 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiMAP-Travel: Hierarchical Multi-Agent Planning for Long-Horizon Constrained Travel
Mar 05, 2026Sequential LLM agents fail on long-horizon planning with hard constraints like budgets and diversity requirements. As planning progresses and context grows, these agents drift from global constraints. We propose HiMAP-Travel, a hierarchical multi-agent framework that splits planning into strategic coordination and parallel day-level execution. A Coordinator allocates resources across days, while Day Executors plan independently in parallel. Three key mechanisms enable this: a transactional monitor enforcing budget and uniqueness constraints across parallel agents, a bargaining protocol allowing agents to reject infeasible sub-goals and trigger re-planning, and a single policy trained with GRPO that powers all agents through role conditioning. On TravelPlanner, HiMAP-Travel with Qwen3-8B achieves 52.78% validation and 52.65% test Final Pass Rate (FPR). In a controlled comparison with identical model, training, and tools, it outperforms the sequential DeepTravel baseline by +8.67~pp. It also surpasses ATLAS by +17.65~pp and MTP by +10.0~pp. On FlexTravelBench multi-turn scenarios, it achieves 44.34% (2-turn) and 37.42% (3-turn) FPR while reducing latency 2.5x through parallelization.
MisoDICE: Multi-Agent Imitation from Unlabeled Mixed-Quality Demonstrations
May 24, 2025We study offline imitation learning (IL) in cooperative multi-agent settings, where demonstrations have unlabeled mixed quality - containing both expert and suboptimal trajectories. Our proposed solution is structured in two stages: trajectory labeling and multi-agent imitation learning, designed jointly to enable effective learning from heterogeneous, unlabeled data. In the first stage, we combine advances in large language models and preference-based reinforcement learning to construct a progressive labeling pipeline that distinguishes expert-quality trajectories. In the second stage, we introduce MisoDICE, a novel multi-agent IL algorithm that leverages these labels to learn robust policies while addressing the computational complexity of large joint state-action spaces. By extending the popular single-agent DICE framework to multi-agent settings with a new value decomposition and mixing architecture, our method yields a convex policy optimization objective and ensures consistency between global and local policies. We evaluate MisoDICE on multiple standard multi-agent RL benchmarks and demonstrate superior performance, especially when expert data is scarce.
O-MAPL: Offline Multi-agent Preference Learning
Jan 31, 2025



Inferring reward functions from demonstrations is a key challenge in reinforcement learning (RL), particularly in multi-agent RL (MARL), where large joint state-action spaces and complex inter-agent interactions complicate the task. While prior single-agent studies have explored recovering reward functions and policies from human preferences, similar work in MARL is limited. Existing methods often involve separate stages of supervised reward learning and MARL algorithms, leading to unstable training. In this work, we introduce a novel end-to-end preference-based learning framework for cooperative MARL, leveraging the underlying connection between reward functions and soft Q-functions. Our approach uses a carefully-designed multi-agent value decomposition strategy to improve training efficiency. Extensive experiments on SMAC and MAMuJoCo benchmarks show that our algorithm outperforms existing methods across various tasks.
ComaDICE: Offline Cooperative Multi-Agent Reinforcement Learning with Stationary Distribution Shift Regularization
Oct 02, 2024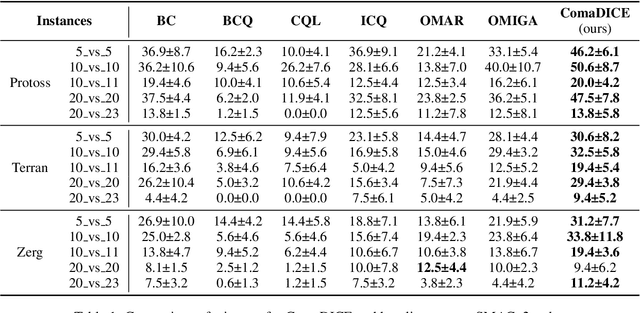
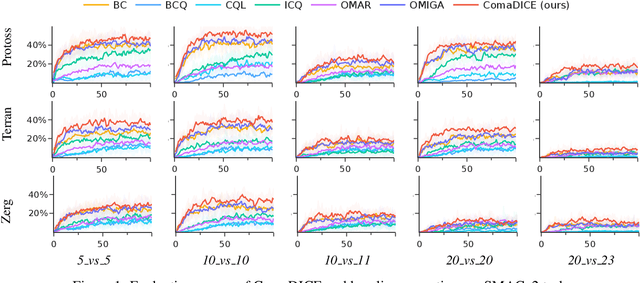
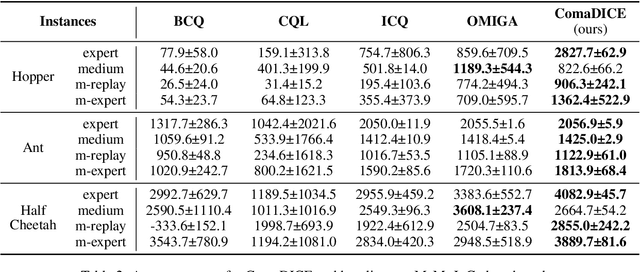

