 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Machine Translation-Based Approaches for Vietnamese Diacritic Restoration
Oct 26, 2017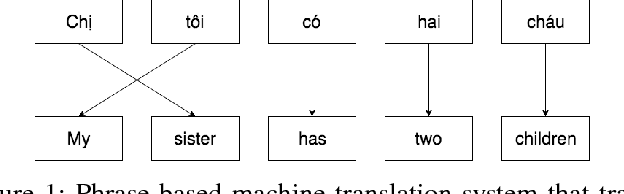
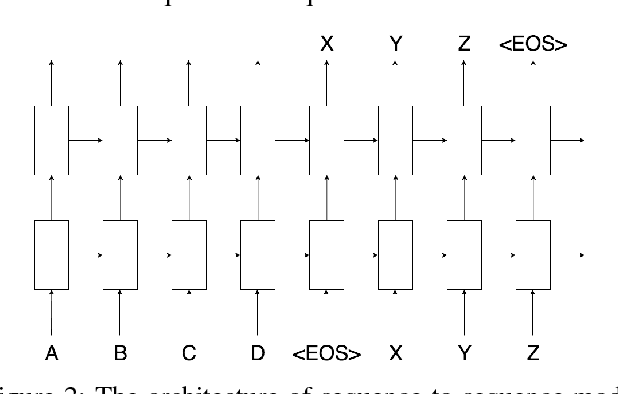
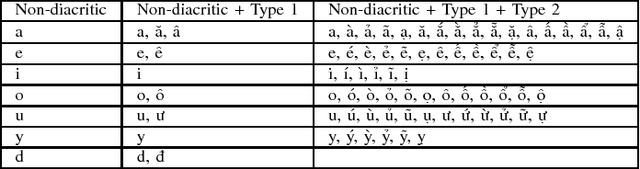
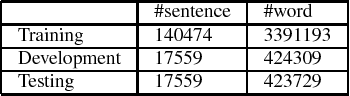
This paper presents an empirical study of two machine translation-based approaches for Vietnamese diacritic restoration problem, including phrase-based and neural-based machine translation models. This is the first work that applies neural-based machine translation method to this problem and gives a thorough comparison to the phrase-based machine translation method which is the current state-of-the-art method for this problem. On a large dataset, the phrase-based approach has an accuracy of 97.32% while that of the neural-based approach is 96.15%. While the neural-based method has a slightly lower accuracy, it is about twice faster than the phrase-based method in terms of inference speed. Moreover, neural-based machine translation method has much room for future improvement such as incorporating pre-trained word embeddings and collecting more training data.
NNVLP: A Neural Network-Based Vietnamese Language Processing Toolkit
Oct 19, 2017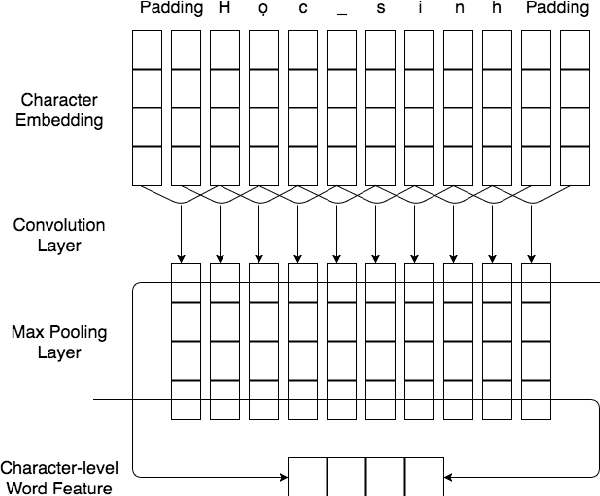
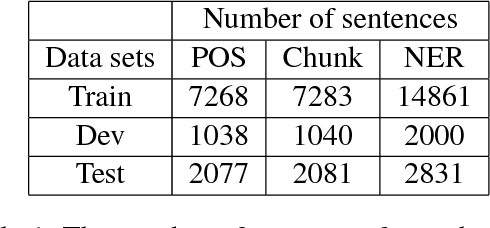
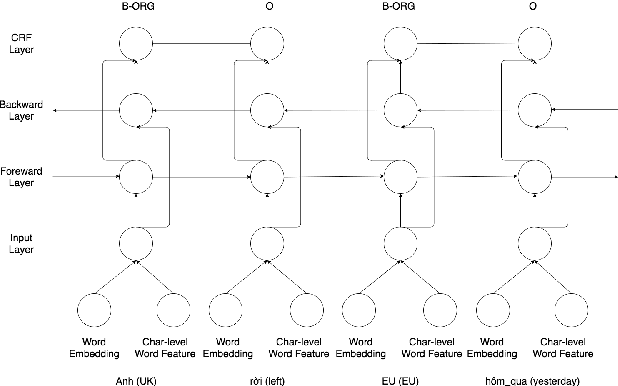
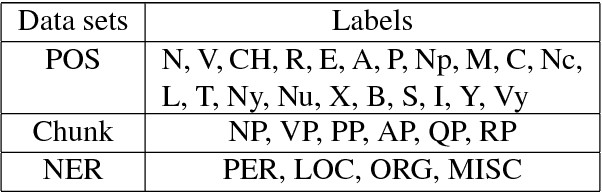
