 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What to Do and What Not To Do: Offline Imitation from Expert and Undesirable Demonstrations
May 27, 2025Offline imitation learning typically learns from expert and unlabeled demonstrations, yet often overlooks the valuable signal in explicitly undesirable behaviors. In this work, we study offline imitation learning from contrasting behaviors, where the dataset contains both expert and undesirable demonstrations. We propose a novel formulation that optimizes a difference of KL divergences over the state-action visitation distributions of expert and undesirable (or bad) data. Although the resulting objective is a DC (Difference-of-Convex) program, we prove that it becomes convex when expert demonstrations outweigh undesirable demonstrations, enabling a practical and stable non-adversarial training objective. Our method avoids adversarial training and handles both positive and negative demonstrations in a unified framework. Extensive experiments on standard offline imitation learning benchmarks demonstrate that our approach consistently outperforms state-of-the-art baselines.
MisoDICE: Multi-Agent Imitation from Unlabeled Mixed-Quality Demonstrations
May 24, 2025We study offline imitation learning (IL) in cooperative multi-agent settings, where demonstrations have unlabeled mixed quality - containing both expert and suboptimal trajectories. Our proposed solution is structured in two stages: trajectory labeling and multi-agent imitation learning, designed jointly to enable effective learning from heterogeneous, unlabeled data. In the first stage, we combine advances in large language models and preference-based reinforcement learning to construct a progressive labeling pipeline that distinguishes expert-quality trajectories. In the second stage, we introduce MisoDICE, a novel multi-agent IL algorithm that leverages these labels to learn robust policies while addressing the computational complexity of large joint state-action spaces. By extending the popular single-agent DICE framework to multi-agent settings with a new value decomposition and mixing architecture, our method yields a convex policy optimization objective and ensures consistency between global and local policies. We evaluate MisoDICE on multiple standard multi-agent RL benchmarks and demonstrate superior performance, especially when expert data is scarce.
O-MAPL: Offline Multi-agent Preference Learning
Jan 31, 2025



Inferring reward functions from demonstrations is a key challenge in reinforcement learning (RL), particularly in multi-agent RL (MARL), where large joint state-action spaces and complex inter-agent interactions complicate the task. While prior single-agent studies have explored recovering reward functions and policies from human preferences, similar work in MARL is limited. Existing methods often involve separate stages of supervised reward learning and MARL algorithms, leading to unstable training. In this work, we introduce a novel end-to-end preference-based learning framework for cooperative MARL, leveraging the underlying connection between reward functions and soft Q-functions. Our approach uses a carefully-designed multi-agent value decomposition strategy to improve training efficiency. Extensive experiments on SMAC and MAMuJoCo benchmarks show that our algorithm outperforms existing methods across various tasks.
UNIQ: Offline Inverse Q-learning for Avoiding Undesirable Demonstrations
Oct 10, 2024We address the problem of offline learning a policy that avoids undesirable demonstrations. Unlike conventional offline imitation learning approaches that aim to imitate expert or near-optimal demonstrations, our setting involves avoiding undesirable behavior (specified using undesirable demonstrations). To tackle this problem, unlike standard imitation learning where the aim is to minimize the distance between learning policy and expert demonstrations, we formulate the learning task as maximizing a statistical distance, in the space of state-action stationary distributions, between the learning policy and the undesirable policy. This significantly different approach results in a novel training objective that necessitates a new algorithm to address it. Our algorithm, UNIQ, tackles these challenges by building on the inverse Q-learning framework, framing the learning problem as a cooperative (non-adversarial) task. We then demonstrate how to efficiently leverage unlabeled data for practical training. Our method is evaluated on standard benchmark environments, where it consistently outperforms state-of-the-art baselines. The code implementation can be accessed at: https://github.com/hmhuy0/UNIQ.
