 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbably Approximate Shapley Fairness with Applications in Machine Learning
Dec 01, 2022
The Shapley value (SV) is adopted in various scenarios in machine learning (ML), including data valuation, agent valuation, and feature attribution, as it satisfies their fairness requirements. However, as exact SVs are infeasible to compute in practice, SV estimates are approximated instead. This approximation step raises an important question: do the SV estimates preserve the fairness guarantees of exact SVs? We observe that the fairness guarantees of exact SVs are too restrictive for SV estimates. Thus, we generalise Shapley fairness to probably approximate Shapley fairness and propose fidelity score, a metric to measure the variation of SV estimates, that determines how probable the fairness guarantees hold. Our last theoretical contribution is a novel greedy active estimation (GAE) algorithm that will maximise the lowest fidelity score and achieve a better fairness guarantee than the de facto Monte-Carlo estimation. We empirically verify GAE outperforms several existing methods in guaranteeing fairness while remaining competitive in estimation accuracy in various ML scenarios using real-world datasets.
Federated Bayesian Optimization via Thompson Sampling
Oct 22, 2020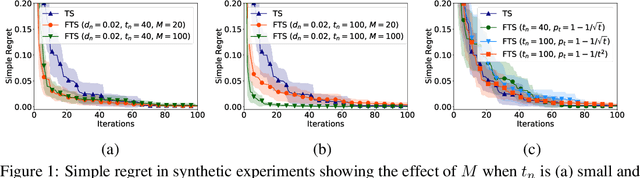
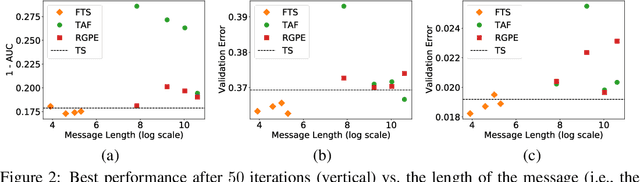
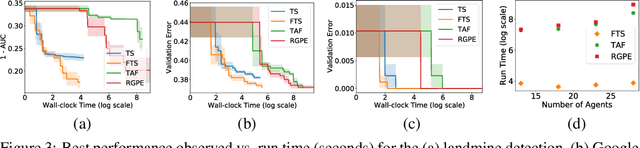
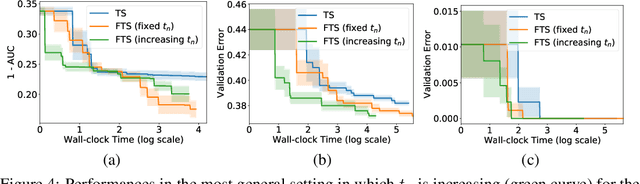
Bayesian optimization (BO) is a prominent approach to optimizing expensive-to-evaluate black-box functions. The massive computational capability of edge devices such as mobile phones, coupled with privacy concerns, has led to a surging interest in federated learning (FL) which focuses on collaborative training of deep neural networks (DNNs) via first-order optimization techniques. However, some common machine learning tasks such as hyperparameter tuning of DNNs lack access to gradients and thus require zeroth-order/black-box optimization. This hints at the possibility of extending BO to the FL setting (FBO) for agents to collaborate in these black-box optimization tasks. This paper presents federated Thompson sampling (FTS) which overcomes a number of key challenges of FBO and FL in a principled way: We (a) use random Fourier features to approximate the Gaussian process surrogate model used in BO, which naturally produces the parameters to be exchanged between agents, (b) design FTS based on Thompson sampling, which significantly reduces the number of parameters to be exchanged, and (c) provide a theoretical convergence guarantee that is robust against heterogeneous agents, which is a major challenge in FL and FBO. We empirically demonstrate the effectiveness of FTS in terms of communication efficiency, computational efficiency, and practical performance.
