 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPIC: Matryoshka Representation Learning via Self-Distilled Intra-Relational and Progressive Information Chaining
Apr 27, 2026Representation learning is fundamental to NLP, but building embeddings that work well at different computational budgets is challenging. Matryoshka Representation Learning (MRL) offers a flexible inference paradigm through nested embeddings; however, learning such structures requires explicit coordination of how information is arranged across embedding dimensionality and model depth. In this work, we propose MIPIC (Matryoshka Representation Learning via Self-Distilled Intra-Relational Alignment and Progressive Information Chaining), a unified training framework designed to produce structurally coherent and semantically compact Matryoshka representations. MIPIC promotes cross-dimensional structural consistency through Self-Distilled Intra-Relational Alignment (SIA), which aligns token-level geometric and attention-driven relations between full and truncated representations using top-k CKA self-distillation. Complementarily, it enables depth-wise semantic consolidation via Progressive Information Chaining (PIC), a scaffolded alignment strategy that incrementally transfers mature task semantics from deeper layers into earlier layers. Extensive experiments on STS, NLI, and classification benchmarks (spanning models from TinyBERT to BGEM3, Qwen3) demonstrate that MIPIC yields Matryoshka representations that are highly competitive across all capacities, with significant performance advantages observed under extreme low-dimensional.
CTPD: Cross Tokenizer Preference Distillation
Jan 17, 2026While knowledge distillation has seen widespread use in pre-training and instruction tuning, its application to aligning language models with human preferences remains underexplored, particularly in the more realistic cross-tokenizer setting. The incompatibility of tokenization schemes between teacher and student models has largely prevented fine-grained, white-box distillation of preference information. To address this gap, we propose Cross-Tokenizer Preference Distillation (CTPD), the first unified framework for transferring human-aligned behavior between models with heterogeneous tokenizers. CTPD introduces three key innovations: (1) Aligned Span Projection, which maps teacher and student tokens to shared character-level spans for precise supervision transfer; (2) a cross-tokenizer adaptation of Token-level Importance Sampling (TIS-DPO) for improved credit assignment; and (3) a Teacher-Anchored Reference, allowing the student to directly leverage the teacher's preferences in a DPO-style objective. Our theoretical analysis grounds CTPD in importance sampling, and experiments across multiple benchmarks confirm its effectiveness, with significant performance gains over existing methods. These results establish CTPD as a practical and general solution for preference distillation across diverse tokenization schemes, opening the door to more accessible and efficient alignment of language models.
ComaDICE: Offline Cooperative Multi-Agent Reinforcement Learning with Stationary Distribution Shift Regularization
Oct 02, 2024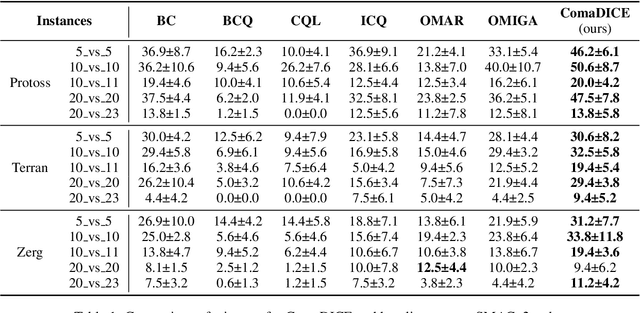
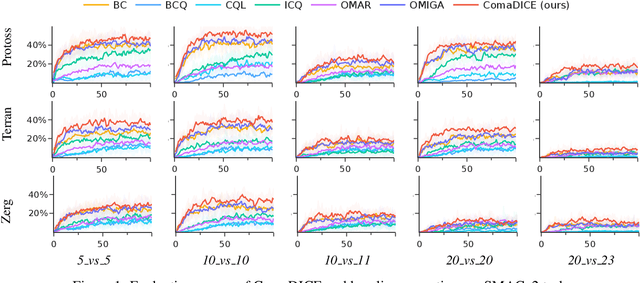
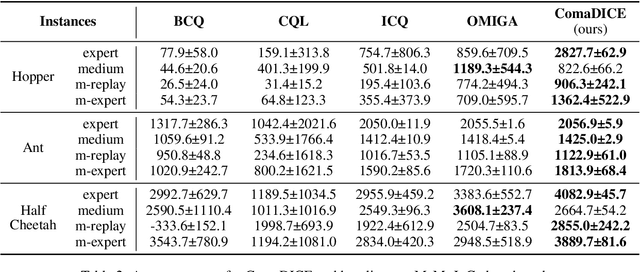

Offline reinforcement learning (RL) has garnered significant attention for its ability to learn effective policies from pre-collected datasets without the need for further environmental interactions. While promising results have been demonstrated in single-agent settings, offline multi-agent reinforcement learning (MARL) presents additional challenges due to the large joint state-action space and the complexity of multi-agent behaviors. A key issue in offline RL is the distributional shift, which arises when the target policy being optimized deviates from the behavior policy that generated the data. This problem is exacerbated in MARL due to the interdependence between agents' local policies and the expansive joint state-action space. Prior approaches have primarily addressed this challenge by incorporating regularization in the space of either Q-functions or policies. In this work, we introduce a regularizer in the space of stationary distributions to better handle distributional shift. Our algorithm, ComaDICE, offers a principled framework for offline cooperative MARL by incorporating stationary distribution regularization for the global learning policy, complemented by a carefully structured multi-agent value decomposition strategy to facilitate multi-agent training. Through extensive experiments on the multi-agent MuJoCo and StarCraft II benchmarks, we demonstrate that ComaDICE achieves superior performance compared to state-of-the-art offline MARL methods across nearly all tasks.
