 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Large Language Models for Phishing Webpage Detection and Identification
Aug 12, 2024


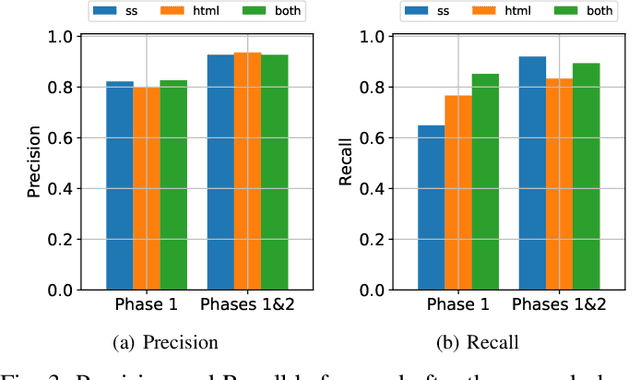
To address the challenging problem of detecting phishing webpages, researchers have developed numerous solutions, in particular those based on machine learning (ML) algorithms. Among these, brand-based phishing detection that uses models from Computer Vision to detect if a given webpage is imitating a well-known brand has received widespread attention. However, such models are costly and difficult to maintain, as they need to be retrained with labeled dataset that has to be regularly and continuously collected. Besides, they also need to maintain a good reference list of well-known websites and related meta-data for effective performance. In this work, we take steps to study the efficacy of large language models (LLMs), in particular the multimodal LLMs, in detecting phishing webpages. Given that the LLMs are pretrained on a large corpus of data, we aim to make use of their understanding of different aspects of a webpage (logo, theme, favicon, etc.) to identify the brand of a given webpage and compare the identified brand with the domain name in the URL to detect a phishing attack. We propose a two-phase system employing LLMs in both phases: the first phase focuses on brand identification, while the second verifies the domain. We carry out comprehensive evaluations on a newly collected dataset. Our experiments show that the LLM-based system achieves a high detection rate at high precision; importantly, it also provides interpretable evidence for the decisions. Our system also performs significantly better than a state-of-the-art brand-based phishing detection system while demonstrating robustness against two known adversarial attacks.