R2-B2: Recursive Reasoning-Based Bayesian Optimization for No-Regret Learning in Games
Jun 30, 2020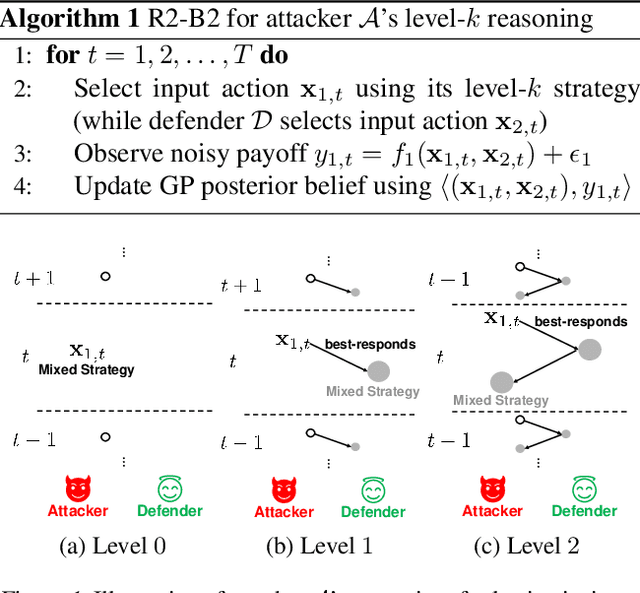

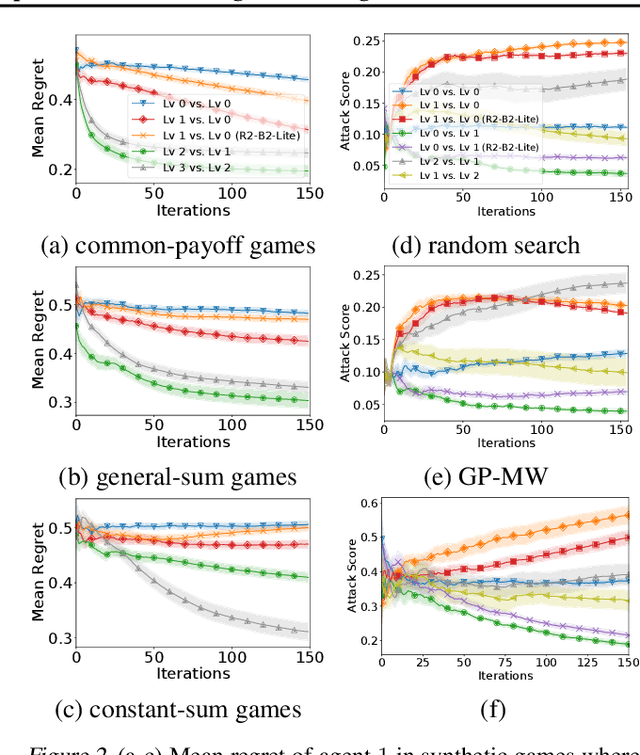
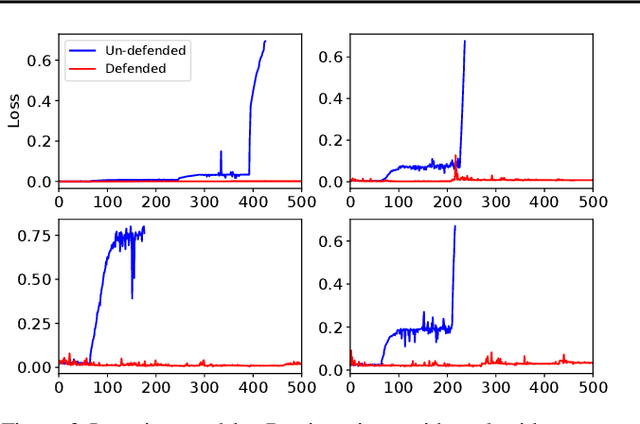
This paper presents a recursive reasoning formalism of Bayesian optimization (BO) to model the reasoning process in the interactions between boundedly rational, self-interested agents with unknown, complex, and costly-to-evaluate payoff functions in repeated games, which we call Recursive Reasoning-Based BO (R2-B2). Our R2-B2 algorithm is general in that it does not constrain the relationship among the payoff functions of different agents and can thus be applied to various types of games such as constant-sum, general-sum, and common-payoff games. We prove that by reasoning at level 2 or more and at one level higher than the other agents, our R2-B2 agent can achieve faster asymptotic convergence to no regret than that without utilizing recursive reasoning. We also propose a computationally cheaper variant of R2-B2 called R2-B2-Lite at the expense of a weaker convergence guarantee. The performance and generality of our R2-B2 algorithm are empirically demonstrated using synthetic games, adversarial machine learning, and multi-agent reinforcement learning.
