 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARSRec: Explainable Personalized Attention-fused Recurrent Sequential Recommendation Using Session Partial Actions
Sep 16, 2022



The emerging meta- and multi-verse landscape is yet another step towards the more prevalent use of already ubiquitous online markets. In such markets, recommender systems play critical roles by offering items of interest to the users, thereby narrowing down a vast search space that comprises hundreds of thousands of products. Recommender systems are usually designed to learn common user behaviors and rely on them for inference. This approach, while effective, is oblivious to subtle idiosyncrasies that differentiate humans from each other. Focusing on this observation, we propose an architecture that relies on common patterns as well as individual behaviors to tailor its recommendations for each person. Simulations under a controlled environment show that our proposed model learns interpretable personalized user behaviors. Our empirical results on Nielsen Consumer Panel dataset indicate that the proposed approach achieves up to 27.9% performance improvement compared to the state-of-the-art.
A Data-Centric Approach for Training Deep Neural Networks with Less Data
Oct 29, 2021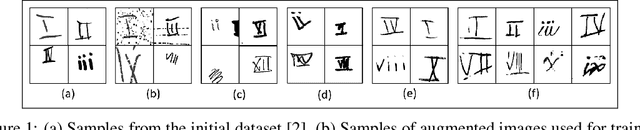

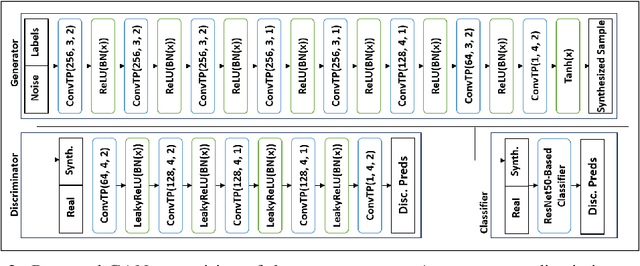
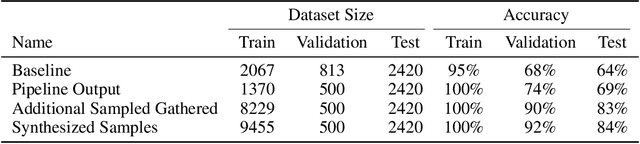
While the availability of large datasets is perceived to be a key requirement for training deep neural networks, it is possible to train such models with relatively little data. However, compensating for the absence of large datasets demands a series of actions to enhance the quality of the existing samples and to generate new ones. This paper summarizes our winning submission to the "Data-Centric AI" competition. We discuss some of the challenges that arise while training with a small dataset, offer a principled approach for systematic data quality enhancement, and propose a GAN-based solution for synthesizing new data points. Our evaluations indicate that the dataset generated by the proposed pipeline offers 5% accuracy improvement while being significantly smaller than the baseline.
Distill-Net: Application-Specific Distillation of Deep Convolutional Neural Networks for Resource-Constrained IoT Platforms
Dec 16, 2018



Many Internet-of-Things (IoT) applications demand fast and accurate understanding of a few key events in their surrounding environment. Deep Convolutional Neural Networks (CNNs) have emerged as an effective approach to understand speech, images, and similar high dimensional data types. Algorithmic performance of modern CNNs, however, fundamentally relies on learning class-agnostic hierarchical features that only exist in comprehensive training datasets with many classes. As a result, fast inference using CNNs trained on such datasets is prohibitive for most resource-constrained IoT platforms. To bridge this gap, we present a principled and practical methodology for distilling a complex modern CNN that is trained to effectively recognize many different classes of input data into an application-dependent essential core that not only recognizes the few classes of interest to the application accurately, but also runs efficiently on platforms with limited resources. Experimental results confirm that our approach strikes a favorable balance between classification accuracy (application constraint), inference efficiency (platform constraint), and productive development of new applications (business constraint).