ComaDICE: Offline Cooperative Multi-Agent Reinforcement Learning with Stationary Distribution Shift Regularization
Oct 02, 2024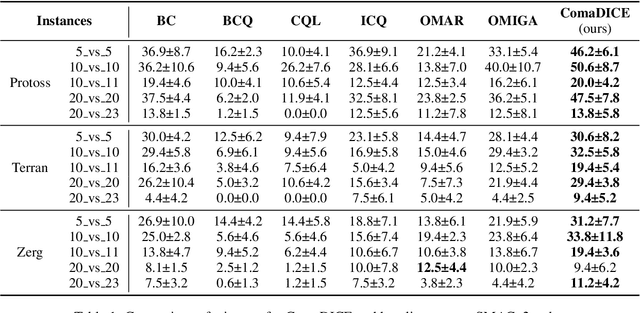
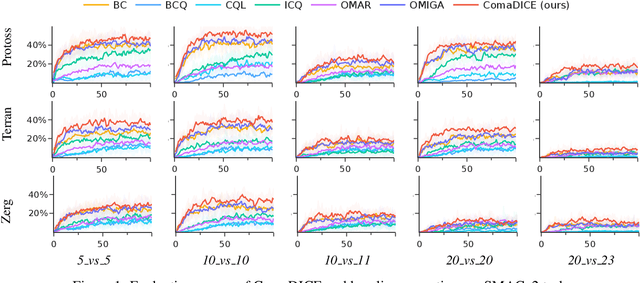
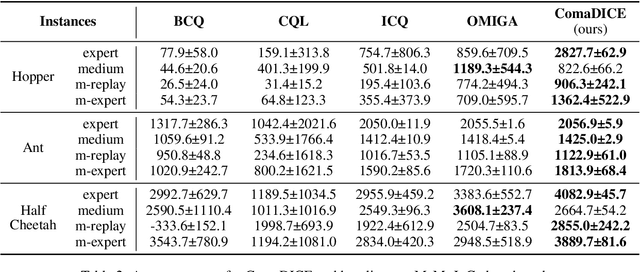

Offline reinforcement learning (RL) has garnered significant attention for its ability to learn effective policies from pre-collected datasets without the need for further environmental interactions. While promising results have been demonstrated in single-agent settings, offline multi-agent reinforcement learning (MARL) presents additional challenges due to the large joint state-action space and the complexity of multi-agent behaviors. A key issue in offline RL is the distributional shift, which arises when the target policy being optimized deviates from the behavior policy that generated the data. This problem is exacerbated in MARL due to the interdependence between agents' local policies and the expansive joint state-action space. Prior approaches have primarily addressed this challenge by incorporating regularization in the space of either Q-functions or policies. In this work, we introduce a regularizer in the space of stationary distributions to better handle distributional shift. Our algorithm, ComaDICE, offers a principled framework for offline cooperative MARL by incorporating stationary distribution regularization for the global learning policy, complemented by a carefully structured multi-agent value decomposition strategy to facilitate multi-agent training. Through extensive experiments on the multi-agent MuJoCo and StarCraft II benchmarks, we demonstrate that ComaDICE achieves superior performance compared to state-of-the-art offline MARL methods across nearly all tasks.
Outer Approximation and Super-modular Cuts for Constrained Assortment Optimization under Mixed-Logit Model
Jul 26, 2024In this paper, we study the assortment optimization problem under the mixed-logit customer choice model. While assortment optimization has been a major topic in revenue management for decades, the mixed-logit model is considered one of the most general and flexible approaches for modeling and predicting customer purchasing behavior. Existing exact methods have primarily relied on mixed-integer linear programming (MILP) or second-order cone (CONIC) reformulations, which allow for exact problem solving using off-the-shelf solvers. However, these approaches often suffer from weak continuous relaxations and are slow when solving large instances. Our work addresses the problem by focusing on components of the objective function that can be proven to be monotonically super-modular and convex. This allows us to derive valid cuts to outer-approximate the nonlinear objective functions. We then demonstrate that these valid cuts can be incorporated into Cutting Plane or Branch-and-Cut methods to solve the problem exactly. Extensive experiments show that our approaches consistently outperform previous methods in terms of both solution quality and computation time.
Competitive Facility Location under Random Utilities and Routing Constraints
Mar 09, 2024



In this paper, we study a facility location problem within a competitive market context, where customer demand is predicted by a random utility choice model. Unlike prior research, which primarily focuses on simple constraints such as a cardinality constraint on the number of selected locations, we introduce routing constraints that necessitate the selection of locations in a manner that guarantees the existence of a tour visiting all chosen locations while adhering to a specified tour length upper bound. Such routing constraints find crucial applications in various real-world scenarios. The problem at hand features a non-linear objective function, resulting from the utilization of random utilities, together with complex routing constraints, making it computationally challenging. To tackle this problem, we explore three types of valid cuts, namely, outer-approximation and submodular cuts to handle the nonlinear objective function, as well as sub-tour elimination cuts to address the complex routing constraints. These lead to the development of two exact solution methods: a nested cutting plane and nested branch-and-cut algorithms, where these valid cuts are iteratively added to a master problem through two nested loops. We also prove that our nested cutting plane method always converges to optimality after a finite number of iterations. Furthermore, we develop a local search-based metaheuristic tailored for solving large-scale instances and show its pros and cons compared to exact methods. Extensive experiments are conducted on problem instances of varying sizes, demonstrating that our approach excels in terms of solution quality and computation time when compared to other baseline approaches.