Nonmyopic Gaussian Process Optimization with Macro-Actions
Feb 22, 2020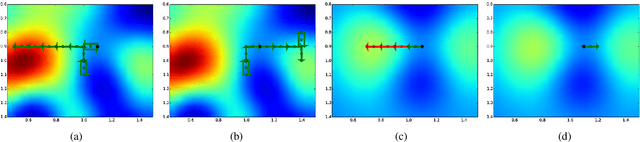
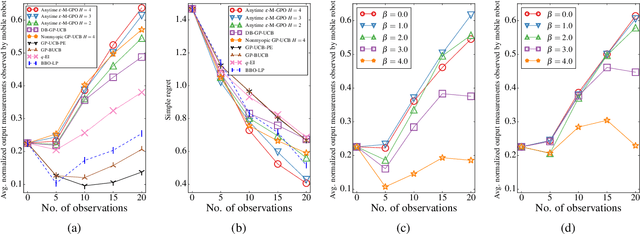
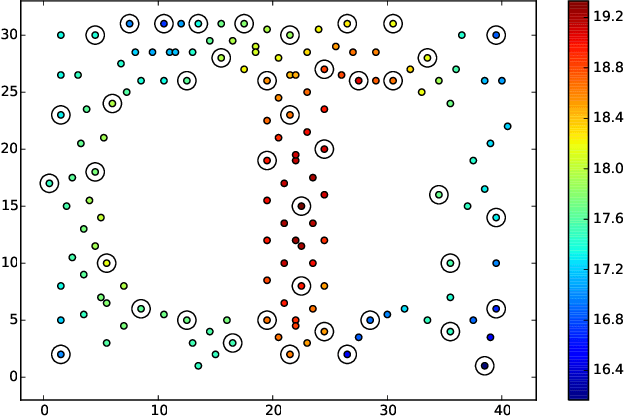
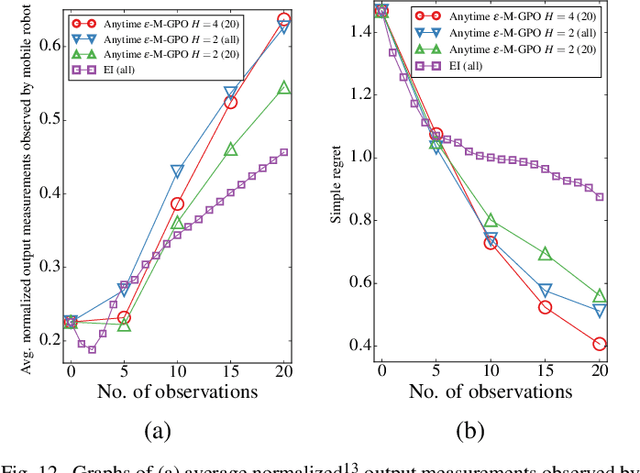
This paper presents a multi-staged approach to nonmyopic adaptive Gaussian process optimization (GPO) for Bayesian optimization (BO) of unknown, highly complex objective functions that, in contrast to existing nonmyopic adaptive BO algorithms, exploits the notion of macro-actions for scaling up to a further lookahead to match up to a larger available budget. To achieve this, we generalize GP upper confidence bound to a new acquisition function defined w.r.t. a nonmyopic adaptive macro-action policy, which is intractable to be optimized exactly due to an uncountable set of candidate outputs. The contribution of our work here is thus to derive a nonmyopic adaptive epsilon-Bayes-optimal macro-action GPO (epsilon-Macro-GPO) policy. To perform nonmyopic adaptive BO in real time, we then propose an asymptotically optimal anytime variant of our epsilon-Macro-GPO policy with a performance guarantee. We empirically evaluate the performance of our epsilon-Macro-GPO policy and its anytime variant in BO with synthetic and real-world datasets.
