 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modelling of Stochastic Actions with Arbitrary Constraints in Reinforcement Learning
Nov 26, 2023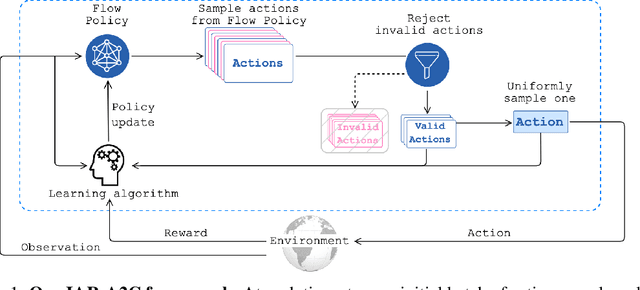
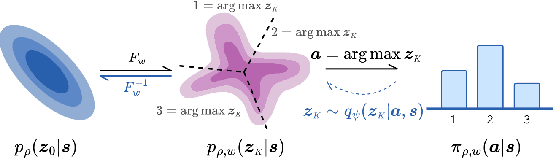
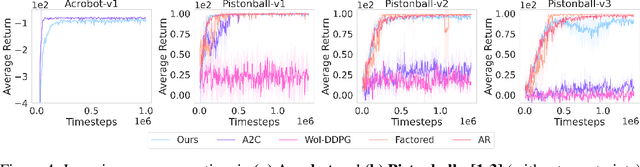
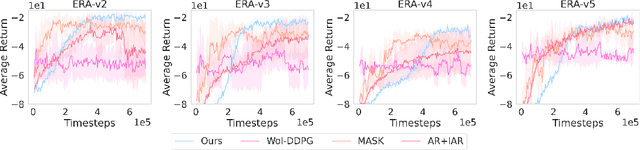
Many problems in Reinforcement Learning (RL) seek an optimal policy with large discrete multidimensional yet unordered action spaces; these include problems in randomized allocation of resources such as placements of multiple security resources and emergency response units, etc. A challenge in this setting is that the underlying action space is categorical (discrete and unordered) and large, for which existing RL methods do not perform well. Moreover, these problems require validity of the realized action (allocation); this validity constraint is often difficult to express compactly in a closed mathematical form. The allocation nature of the problem also prefers stochastic optimal policies, if one exists. In this work, we address these challenges by (1) applying a (state) conditional normalizing flow to compactly represent the stochastic policy -- the compactness arises due to the network only producing one sampled action and the corresponding log probability of the action, which is then used by an actor-critic method; and (2) employing an invalid action rejection method (via a valid action oracle) to update the base policy. The action rejection is enabled by a modified policy gradient that we derive. Finally, we conduct extensive experiments to show the scalability of our approach compared to prior methods and the ability to enforce arbitrary state-conditional constraints on the support of the distribution of actions in any state.
Beyond NaN: Resiliency of Optimization Layers in The Face of Infeasibility
Feb 13, 2022


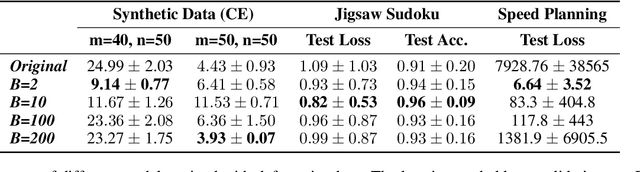
Prior work has successfully incorporated optimization layers as the last layer in neural networks for various problems, thereby allowing joint learning and planning in one neural network forward pass. In this work, we identify a weakness in such a set-up where inputs to the optimization layer lead to undefined output of the neural network. Such undefined decision outputs can lead to possible catastrophic outcomes in critical real time applications. We show that an adversary can cause such failures by forcing rank deficiency on the matrix fed to the optimization layer which results in the optimization failing to produce a solution. We provide a defense for the failure cases by controlling the condition number of the input matrix. We study the problem in the settings of synthetic data, Jigsaw Sudoku, and in speed planning for autonomous driving, building on top of prior frameworks in end-to-end learning and optimization. We show that our proposed defense effectively prevents the framework from failing with undefined output. Finally, we surface a number of edge cases which lead to serious bugs in popular equation and optimization solvers which can be abused as well.
