 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Maximum Entropy Inverse Reinforcement Learning
Paper and Code
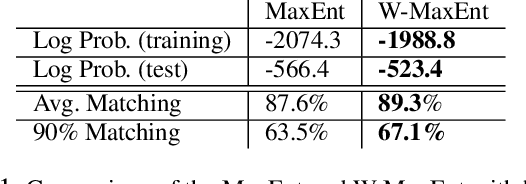
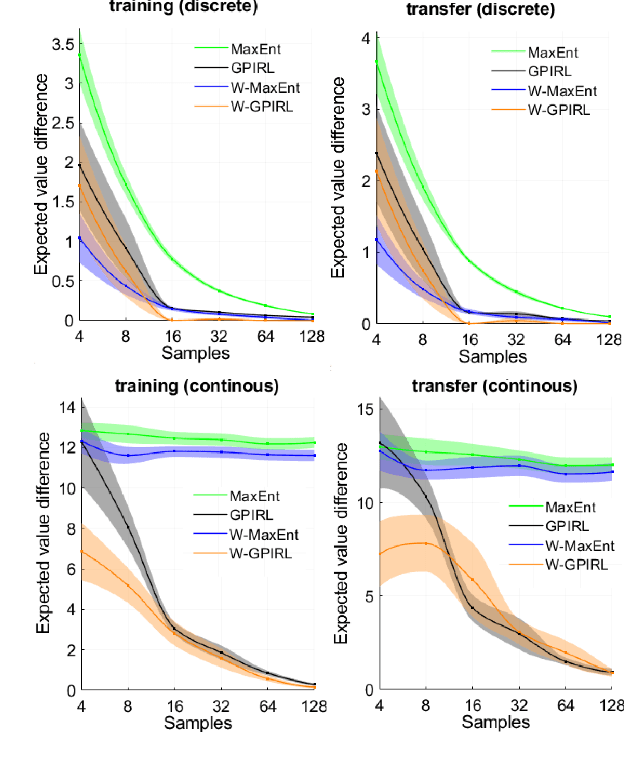

We study inverse reinforcement learning (IRL) and imitation learning (IM), the problems of recovering a reward or policy function from expert's demonstrated trajectories. We propose a new way to improve the learning process by adding a weight function to the maximum entropy framework, with the motivation of having the ability to learn and recover the stochasticity (or the bounded rationality) of the expert policy. Our framework and algorithms allow to learn both a reward (or policy) function and the structure of the entropy terms added to the Markov Decision Processes, thus enhancing the learning procedure. Our numerical experiments using human and simulated demonstrations and with discrete and continuous IRL/IM tasks show that our approach outperforms prior algorithms.