 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Centric Approach for Training Deep Neural Networks with Less Data
Oct 29, 2021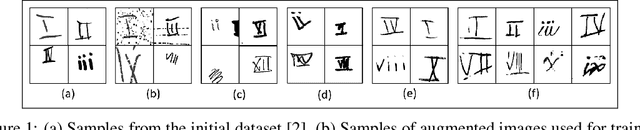

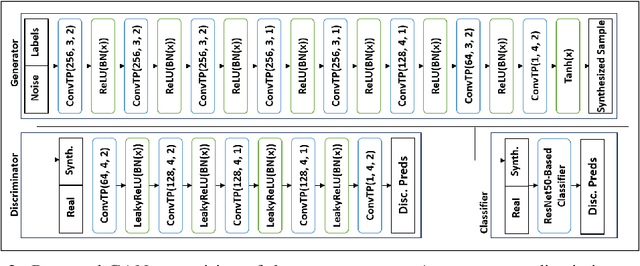
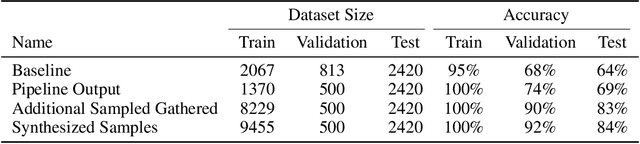
While the availability of large datasets is perceived to be a key requirement for training deep neural networks, it is possible to train such models with relatively little data. However, compensating for the absence of large datasets demands a series of actions to enhance the quality of the existing samples and to generate new ones. This paper summarizes our winning submission to the "Data-Centric AI" competition. We discuss some of the challenges that arise while training with a small dataset, offer a principled approach for systematic data quality enhancement, and propose a GAN-based solution for synthesizing new data points. Our evaluations indicate that the dataset generated by the proposed pipeline offers 5% accuracy improvement while being significantly smaller than the baseline.