DEVI: Open-source Human-Robot Interface for Interactive Receptionist Systems
Jan 02, 2021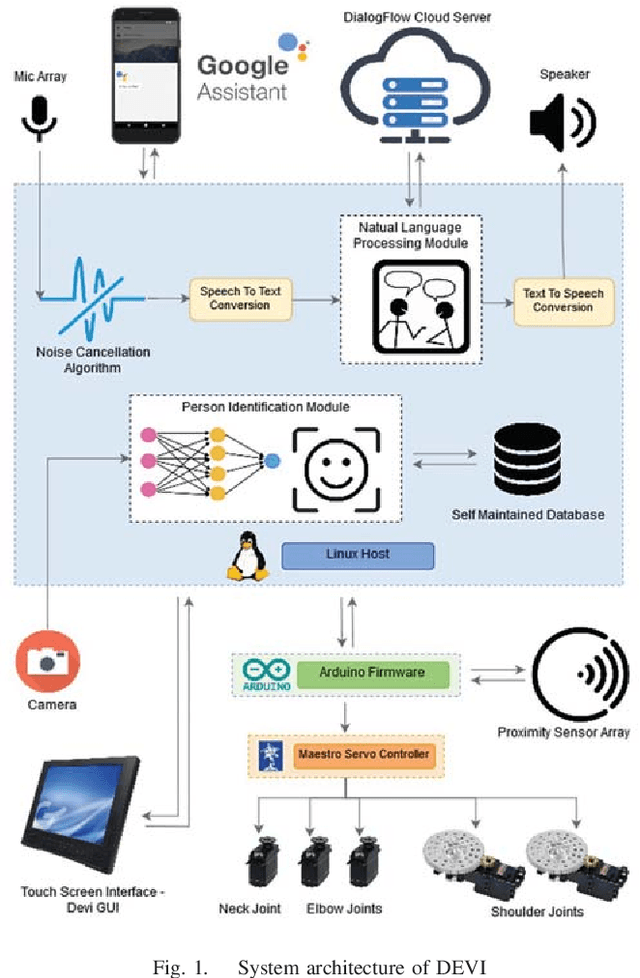
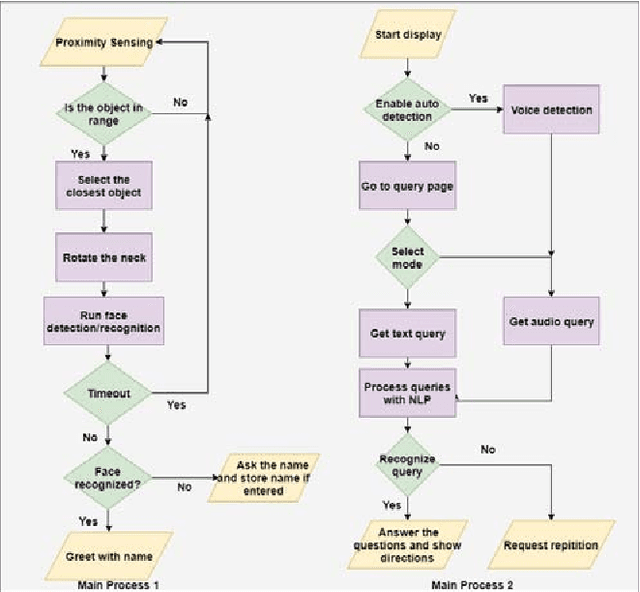

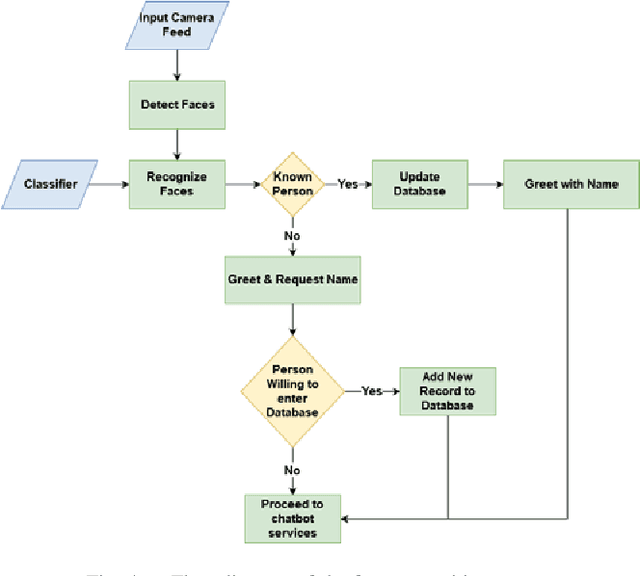
Humanoid robots that act as human-robot interfaces equipped with social skills can assist people in many of their daily activities. Receptionist robots are one such application where social skills and appearance are of utmost importance. Many existing robot receptionist systems suffer from high cost and they do not disclose internal architectures for further development for robot researchers. Moreover, there does not exist customizable open-source robot receptionist frameworks to be deployed for any given application. In this paper we present an open-source robot receptionist intelligence core -- "DEVI"(means 'lady' in Sinhala), that provides researchers with ease of creating customized robot receptionists according to the requirements (cost, external appearance, and required processing power). Moreover, this paper also presents details on a prototype implementation of a physical robot using the DEVI system. The robot can give directional guidance with physical gestures, answer basic queries using a speech recognition and synthesis system, recognize and greet known people using face recognition and register new people in its database, using a self-learning neural network. Experiments conducted with DEVI show the effectiveness of the proposed system.
