 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThyroidEffi 1.0: A Cost-Effective System for High-Performance Multi-Class Thyroid Carcinoma Classification
Apr 19, 2025Background: Automated classification of thyroid fine needle aspiration biopsy (FNAB) images faces challenges in limited data, inter-observer variability, and computational cost. Efficient, interpretable models are crucial for clinical support. Objective: To develop and externally validate a deep learning system for the multi-class classification of thyroid FNAB images into three key categories that directly guide post-biopsy treatment decisions in Vietnam: benign (B2), suspicious for malignancy (B5), and malignant (B6), while achieving high diagnostic accuracy with low computational overhead. Methods: Our framework features: (1) YOLOv10-based cell cluster detection for informative sub-region extraction and noise reduction; (2) a curriculum learning-inspired protocol sequencing localized crops to full images for multi-scale feature capture; (3) adaptive lightweight EfficientNetB0 (4 millions parameters) selection balancing performance and efficiency; and (4) a Transformer-inspired module for multi-scale, multi-region analysis. External validation used 1,015 independent FNAB images. Results: ThyroidEffi Basic achieved a macro F1 of 89.19\% and AUCs of 0.98 (B2), 0.95 (B5), and 0.96 (B6) on the internal test set. External validation yielded AUCs of 0.9495 (B2), 0.7436 (B5), and 0.8396 (B6). ThyroidEffi Premium improved macro F1 to 89.77\%. Grad-CAM highlighted key diagnostic regions, confirming interpretability. The system processed 1000 cases in 30 seconds, demonstrating feasibility on widely accessible hardware like a 12-core CPU. Conclusions: This work demonstrates that high-accuracy, interpretable thyroid FNAB image classification is achievable with minimal computational demands.
Cross-lingual Extended Named Entity Classification of Wikipedia Articles
Oct 17, 2020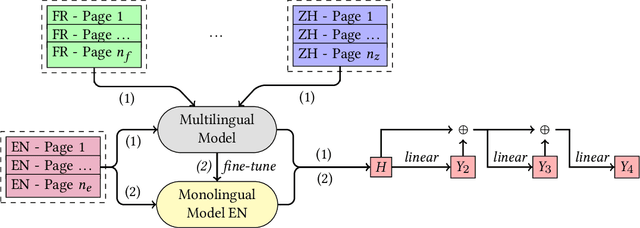


The FPT.AI team participated in the SHINRA2020-ML subtask of the NTCIR-15 SHINRA task. This paper describes our method to solving the problem and discusses the official results. Our method focuses on learning cross-lingual representations, both on the word level and document level for page classification. We propose a three-stage approach including multilingual model pre-training, monolingual model fine-tuning and cross-lingual voting. Our system is able to achieve the best scores for 25 out of 30 languages; and its accuracy gaps to the best performing systems of the other five languages are relatively small.
