 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Data Collection Quality for Community Healthcare
Nov 13, 2020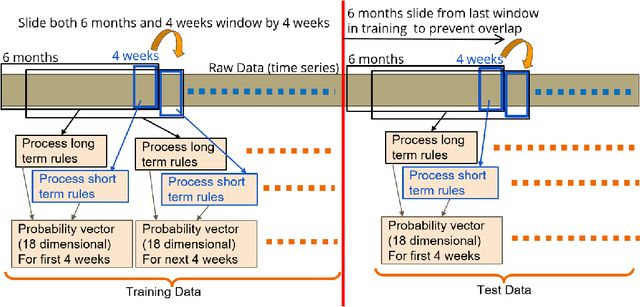
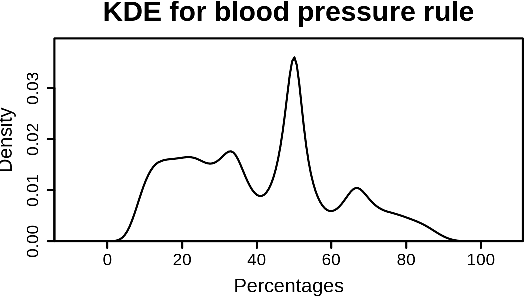
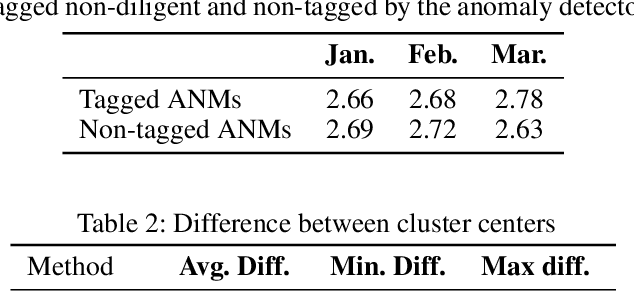
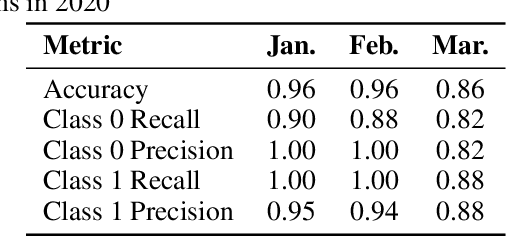
Machine learning has tremendous potential to provide targeted interventions in low-resource communities, however the availability of high-quality public health data is a significant challenge. In this work, we partner with field experts at a non-governmental organization (NGO) in India to define and test a data collection quality score for each health worker who collects data. This challenging unlabeled data problem is handled by building upon domain-expert's guidance to design a useful data representation that is then clustered to infer a data quality score. We also provide a more interpretable version of the score. These scores already provide for a measurement of data collection quality; in addition, we also predict the quality for future time steps and find our results to be very accurate. Our work was successfully field tested and is in the final stages of deployment in Rajasthan, India.