Measuring Data Collection Quality for Community Healthcare
Nov 13, 2020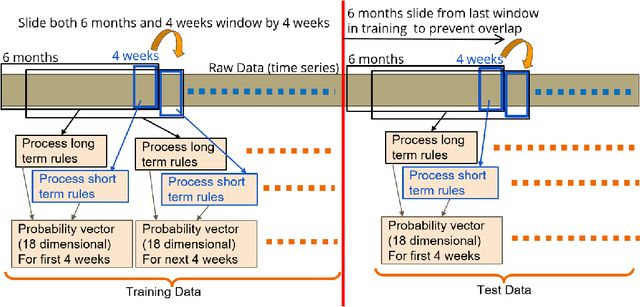
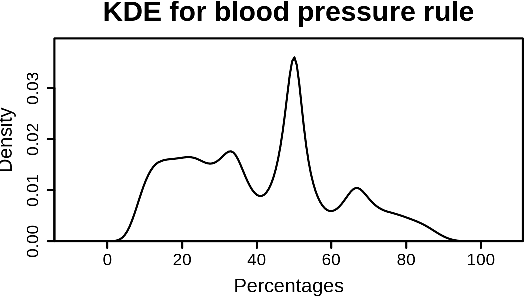
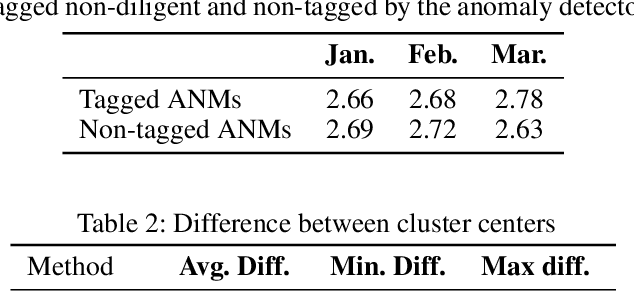
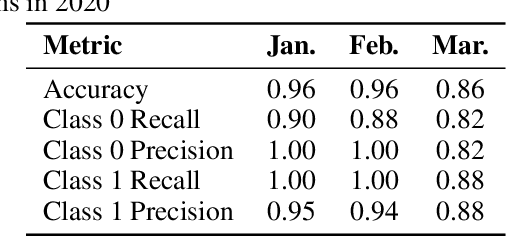
Machine learning has tremendous potential to provide targeted interventions in low-resource communities, however the availability of high-quality public health data is a significant challenge. In this work, we partner with field experts at a non-governmental organization (NGO) in India to define and test a data collection quality score for each health worker who collects data. This challenging unlabeled data problem is handled by building upon domain-expert's guidance to design a useful data representation that is then clustered to infer a data quality score. We also provide a more interpretable version of the score. These scores already provide for a measurement of data collection quality; in addition, we also predict the quality for future time steps and find our results to be very accurate. Our work was successfully field tested and is in the final stages of deployment in Rajasthan, India.