Improving Sequence Tagging for Vietnamese Text Using Transformer-based Neural Models
Jul 02, 2020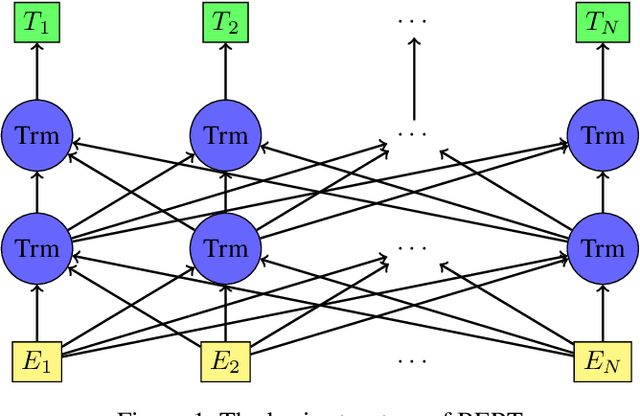
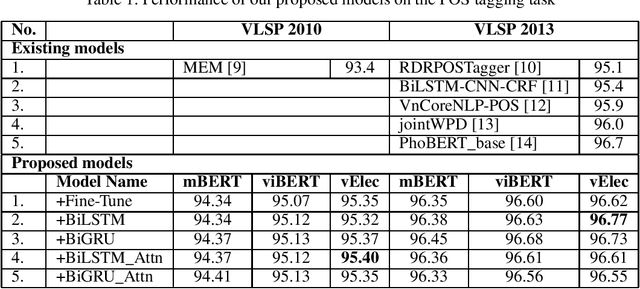
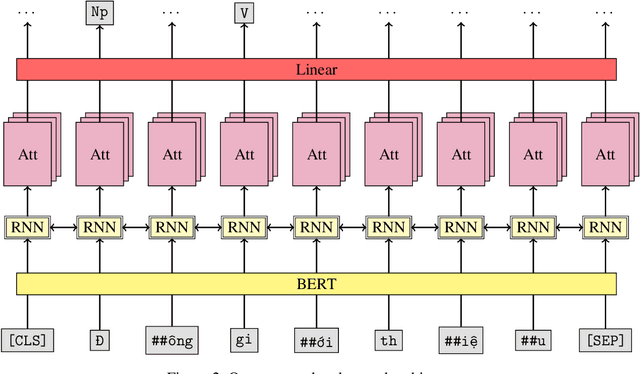
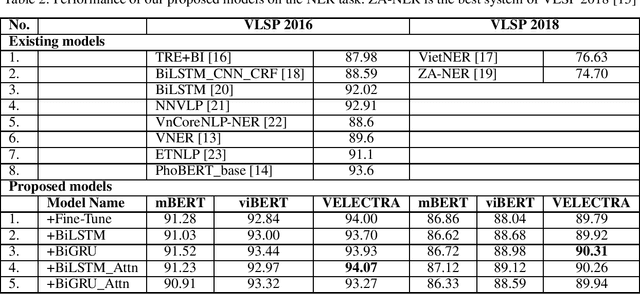
This paper describes our study on using mutilingual BERT embeddings and some new neural models for improving sequence tagging tasks for the Vietnamese language. We propose new model architectures and evaluate them extensively on two named entity recognition datasets of VLSP 2016 and VLSP 2018, and on two part-of-speech tagging datasets of VLSP 2010 and VLSP 2013. Our proposed models outperform existing methods and achieve new state-of-the-art results. In particular, we have pushed the accuracy of part-of-speech tagging to 95.40% on the VLSP 2010 corpus, to 96.77% on the VLSP 2013 corpus; and the F1 score of named entity recognition to 94.07% on the VLSP 2016 corpus, to 90.31% on the VLSP 2018 corpus. Our code and pre-trained models viBERT and vELECTRA are released as open source to facilitate adoption and further research.
Towards Task-Oriented Dialogue in Mixed Domains
Sep 05, 2019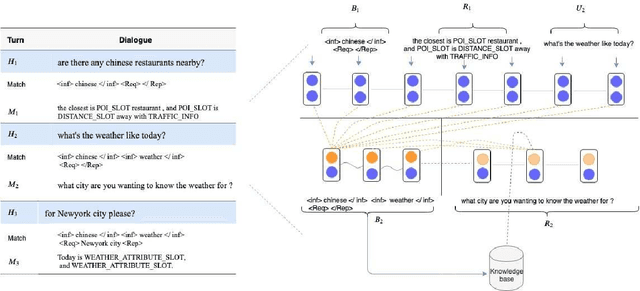
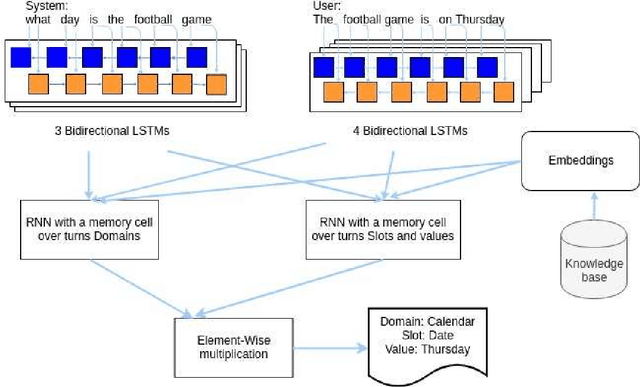
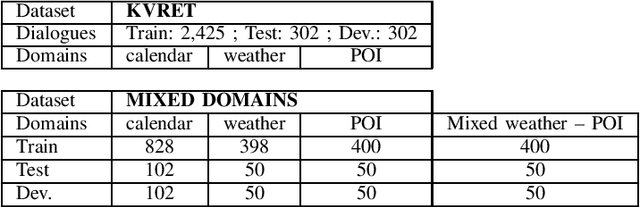
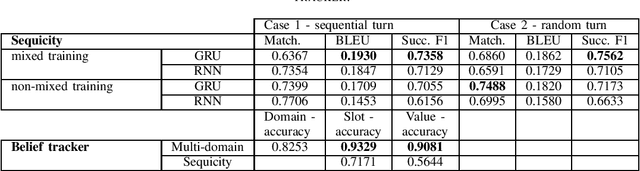
This work investigates the task-oriented dialogue problem in mixed-domain settings. We study the effect of alternating between different domains in sequences of dialogue turns using two related state-of-the-art dialogue systems. We first show that a specialized state tracking component in multiple domains plays an important role and gives better results than an end-to-end task-oriented dialogue system. We then propose a hybrid system which is able to improve the belief tracking accuracy of about 28% of average absolute point on a standard multi-domain dialogue dataset. These experimental results give some useful insights for improving our commercial chatbot platform FPT.AI, which is currently deployed for many practical chatbot applications.