Offline reinforcement learning (RL) has garnered significant attention for its ability to learn effective policies from pre-collected datasets without the need for further environmental interactions. While promising results have been demonstrated in single-agent settings, offline multi-agent reinforcement learning (MARL) presents additional challenges due to the large joint state-action space and the complexity of multi-agent behaviors. A key issue in offline RL is the distributional shift, which arises when the target policy being optimized deviates from the behavior policy that generated the data. This problem is exacerbated in MARL due to the interdependence between agents' local policies and the expansive joint state-action space. Prior approaches have primarily addressed this challenge by incorporating regularization in the space of either Q-functions or policies. In this work, we introduce a regularizer in the space of stationary distributions to better handle distributional shift. Our algorithm, ComaDICE, offers a principled framework for offline cooperative MARL by incorporating stationary distribution regularization for the global learning policy, complemented by a carefully structured multi-agent value decomposition strategy to facilitate multi-agent training. Through extensive experiments on the multi-agent MuJoCo and StarCraft II benchmarks, we demonstrate that ComaDICE achieves superior performance compared to state-of-the-art offline MARL methods across nearly all tasks.
Inverse Factorized Q-Learning for Cooperative Multi-agent Imitation Learning
Oct 10, 2023This paper concerns imitation learning (IL) (i.e, the problem of learning to mimic expert behaviors from demonstrations) in cooperative multi-agent systems. The learning problem under consideration poses several challenges, characterized by high-dimensional state and action spaces and intricate inter-agent dependencies. In a single-agent setting, IL has proven to be done efficiently through an inverse soft-Q learning process given expert demonstrations. However, extending this framework to a multi-agent context introduces the need to simultaneously learn both local value functions to capture local observations and individual actions, and a joint value function for exploiting centralized learning. In this work, we introduce a novel multi-agent IL algorithm designed to address these challenges. Our approach enables the centralized learning by leveraging mixing networks to aggregate decentralized Q functions. A main advantage of this approach is that the weights of the mixing networks can be trained using information derived from global states. We further establish conditions for the mixing networks under which the multi-agent objective function exhibits convexity within the Q function space. We present extensive experiments conducted on some challenging competitive and cooperative multi-agent game environments, including an advanced version of the Star-Craft multi-agent challenge (i.e., SMACv2), which demonstrates the effectiveness of our proposed algorithm compared to existing state-of-the-art multi-agent IL algorithms.
Mimicking To Dominate: Imitation Learning Strategies for Success in Multiagent Competitive Games
Aug 20, 2023Training agents in multi-agent competitive games presents significant challenges due to their intricate nature. These challenges are exacerbated by dynamics influenced not only by the environment but also by opponents' strategies. Existing methods often struggle with slow convergence and instability. To address this, we harness the potential of imitation learning to comprehend and anticipate opponents' behavior, aiming to mitigate uncertainties with respect to the game dynamics. Our key contributions include: (i) a new multi-agent imitation learning model for predicting next moves of the opponents -- our model works with hidden opponents' actions and local observations; (ii) a new multi-agent reinforcement learning algorithm that combines our imitation learning model and policy training into one single training process; and (iii) extensive experiments in three challenging game environments, including an advanced version of the Star-Craft multi-agent challenge (i.e., SMACv2). Experimental results show that our approach achieves superior performance compared to existing state-of-the-art multi-agent RL algorithms.
Imitating Opponent to Win: Adversarial Policy Imitation Learning in Two-player Competitive Games
Oct 30, 2022