SubIQ: Inverse Soft-Q Learning for Offline Imitation with Suboptimal Demonstrations
Feb 20, 2024



We consider offline imitation learning (IL), which aims to mimic the expert's behavior from its demonstration without further interaction with the environment. One of the main challenges in offline IL is dealing with the limited support of expert demonstrations that cover only a small fraction of the state-action spaces. In this work, we consider offline IL, where expert demonstrations are limited but complemented by a larger set of sub-optimal demonstrations of lower expertise levels. Most of the existing offline IL methods developed for this setting are based on behavior cloning or distribution matching, where the aim is to match the occupancy distribution of the imitation policy with that of the expert policy. Such an approach often suffers from over-fitting, as expert demonstrations are limited to accurately represent any occupancy distribution. On the other hand, since sub-optimal sets are much larger, there is a high chance that the imitation policy is trained towards sub-optimal policies. In this paper, to address these issues, we propose a new approach based on inverse soft-Q learning, where a regularization term is added to the training objective, with the aim of aligning the learned rewards with a pre-assigned reward function that allocates higher weights to state-action pairs from expert demonstrations, and lower weights to those from lower expertise levels. On standard benchmarks, our inverse soft-Q learning significantly outperforms other offline IL baselines by a large margin.
Imitate the Good and Avoid the Bad: An Incremental Approach to Safe Reinforcement Learning
Dec 26, 2023A popular framework for enforcing safe actions in Reinforcement Learning (RL) is Constrained RL, where trajectory based constraints on expected cost (or other cost measures) are employed to enforce safety and more importantly these constraints are enforced while maximizing expected reward. Most recent approaches for solving Constrained RL convert the trajectory based cost constraint into a surrogate problem that can be solved using minor modifications to RL methods. A key drawback with such approaches is an over or underestimation of the cost constraint at each state. Therefore, we provide an approach that does not modify the trajectory based cost constraint and instead imitates ``good'' trajectories and avoids ``bad'' trajectories generated from incrementally improving policies. We employ an oracle that utilizes a reward threshold (which is varied with learning) and the overall cost constraint to label trajectories as ``good'' or ``bad''. A key advantage of our approach is that we are able to work from any starting policy or set of trajectories and improve on it. In an exhaustive set of experiments, we demonstrate that our approach is able to outperform top benchmark approaches for solving Constrained RL problems, with respect to expected cost, CVaR cost, or even unknown cost constraints.
Inverse Factorized Q-Learning for Cooperative Multi-agent Imitation Learning
Oct 10, 2023This paper concerns imitation learning (IL) (i.e, the problem of learning to mimic expert behaviors from demonstrations) in cooperative multi-agent systems. The learning problem under consideration poses several challenges, characterized by high-dimensional state and action spaces and intricate inter-agent dependencies. In a single-agent setting, IL has proven to be done efficiently through an inverse soft-Q learning process given expert demonstrations. However, extending this framework to a multi-agent context introduces the need to simultaneously learn both local value functions to capture local observations and individual actions, and a joint value function for exploiting centralized learning. In this work, we introduce a novel multi-agent IL algorithm designed to address these challenges. Our approach enables the centralized learning by leveraging mixing networks to aggregate decentralized Q functions. A main advantage of this approach is that the weights of the mixing networks can be trained using information derived from global states. We further establish conditions for the mixing networks under which the multi-agent objective function exhibits convexity within the Q function space. We present extensive experiments conducted on some challenging competitive and cooperative multi-agent game environments, including an advanced version of the Star-Craft multi-agent challenge (i.e., SMACv2), which demonstrates the effectiveness of our proposed algorithm compared to existing state-of-the-art multi-agent IL algorithms.