Generative Modelling of Stochastic Actions with Arbitrary Constraints in Reinforcement Learning
Nov 26, 2023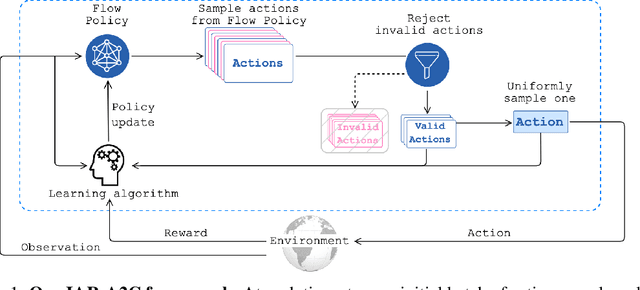
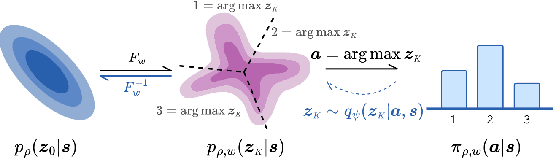
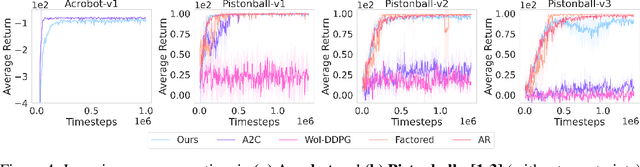
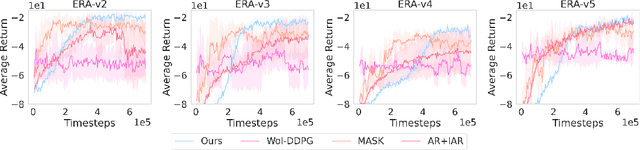
Many problems in Reinforcement Learning (RL) seek an optimal policy with large discrete multidimensional yet unordered action spaces; these include problems in randomized allocation of resources such as placements of multiple security resources and emergency response units, etc. A challenge in this setting is that the underlying action space is categorical (discrete and unordered) and large, for which existing RL methods do not perform well. Moreover, these problems require validity of the realized action (allocation); this validity constraint is often difficult to express compactly in a closed mathematical form. The allocation nature of the problem also prefers stochastic optimal policies, if one exists. In this work, we address these challenges by (1) applying a (state) conditional normalizing flow to compactly represent the stochastic policy -- the compactness arises due to the network only producing one sampled action and the corresponding log probability of the action, which is then used by an actor-critic method; and (2) employing an invalid action rejection method (via a valid action oracle) to update the base policy. The action rejection is enabled by a modified policy gradient that we derive. Finally, we conduct extensive experiments to show the scalability of our approach compared to prior methods and the ability to enforce arbitrary state-conditional constraints on the support of the distribution of actions in any state.
Inverse Factorized Q-Learning for Cooperative Multi-agent Imitation Learning
Oct 10, 2023This paper concerns imitation learning (IL) (i.e, the problem of learning to mimic expert behaviors from demonstrations) in cooperative multi-agent systems. The learning problem under consideration poses several challenges, characterized by high-dimensional state and action spaces and intricate inter-agent dependencies. In a single-agent setting, IL has proven to be done efficiently through an inverse soft-Q learning process given expert demonstrations. However, extending this framework to a multi-agent context introduces the need to simultaneously learn both local value functions to capture local observations and individual actions, and a joint value function for exploiting centralized learning. In this work, we introduce a novel multi-agent IL algorithm designed to address these challenges. Our approach enables the centralized learning by leveraging mixing networks to aggregate decentralized Q functions. A main advantage of this approach is that the weights of the mixing networks can be trained using information derived from global states. We further establish conditions for the mixing networks under which the multi-agent objective function exhibits convexity within the Q function space. We present extensive experiments conducted on some challenging competitive and cooperative multi-agent game environments, including an advanced version of the Star-Craft multi-agent challenge (i.e., SMACv2), which demonstrates the effectiveness of our proposed algorithm compared to existing state-of-the-art multi-agent IL algorithms.