Scalable Variational Bayesian Kernel Selection for Sparse Gaussian Process Regression
Dec 05, 2019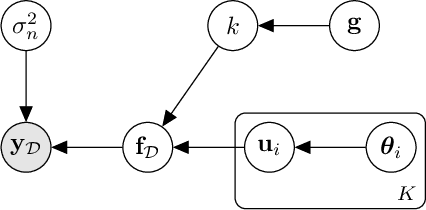


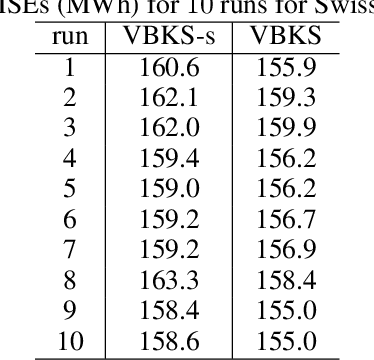
This paper presents a variational Bayesian kernel selection (VBKS) algorithm for sparse Gaussian process regression (SGPR) models. In contrast to existing GP kernel selection algorithms that aim to select only one kernel with the highest model evidence, our proposed VBKS algorithm considers the kernel as a random variable and learns its belief from data such that the uncertainty of the kernel can be interpreted and exploited to avoid overconfident GP predictions. To achieve this, we represent the probabilistic kernel as an additional variational variable in a variational inference (VI) framework for SGPR models where its posterior belief is learned together with that of the other variational variables (i.e., inducing variables and kernel hyperparameters). In particular, we transform the discrete kernel belief into a continuous parametric distribution via reparameterization in order to apply VI. Though it is computationally challenging to jointly optimize a large number of hyperparameters due to many kernels being evaluated simultaneously by our VBKS algorithm, we show that the variational lower bound of the log-marginal likelihood can be decomposed into an additive form such that each additive term depends only on a disjoint subset of the variational variables and can thus be optimized independently. Stochastic optimization is then used to maximize the variational lower bound by iteratively improving the variational approximation of the exact posterior belief via stochastic gradient ascent, which incurs constant time per iteration and hence scales to big data. We empirically evaluate the performance of our VBKS algorithm on synthetic and massive real-world datasets.
Inverse Reinforcement Learning with Missing Data
Nov 16, 2019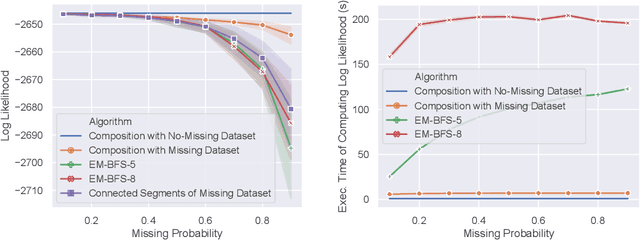
We consider the problem of recovering an expert's reward function with inverse reinforcement learning (IRL) when there are missing/incomplete state-action pairs or observations in the demonstrated trajectories. This issue of missing trajectory data or information occurs in many situations, e.g., GPS signals from vehicles moving on a road network are intermittent. In this paper, we propose a tractable approach to directly compute the log-likelihood of demonstrated trajectories with incomplete/missing data. Our algorithm is efficient in handling a large number of missing segments in the demonstrated trajectories, as it performs the training with incomplete data by solving a sequence of systems of linear equations, and the number of such systems to be solved does not depend on the number of missing segments. Empirical evaluation on a real-world dataset shows that our training algorithm outperforms other conventional techniques.