This paper demonstrates neural network-based toolkit namely NNVLP for essential Vietnamese language processing tasks including part-of-speech (POS) tagging, chunking, named entity recognition (NER). Our toolkit is a combination of bidirectional Long Short-Term Memory (Bi-LSTM), Convolutional Neural Network (CNN), Conditional Random Field (CRF), using pre-trained word embeddings as input, which achieves state-of-the-art results on these three tasks. We provide both API and web demo for this toolkit.
Building a Semantic Role Labelling System for Vietnamese
May 11, 2017
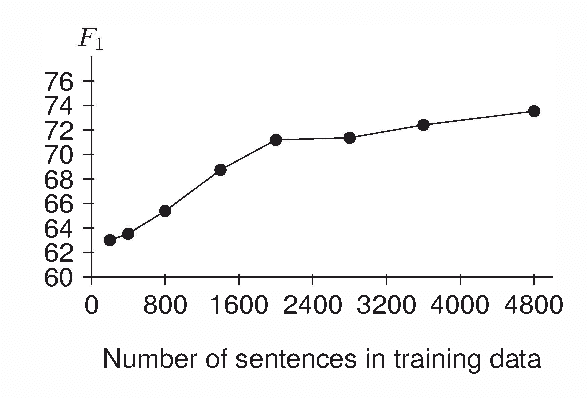

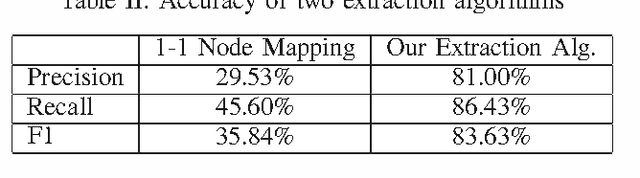
Semantic role labelling (SRL) is a task in natural language processing which detects and classifies the semantic arguments associated with the predicates of a sentence. It is an important step towards understanding the meaning of a natural language. There exists SRL systems for well-studied languages like English, Chinese or Japanese but there is not any such system for the Vietnamese language. In this paper, we present the first SRL system for Vietnamese with encouraging accuracy. We first demonstrate that a simple application of SRL techniques developed for English could not give a good accuracy for Vietnamese. We then introduce a new algorithm for extracting candidate syntactic constituents, which is much more accurate than the common node-mapping algorithm usually used in the identification step. Finally, in the classification step, in addition to the common linguistic features, we propose novel and useful features for use in SRL. Our SRL system achieves an $F_1$ score of 73.53\% on the Vietnamese PropBank corpus. This system, including software and corpus, is available as an open source project and we believe that it is a good baseline for the development of future Vietnamese SRL systems.