A Comparative Study of Neural Network Models for Sentence Classification
Oct 03, 2018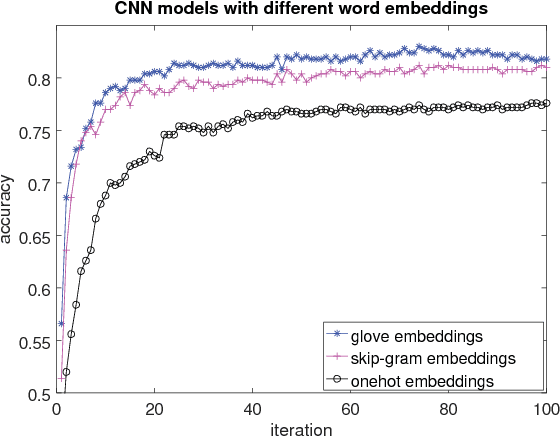
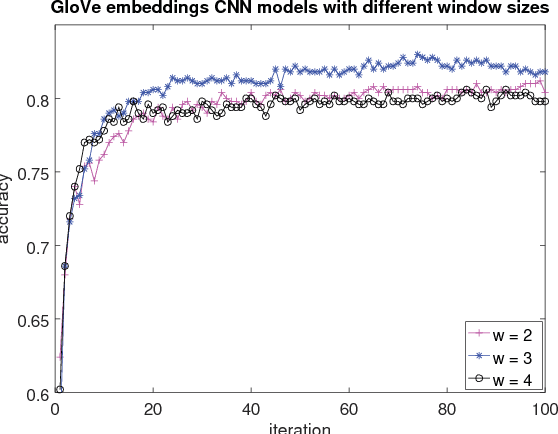
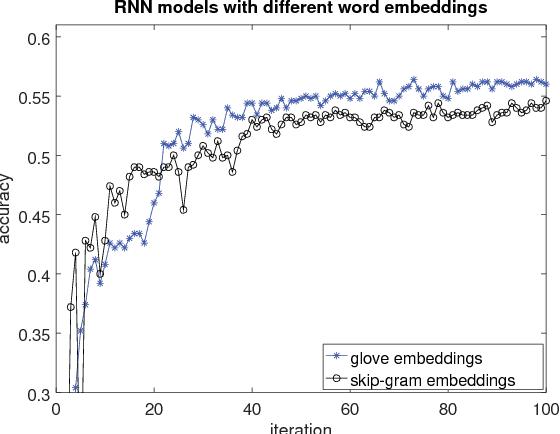
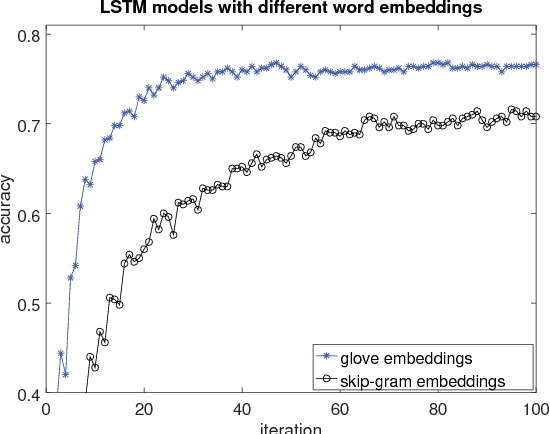
This paper presents an extensive comparative study of four neural network models, including feed-forward networks, convolutional networks, recurrent networks and long short-term memory networks, on two sentence classification datasets of English and Vietnamese text. We show that on the English dataset, the convolutional network models without any feature engineering outperform some competitive sentence classifiers with rich hand-crafted linguistic features. We demonstrate that the GloVe word embeddings are consistently better than both Skip-gram word embeddings and word count vectors. We also show the superiority of convolutional neural network models on a Vietnamese newspaper sentence dataset over strong baseline models. Our experimental results suggest some good practices for applying neural network models in sentence classification.
