 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitating Opponent to Win: Adversarial Policy Imitation Learning in Two-player Competitive Games
Oct 30, 2022



Recent research on vulnerabilities of deep reinforcement learning (RL) has shown that adversarial policies adopted by an adversary agent can influence a target RL agent (victim agent) to perform poorly in a multi-agent environment. In existing studies, adversarial policies are directly trained based on experiences of interacting with the victim agent. There is a key shortcoming of this approach; knowledge derived from historical interactions may not be properly generalized to unexplored policy regions of the victim agent, making the trained adversarial policy significantly less effective. In this work, we design a new effective adversarial policy learning algorithm that overcomes this shortcoming. The core idea of our new algorithm is to create a new imitator to imitate the victim agent's policy while the adversarial policy will be trained not only based on interactions with the victim agent but also based on feedback from the imitator to forecast victim's intention. By doing so, we can leverage the capability of imitation learning in well capturing underlying characteristics of the victim policy only based on sample trajectories of the victim. Our victim imitation learning model differs from prior models as the environment's dynamics are driven by adversary's policy and will keep changing during the adversarial policy training. We provide a provable bound to guarantee a desired imitating policy when the adversary's policy becomes stable. We further strengthen our adversarial policy learning by making our imitator a stronger version of the victim. Finally, our extensive experiments using four competitive MuJoCo game environments show that our proposed adversarial policy learning algorithm outperforms state-of-the-art algorithms.
The Art of Manipulation: Threat of Multi-Step Manipulative Attacks in Security Games
Mar 01, 2022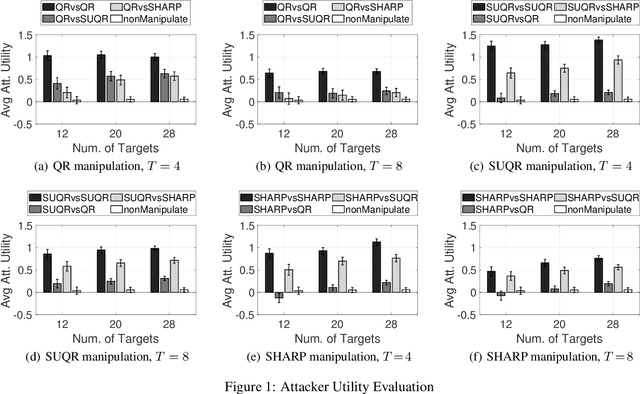
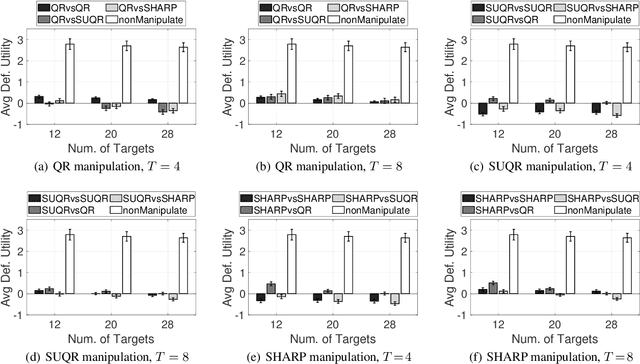
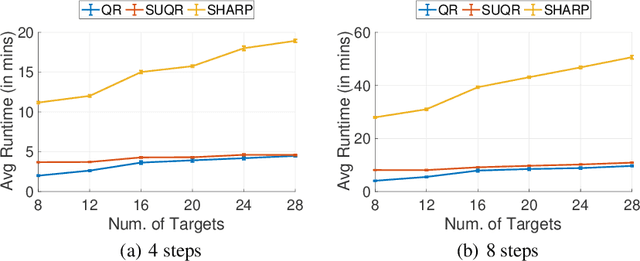
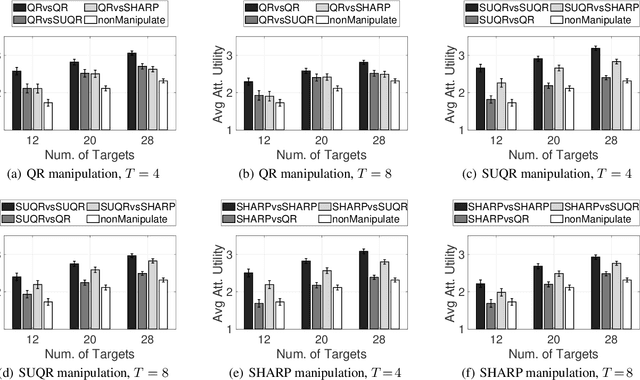
