic operations and millions of parameters. To enable embedded devices such as smartphones, Google glasses and monitoring cameras with the astonishing power of deep learning, dedicated hardware accelerators can be used to decrease both execution time and power consumption. In applications where fast connection to the cloud is not guaranteed or where privacy is important, computation needs to be done locally. Many hardware accelerators for deep neural networks have been proposed recently. A first important step of accelerator design is hardware-oriented approximation of deep networks, which enables energy-efficient inference. We present Ristretto, a fast and automated framework for CNN approximation. Ristretto simulates the hardware arithmetic of a custom hardware accelerator. The framework reduces the bit-width of network parameters and outputs of resource-intense layers, which reduces the chip area for multiplication units significantly. Alternatively, Ristretto can remove the need for multipliers altogether, resulting in an adder-only arithmetic. The tool fine-tunes trimmed networks to achieve high classification accuracy. Since training of deep neural networks can be time-consuming, Ristretto uses highly optimized routines which run on the GPU. This enables fast compression of any given network. Given a maximum tolerance of 1%, Ristretto can successfully condense CaffeNet and SqueezeNet to 8-bit. The code for Ristretto is available.