A Factoid Question Answering System for Vietnamese
Mar 28, 2018

In this paper, we describe the development of an end-to-end factoid question answering system for the Vietnamese language. This system combines both statistical models and ontology-based methods in a chain of processing modules to provide high-quality mappings from natural language text to entities. We present the challenges in the development of such an intelligent user interface for an isolating language like Vietnamese and show that techniques developed for inflectional languages cannot be applied "as is". Our question answering system can answer a wide range of general knowledge questions with promising accuracy on a test set.
Vietnamese Semantic Role Labelling
Nov 28, 2017
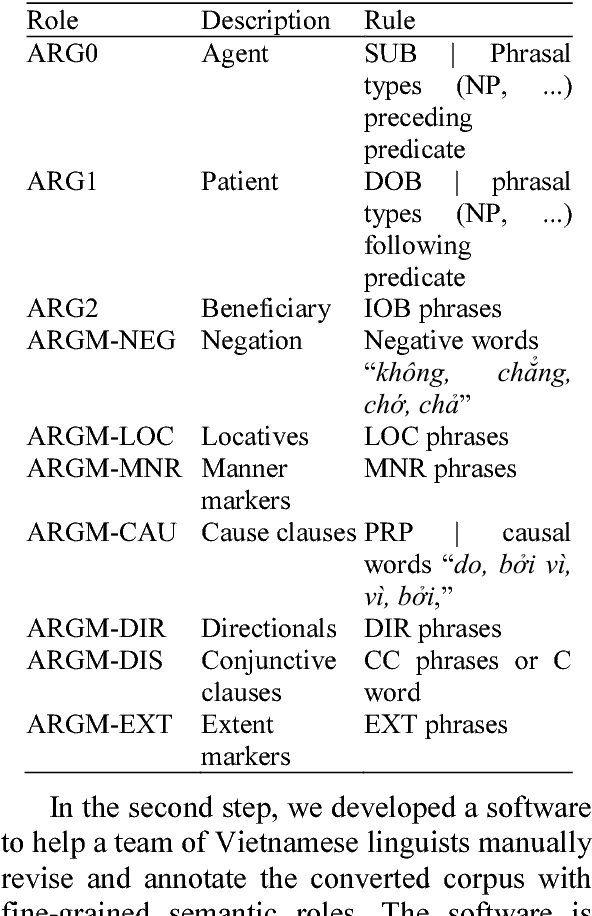
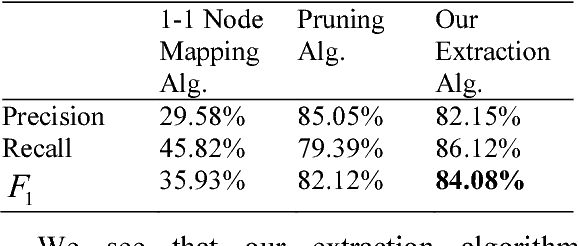
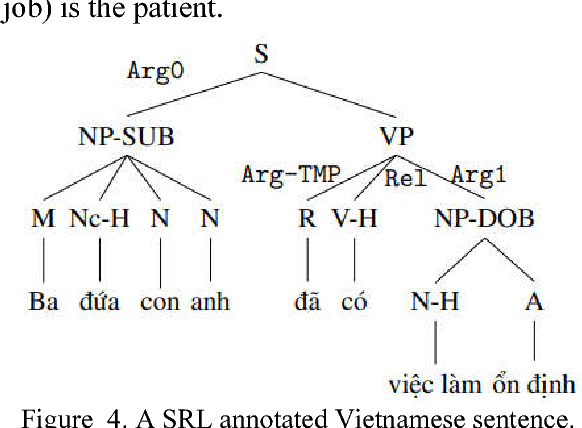
In this paper, we study semantic role labelling (SRL), a subtask of semantic parsing of natural language sentences and its application for the Vietnamese language. We present our effort in building Vietnamese PropBank, the first Vietnamese SRL corpus and a software system for labelling semantic roles of Vietnamese texts. In particular, we present a novel constituent extraction algorithm in the argument candidate identification step which is more suitable and more accurate than the common node-mapping method. In the machine learning part, our system integrates distributed word features produced by two recent unsupervised learning models in two learned statistical classifiers and makes use of integer linear programming inference procedure to improve the accuracy. The system is evaluated in a series of experiments and achieves a good result, an $F_1$ score of 74.77%. Our system, including corpus and software, is available as an open source project for free research and we believe that it is a good baseline for the development of future Vietnamese SRL systems.