Resource-Scalable CNN Synthesis for IoT Applications
Dec 16, 2018
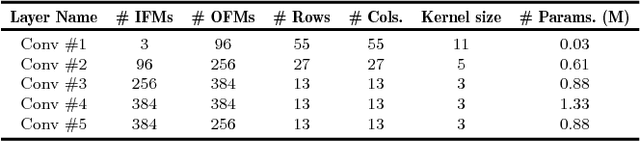
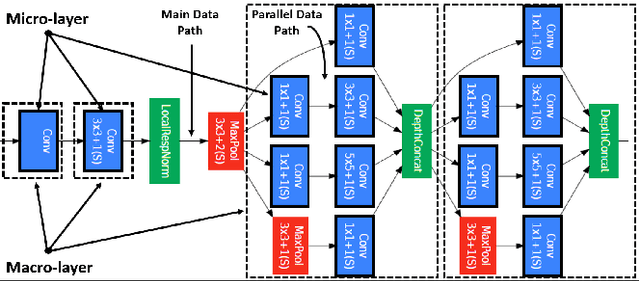
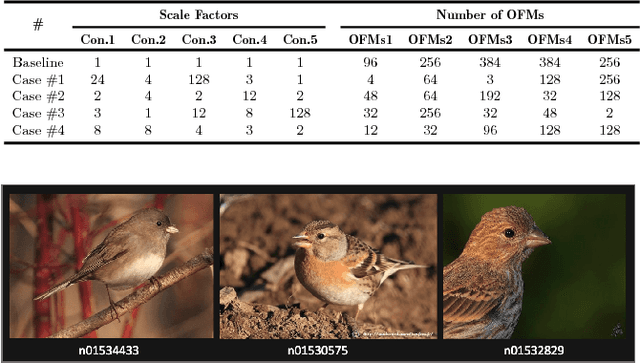
State-of-the-art image recognition systems use sophisticated Convolutional Neural Networks (CNNs) that are designed and trained to identify numerous object classes. Such networks are fairly resource intensive to compute, prohibiting their deployment on resource-constrained embedded platforms. On one hand, the ability to classify an exhaustive list of categories is excessive for the demands of most IoT applications. On the other hand, designing a new custom-designed CNN for each new IoT application is impractical, due to the inherent difficulty in developing competitive models and time-to-market pressure. To address this problem, we investigate the question of: "Can one utilize an existing optimized CNN model to automatically build a competitive CNN for an IoT application whose objects of interest are a fraction of categories that the original CNN was designed to classify, such that the resource requirement is proportionally scaled down?" We use the term resource scalability to refer to this concept, and develop a methodology for automated synthesis of resource scalable CNNs from an existing optimized baseline CNN. The synthesized CNN has sufficient learning capacity for handling the given IoT application requirements, and yields competitive accuracy. The proposed approach is fast, and unlike the presently common practice of CNN design, does not require iterative rounds of training trial and error.
