 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Manipulation: Threat of Multi-Step Manipulative Attacks in Security Games
Paper and Code
Mar 01, 2022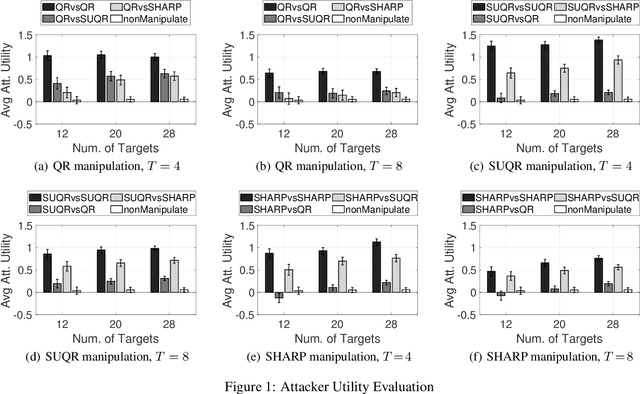
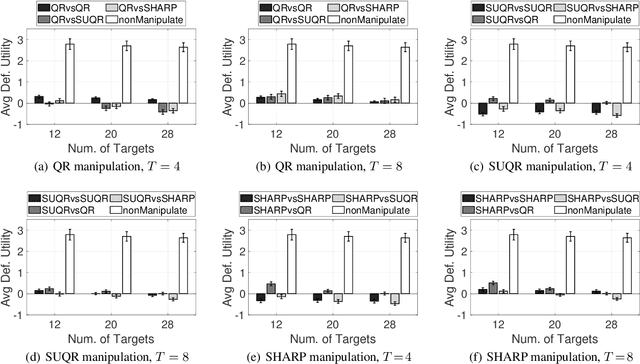
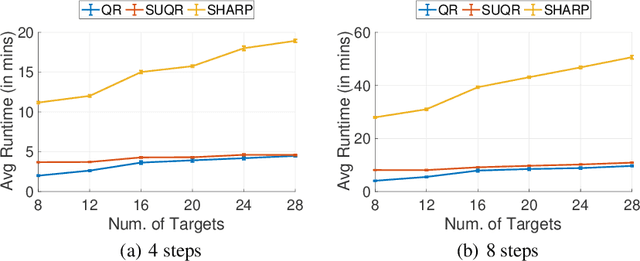
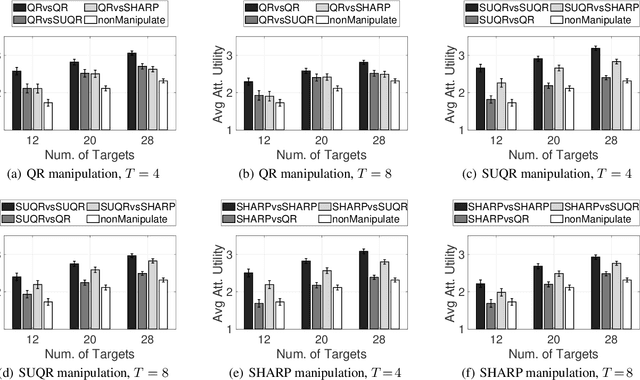
This paper studies the problem of multi-step manipulative attacks in Stackelberg security games, in which a clever attacker attempts to orchestrate its attacks over multiple time steps to mislead the defender's learning of the attacker's behavior. This attack manipulation eventually influences the defender's patrol strategy towards the attacker's benefit. Previous work along this line of research only focuses on one-shot games in which the defender learns the attacker's behavior and then designs a corresponding strategy only once. Our work, on the other hand, investigates the long-term impact of the attacker's manipulation in which current attack and defense choices of players determine the future learning and patrol planning of the defender. This paper has three key contributions. First, we introduce a new multi-step manipulative attack game model that captures the impact of sequential manipulative attacks carried out by the attacker over the entire time horizon. Second, we propose a new algorithm to compute an optimal manipulative attack plan for the attacker, which tackles the challenge of multiple connected optimization components involved in the computation across multiple time steps. Finally, we present extensive experimental results on the impact of such misleading attacks, showing a significant benefit for the attacker and loss for the defender.