On the Use of Machine Translation-Based Approaches for Vietnamese Diacritic Restoration
Oct 26, 2017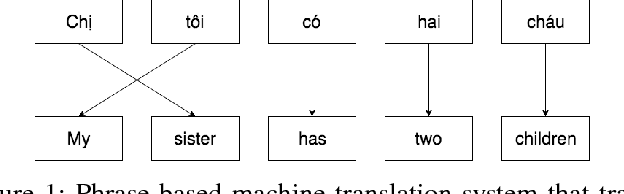
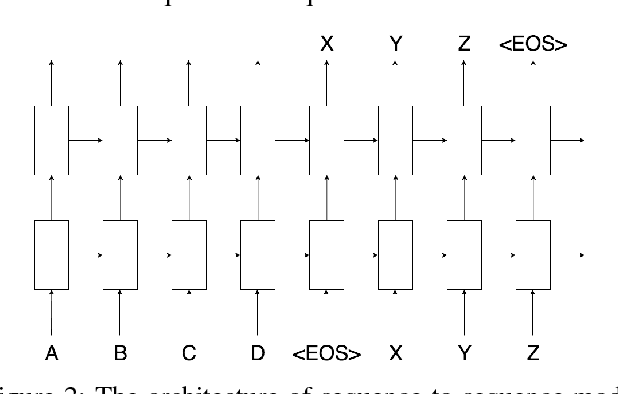
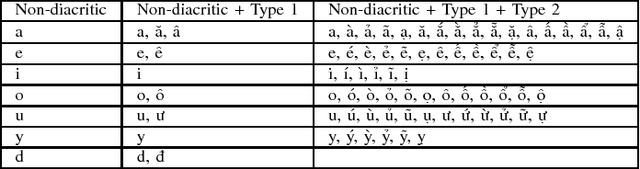
This paper presents an empirical study of two machine translation-based approaches for Vietnamese diacritic restoration problem, including phrase-based and neural-based machine translation models. This is the first work that applies neural-based machine translation method to this problem and gives a thorough comparison to the phrase-based machine translation method which is the current state-of-the-art method for this problem. On a large dataset, the phrase-based approach has an accuracy of 97.32% while that of the neural-based approach is 96.15%. While the neural-based method has a slightly lower accuracy, it is about twice faster than the phrase-based method in terms of inference speed. Moreover, neural-based machine translation method has much room for future improvement such as incorporating pre-trained word embeddings and collecting more training data.
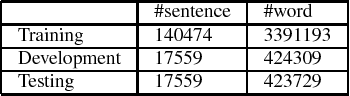
NNVLP: A Neural Network-Based Vietnamese Language Processing Toolkit
Oct 19, 2017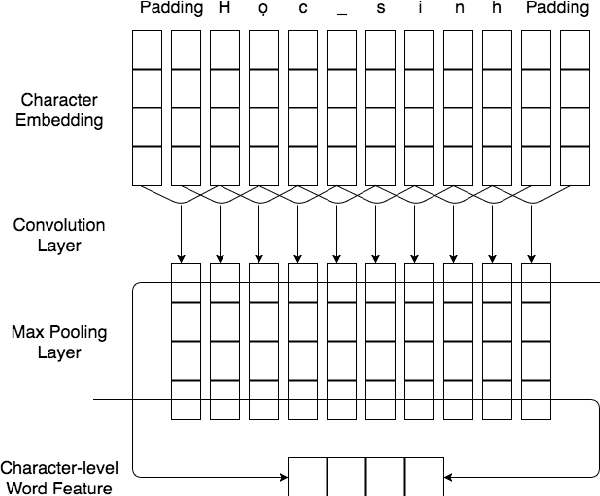
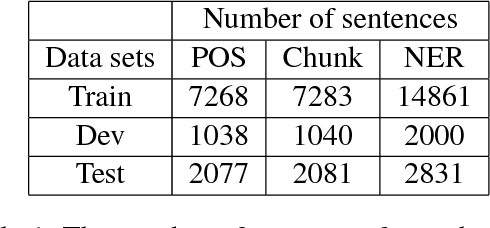
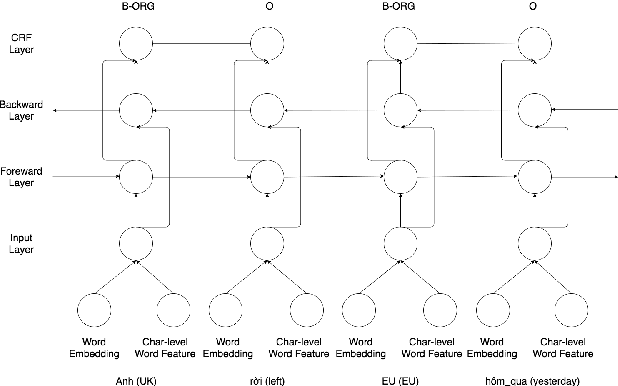
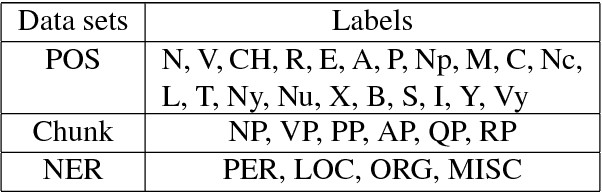