This paper studies the problem of multi-step manipulative attacks in Stackelberg security games, in which a clever attacker attempts to orchestrate its attacks over multiple time steps to mislead the defender's learning of the attacker's behavior. This attack manipulation eventually influences the defender's patrol strategy towards the attacker's benefit. Previous work along this line of research only focuses on one-shot games in which the defender learns the attacker's behavior and then designs a corresponding strategy only once. Our work, on the other hand, investigates the long-term impact of the attacker's manipulation in which current attack and defense choices of players determine the future learning and patrol planning of the defender. This paper has three key contributions. First, we introduce a new multi-step manipulative attack game model that captures the impact of sequential manipulative attacks carried out by the attacker over the entire time horizon. Second, we propose a new algorithm to compute an optimal manipulative attack plan for the attacker, which tackles the challenge of multiple connected optimization components involved in the computation across multiple time steps. Finally, we present extensive experimental results on the impact of such misleading attacks, showing a significant benefit for the attacker and loss for the defender.
Algorithmic Information Design in Multi-Player Games: Possibility and Limits in Singleton Congestion
Sep 25, 2021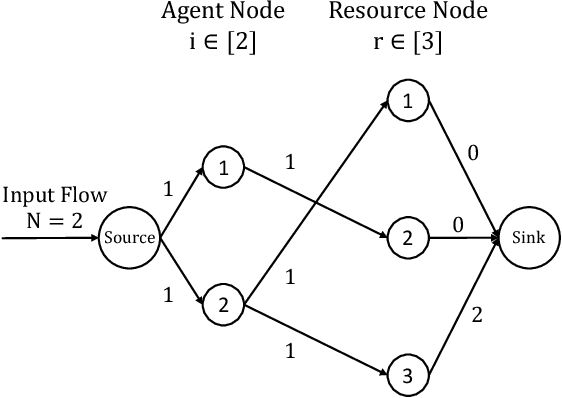


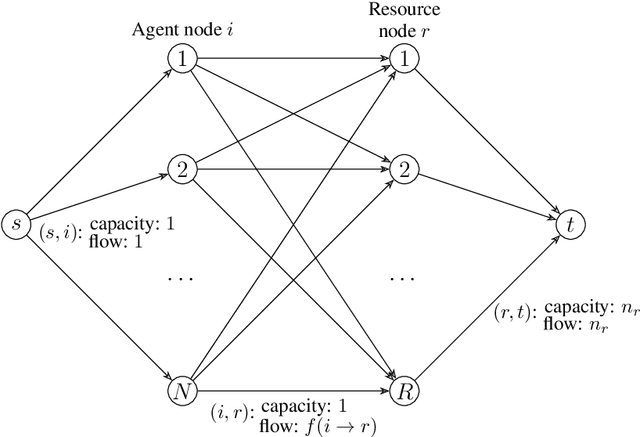
Most algorithmic studies on multi-agent information design so far have focused on the restricted situation with no inter-agent externalities; a few exceptions investigated special game classes such as zero-sum games and second-price auctions but have all focused only on optimal public signaling and exhibit sweepingly negative results. This paper initiates the algorithmic information design of both \emph{public} and \emph{private} signaling in a fundamental class of games with negative externalities, i.e., atomic singleton congestion games, with wide application in today's digital economy, machine scheduling, routing, etc. For both public and private signaling, we show that the optimal information design can be efficiently computed when the number of resources is a constant. To our knowledge, this is the first set of computationally efficient algorithms for information design in succinctly representable many-player games. Our results hinge on novel techniques such as developing ``reduced forms'' to compactly represent players' marginal beliefs. When there are many resources, we show computational intractability results. To overcome the challenge of multiple equilibria, here we introduce a new notion of equilibrium-\emph{oblivious} NP-hardness, which rules out any possibility of computing a good signaling scheme, irrespective of the equilibrium selection rule.