Implicit Posterior Variational Inference for Deep Gaussian Processes
Oct 26, 2019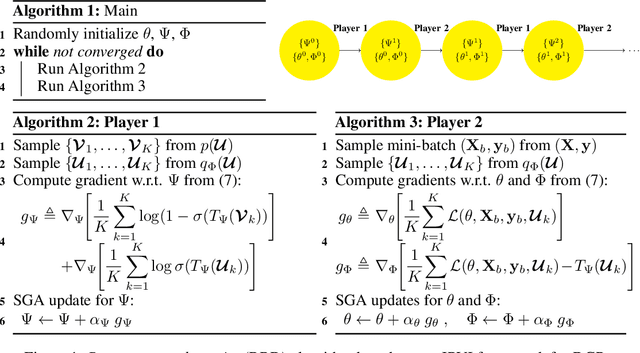
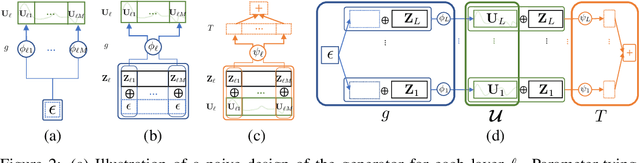
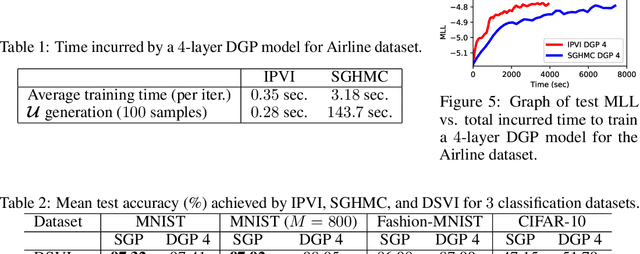
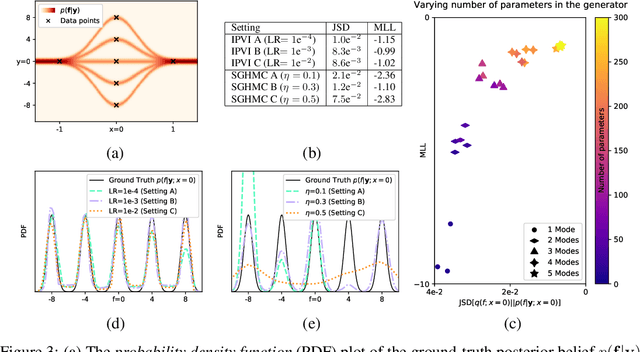
A multi-layer deep Gaussian process (DGP) model is a hierarchical composition of GP models with a greater expressive power. Exact DGP inference is intractable, which has motivated the recent development of deterministic and stochastic approximation methods. Unfortunately, the deterministic approximation methods yield a biased posterior belief while the stochastic one is computationally costly. This paper presents an implicit posterior variational inference (IPVI) framework for DGPs that can ideally recover an unbiased posterior belief and still preserve time efficiency. Inspired by generative adversarial networks, our IPVI framework achieves this by casting the DGP inference problem as a two-player game in which a Nash equilibrium, interestingly, coincides with an unbiased posterior belief. This consequently inspires us to devise a best-response dynamics algorithm to search for a Nash equilibrium (i.e., an unbiased posterior belief). Empirical evaluation shows that IPVI outperforms the state-of-the-art approximation methods for DGPs.
Bayesian Optimization with Binary Auxiliary Information
Jun 17, 2019
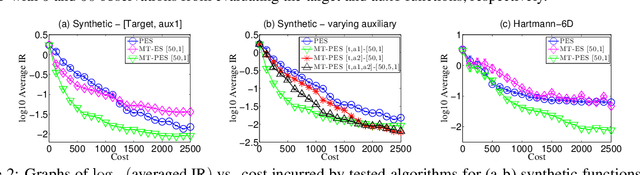
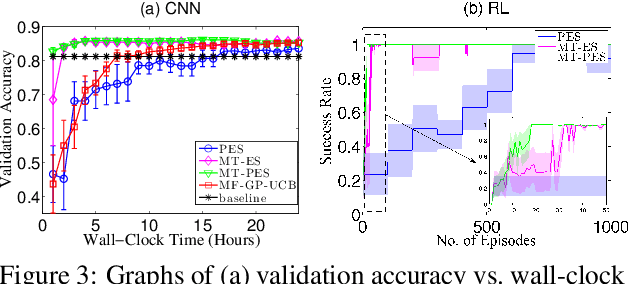
This paper presents novel mixed-type Bayesian optimization (BO) algorithms to accelerate the optimization of a target objective function by exploiting correlated auxiliary information of binary type that can be more cheaply obtained, such as in policy search for reinforcement learning and hyperparameter tuning of machine learning models with early stopping. To achieve this, we first propose a mixed-type multi-output Gaussian process (MOGP) to jointly model the continuous target function and binary auxiliary functions. Then, we propose information-based acquisition functions such as mixed-type entropy search (MT-ES) and mixed-type predictive ES (MT-PES) for mixed-type BO based on the MOGP predictive belief of the target and auxiliary functions. The exact acquisition functions of MT-ES and MT-PES cannot be computed in closed form and need to be approximated. We derive an efficient approximation of MT-PES via a novel mixed-type random features approximation of the MOGP model whose cross-correlation structure between the target and auxiliary functions can be exploited for improving the belief of the global target maximizer using observations from evaluating these functions. We propose new practical constraints to relate the global target maximizer to the binary auxiliary functions. We empirically evaluate the performance of MT-ES and MT-PES with synthetic and real-world experiments.