This paper demonstrates neural network-based toolkit namely NNVLP for essential Vietnamese language processing tasks including part-of-speech (POS) tagging, chunking, named entity recognition (NER). Our toolkit is a combination of bidirectional Long Short-Term Memory (Bi-LSTM), Convolutional Neural Network (CNN), Conditional Random Field (CRF), using pre-trained word embeddings as input, which achieves state-of-the-art results on these three tasks. We provide both API and web demo for this toolkit.
An Empirical Study of Discriminative Sequence Labeling Models for Vietnamese Text Processing
Aug 30, 2017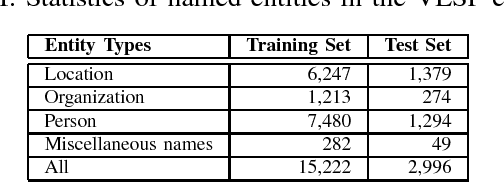
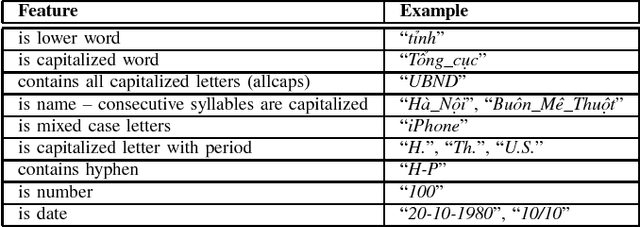
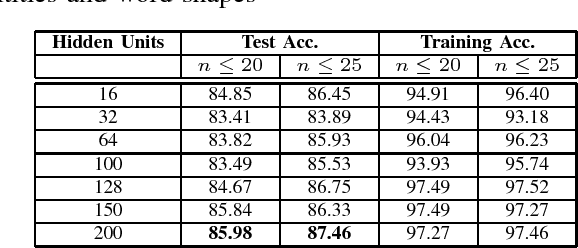
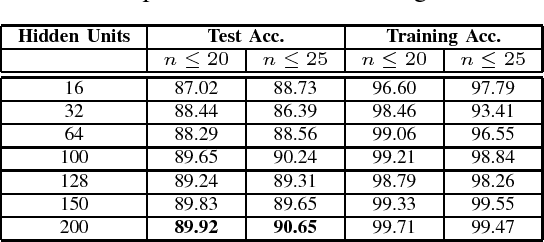
This paper presents an empirical study of two widely-used sequence prediction models, Conditional Random Fields (CRFs) and Long Short-Term Memory Networks (LSTMs), on two fundamental tasks for Vietnamese text processing, including part-of-speech tagging and named entity recognition. We show that a strong lower bound for labeling accuracy can be obtained by relying only on simple word-based features with minimal hand-crafted feature engineering, of 90.65\% and 86.03\% performance scores on the standard test sets for the two tasks respectively. In particular, we demonstrate empirically the surprising efficiency of word embeddings in both of the two tasks, with both of the two models. We point out that the state-of-the-art LSTMs model does not always outperform significantly the traditional CRFs model, especially on moderate-sized data sets. Finally, we give some suggestions and discussions for efficient use of sequence labeling models in practical applications.