Recent research on vulnerabilities of deep reinforcement learning (RL) has shown that adversarial policies adopted by an adversary agent can influence a target RL agent (victim agent) to perform poorly in a multi-agent environment. In existing studies, adversarial policies are directly trained based on experiences of interacting with the victim agent. There is a key shortcoming of this approach; knowledge derived from historical interactions may not be properly generalized to unexplored policy regions of the victim agent, making the trained adversarial policy significantly less effective. In this work, we design a new effective adversarial policy learning algorithm that overcomes this shortcoming. The core idea of our new algorithm is to create a new imitator to imitate the victim agent's policy while the adversarial policy will be trained not only based on interactions with the victim agent but also based on feedback from the imitator to forecast victim's intention. By doing so, we can leverage the capability of imitation learning in well capturing underlying characteristics of the victim policy only based on sample trajectories of the victim. Our victim imitation learning model differs from prior models as the environment's dynamics are driven by adversary's policy and will keep changing during the adversarial policy training. We provide a provable bound to guarantee a desired imitating policy when the adversary's policy becomes stable. We further strengthen our adversarial policy learning by making our imitator a stronger version of the victim. Finally, our extensive experiments using four competitive MuJoCo game environments show that our proposed adversarial policy learning algorithm outperforms state-of-the-art algorithms.
Weighted Maximum Entropy Inverse Reinforcement Learning
Aug 20, 2022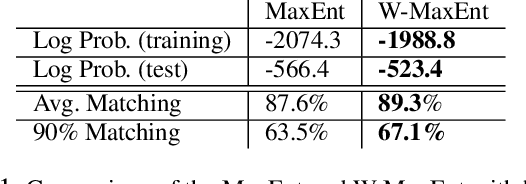
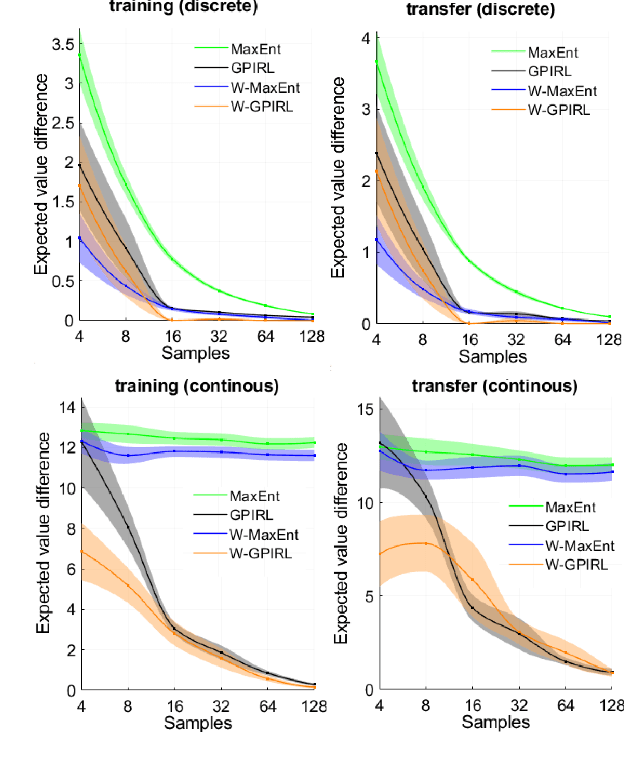

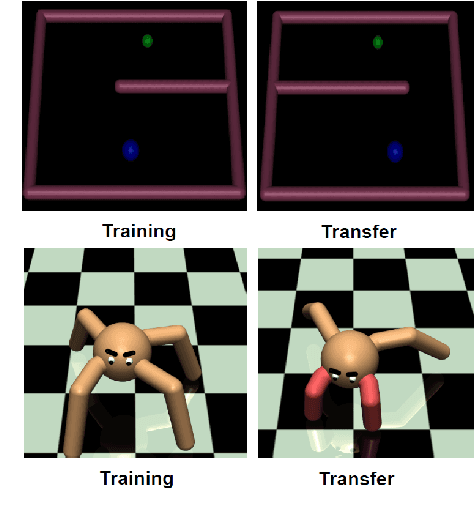
We study inverse reinforcement learning (IRL) and imitation learning (IM), the problems of recovering a reward or policy function from expert's demonstrated trajectories. We propose a new way to improve the learning process by adding a weight function to the maximum entropy framework, with the motivation of having the ability to learn and recover the stochasticity (or the bounded rationality) of the expert policy. Our framework and algorithms allow to learn both a reward (or policy) function and the structure of the entropy terms added to the Markov Decision Processes, thus enhancing the learning procedure. Our numerical experiments using human and simulated demonstrations and with discrete and continuous IRL/IM tasks show that our approach outperforms prior algorithms.
Cross-lingual Extended Named Entity Classification of Wikipedia Articles
Oct 17, 2020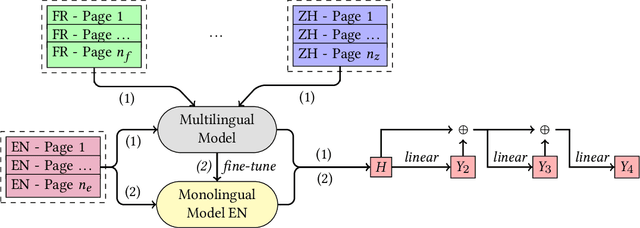


The FPT.AI team participated in the SHINRA2020-ML subtask of the NTCIR-15 SHINRA task. This paper describes our method to solving the problem and discusses the official results. Our method focuses on learning cross-lingual representations, both on the word level and document level for page classification. We propose a three-stage approach including multilingual model pre-training, monolingual model fine-tuning and cross-lingual voting. Our system is able to achieve the best scores for 25 out of 30 languages; and its accuracy gaps to the best performing systems of the other five languages are relatively small.