GEE: A Gradient-based Explainable Variational Autoencoder for Network Anomaly Detection
Mar 15, 2019
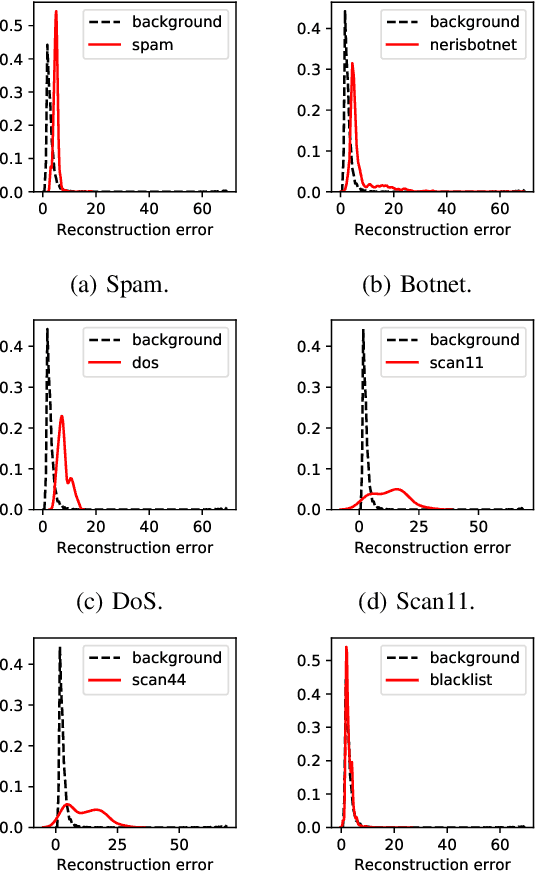
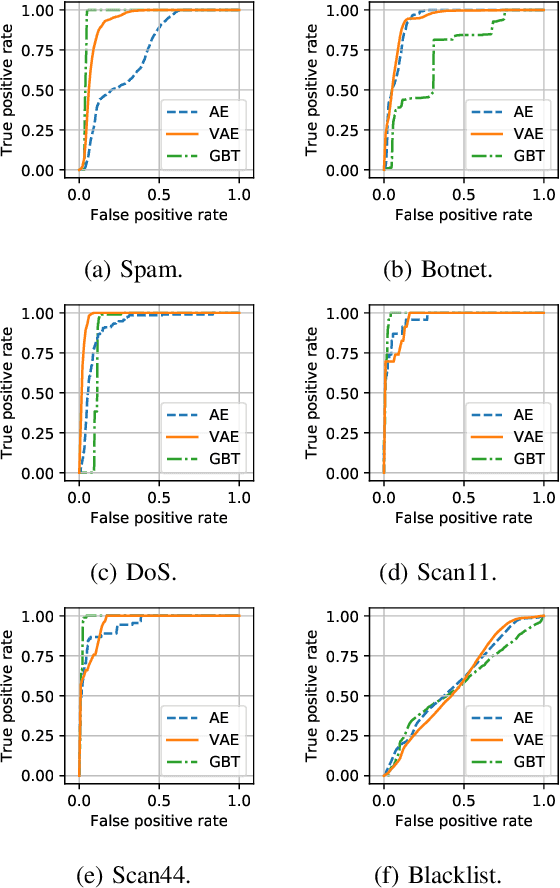
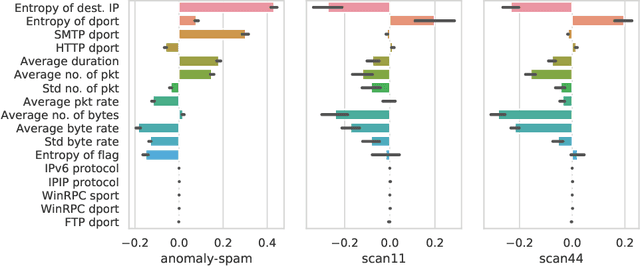
This paper looks into the problem of detecting network anomalies by analyzing NetFlow records. While many previous works have used statistical models and machine learning techniques in a supervised way, such solutions have the limitations that they require large amount of labeled data for training and are unlikely to detect zero-day attacks. Existing anomaly detection solutions also do not provide an easy way to explain or identify attacks in the anomalous traffic. To address these limitations, we develop and present GEE, a framework for detecting and explaining anomalies in network traffic. GEE comprises of two components: (i) Variational Autoencoder (VAE) - an unsupervised deep-learning technique for detecting anomalies, and (ii) a gradient-based fingerprinting technique for explaining anomalies. Evaluation of GEE on the recent UGR dataset demonstrates that our approach is effective in detecting different anomalies as well as identifying fingerprints that are good representations of these various attacks.