Fast and Energy-Efficient CNN Inference on IoT Devices
Nov 22, 2016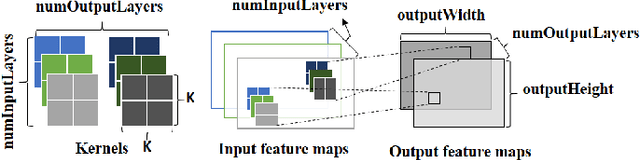
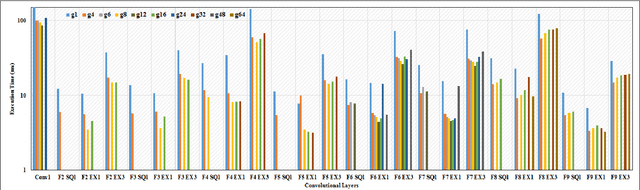


Convolutional Neural Networks (CNNs) exhibit remarkable performance in various machine learning tasks. As sensor-equipped internet of things (IoT) devices permeate into every aspect of modern life, it is increasingly important to run CNN inference, a computationally intensive application, on resource constrained devices. We present a technique for fast and energy-efficient CNN inference on mobile SoC platforms, which are projected to be a major player in the IoT space. We propose techniques for efficient parallelization of CNN inference targeting mobile GPUs, and explore the underlying tradeoffs. Experiments with running Squeezenet on three different mobile devices confirm the effectiveness of our approach. For further study, please refer to the project repository available on our GitHub page: https://github.com/mtmd/Mobile_ConvNet
Hardware-oriented Approximation of Convolutional Neural Networks
Oct 20, 2016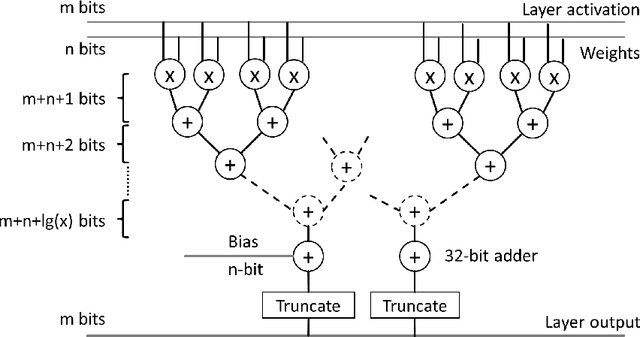
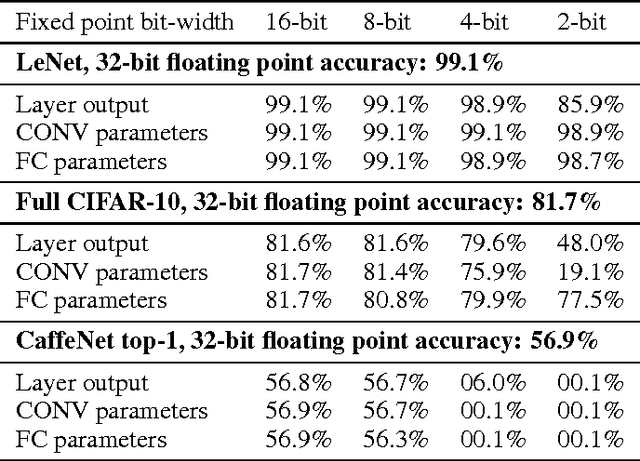
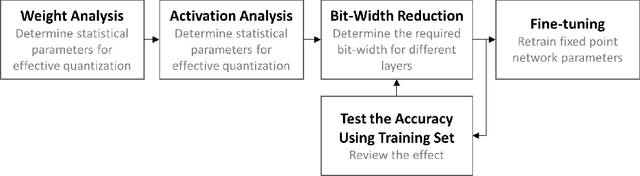
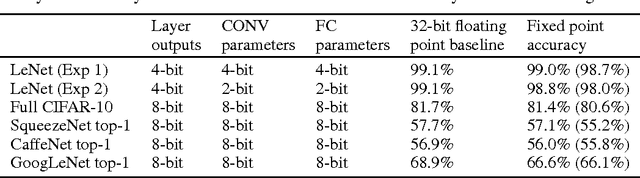
High computational complexity hinders the widespread usage of Convolutional Neural Networks (CNNs), especially in mobile devices. Hardware accelerators are arguably the most promising approach for reducing both execution time and power consumption. One of the most important steps in accelerator development is hardware-oriented model approximation. In this paper we present Ristretto, a model approximation framework that analyzes a given CNN with respect to numerical resolution used in representing weights and outputs of convolutional and fully connected layers. Ristretto can condense models by using fixed point arithmetic and representation instead of floating point. Moreover, Ristretto fine-tunes the resulting fixed point network. Given a maximum error tolerance of 1%, Ristretto can successfully condense CaffeNet and SqueezeNet to 8-bit. The code for Ristretto is available.