Mimicking To Dominate: Imitation Learning Strategies for Success in Multiagent Competitive Games
Aug 20, 2023Training agents in multi-agent competitive games presents significant challenges due to their intricate nature. These challenges are exacerbated by dynamics influenced not only by the environment but also by opponents' strategies. Existing methods often struggle with slow convergence and instability. To address this, we harness the potential of imitation learning to comprehend and anticipate opponents' behavior, aiming to mitigate uncertainties with respect to the game dynamics. Our key contributions include: (i) a new multi-agent imitation learning model for predicting next moves of the opponents -- our model works with hidden opponents' actions and local observations; (ii) a new multi-agent reinforcement learning algorithm that combines our imitation learning model and policy training into one single training process; and (iii) extensive experiments in three challenging game environments, including an advanced version of the Star-Craft multi-agent challenge (i.e., SMACv2). Experimental results show that our approach achieves superior performance compared to existing state-of-the-art multi-agent RL algorithms.
CounterNet: End-to-End Training of Counterfactual Aware Predictions
Sep 15, 2021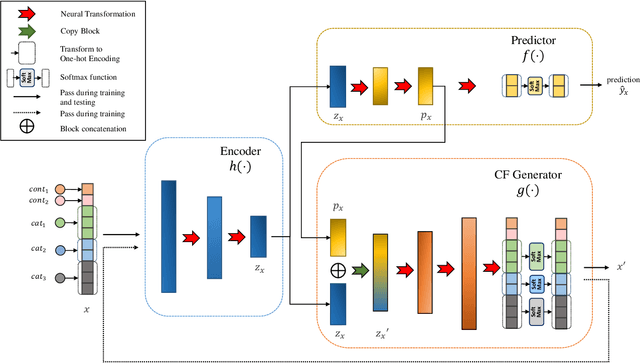
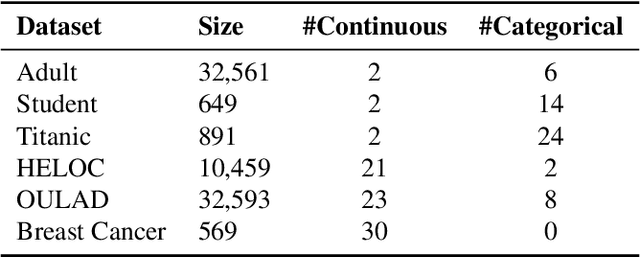
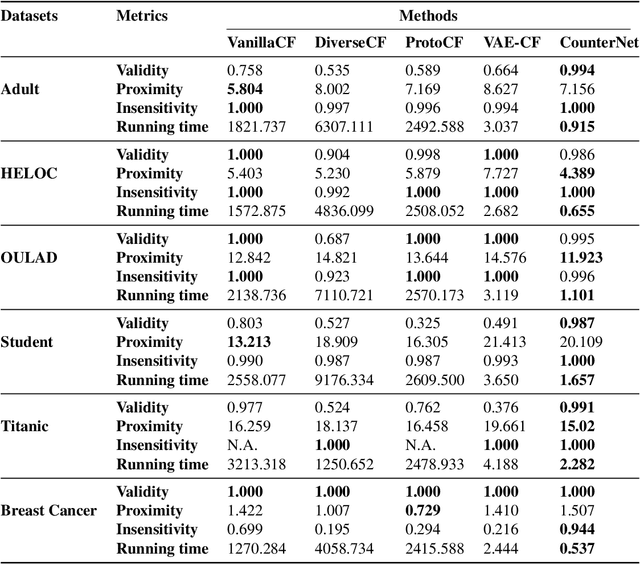
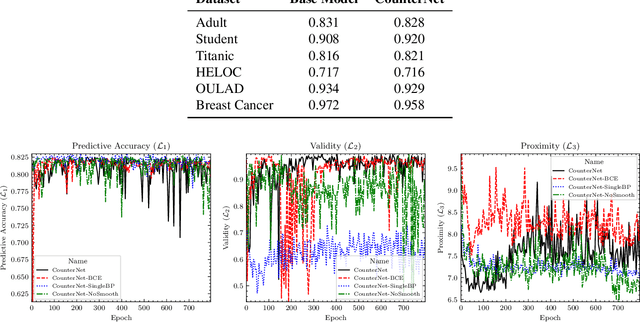
This work presents CounterNet, a novel end-to-end learning framework which integrates the predictive model training and counterfactual (CF) explanation generation into a single end-to-end pipeline. Counterfactual explanations attempt to find the smallest modification to the feature values of an instance that changes the prediction of the ML model to a predefined output. Prior CF explanation techniques rely on solving separate time-intensive optimization problems for every single input instance to find CF examples, and also suffer from the misalignment of objectives between model predictions and explanations, which leads to significant shortcomings in the quality of CF explanations. CounterNet, on the other hand, integrates both prediction and explanation in the same framework, which enables the optimization of the CF example generation only once together with the predictive model. We propose a novel variant of back-propagation which can help in effectively training CounterNet's network. Finally, we conduct extensive experiments on multiple real-world datasets. Our results show that CounterNet generates high-quality predictions, and corresponding CF examples (with high validity) for any new input instance significantly faster than existing state-of-the-art baselines.