Towards Robust ResNet: A Small Step but A Giant Leap
Feb 28, 2019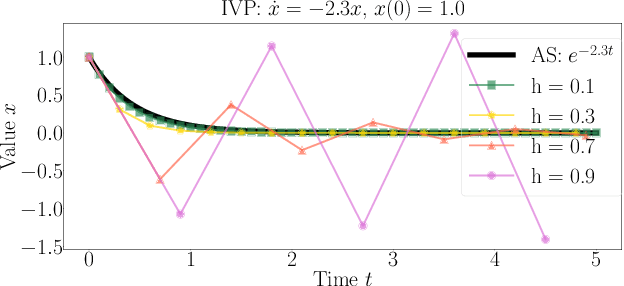
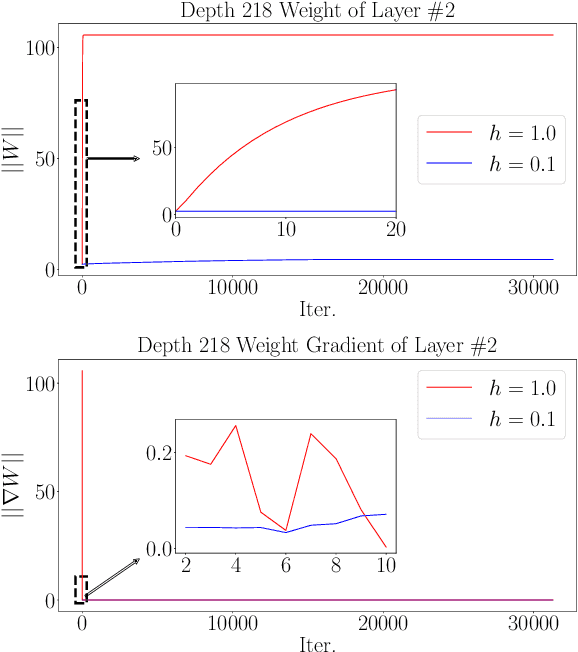
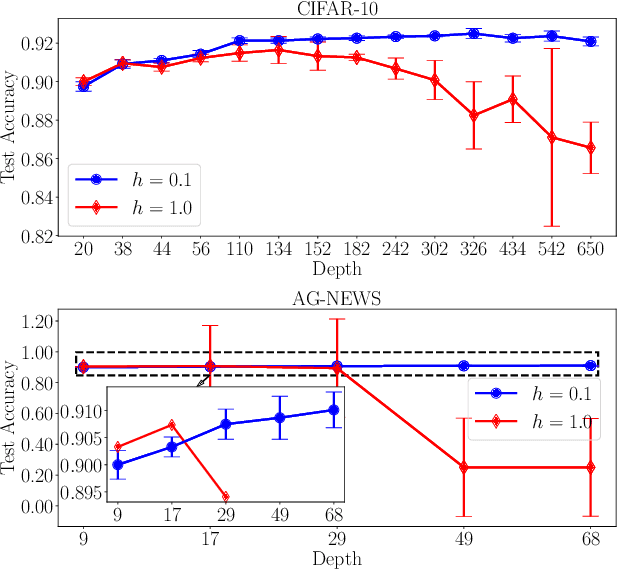

This paper presents a simple yet principled approach to boosting the robustness of the residual network (ResNet) that is motivated by the dynamical system perspective. Namely, a deep neural network can be interpreted using a partial differential equation, which naturally inspires us to characterize ResNet by an explicit Euler method. Our analytical studies reveal that the step factor h in the Euler method is able to control the robustness of ResNet in both its training and generalization. Specifically, we prove that a small step factor h can benefit the training robustness for back-propagation; from the view of forward-propagation, a small h can aid in the robustness of the model generalization. A comprehensive empirical evaluation on both vision CIFAR-10 and text AG-NEWS datasets confirms that a small h aids both the training and generalization robustness.