 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Fairness Without Harm via Selective Demographic Experts
Nov 09, 2025As machine learning systems become increasingly integrated into human-centered domains such as healthcare, ensuring fairness while maintaining high predictive performance is critical. Existing bias mitigation techniques often impose a trade-off between fairness and accuracy, inadvertently degrading performance for certain demographic groups. In high-stakes domains like clinical diagnosis, such trade-offs are ethically and practically unacceptable. In this study, we propose a fairness-without-harm approach by learning distinct representations for different demographic groups and selectively applying demographic experts consisting of group-specific representations and personalized classifiers through a no-harm constrained selection. We evaluate our approach on three real-world medical datasets -- covering eye disease, skin cancer, and X-ray diagnosis -- as well as two face datasets. Extensive empirical results demonstrate the effectiveness of our approach in achieving fairness without harm.
SepsisCalc: Integrating Clinical Calculators into Early Sepsis Prediction via Dynamic Temporal Graph Construction
Dec 31, 2024



Sepsis is an organ dysfunction caused by a deregulated immune response to an infection. Early sepsis prediction and identification allow for timely intervention, leading to improved clinical outcomes. Clinical calculators (e.g., the six-organ dysfunction assessment of SOFA) play a vital role in sepsis identification within clinicians' workflow, providing evidence-based risk assessments essential for sepsis diagnosis. However, artificial intelligence (AI) sepsis prediction models typically generate a single sepsis risk score without incorporating clinical calculators for assessing organ dysfunctions, making the models less convincing and transparent to clinicians. To bridge the gap, we propose to mimic clinicians' workflow with a novel framework SepsisCalc to integrate clinical calculators into the predictive model, yielding a clinically transparent and precise model for utilization in clinical settings. Practically, clinical calculators usually combine information from multiple component variables in Electronic Health Records (EHR), and might not be applicable when the variables are (partially) missing. We mitigate this issue by representing EHRs as temporal graphs and integrating a learning module to dynamically add the accurately estimated calculator to the graphs. Experimental results on real-world datasets show that the proposed model outperforms state-of-the-art methods on sepsis prediction tasks. Moreover, we developed a system to identify organ dysfunctions and potential sepsis risks, providing a human-AI interaction tool for deployment, which can help clinicians understand the prediction outputs and prepare timely interventions for the corresponding dysfunctions, paving the way for actionable clinical decision-making support for early intervention.
Open-Set Heterogeneous Domain Adaptation: Theoretical Analysis and Algorithm
Dec 17, 2024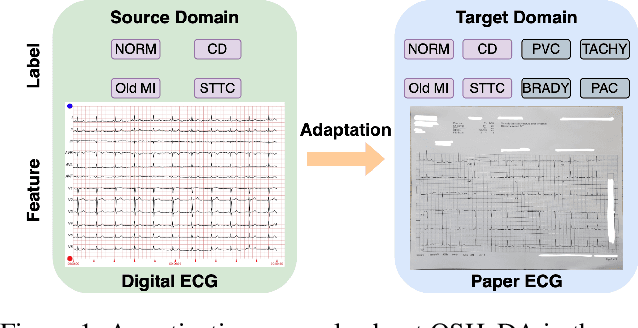
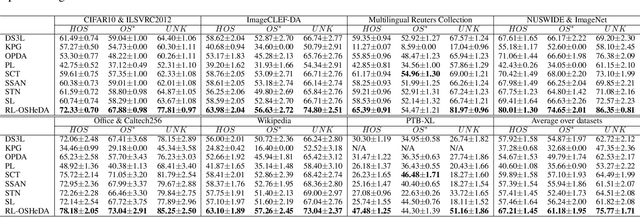
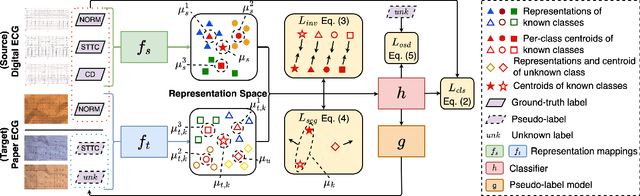
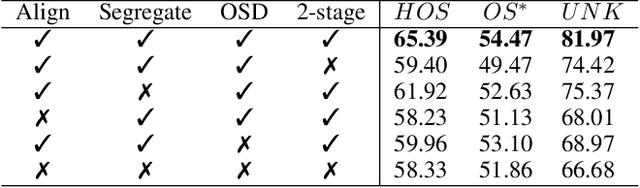
Domain adaptation (DA) tackles the issue of distribution shift by learning a model from a source domain that generalizes to a target domain. However, most existing DA methods are designed for scenarios where the source and target domain data lie within the same feature space, which limits their applicability in real-world situations. Recently, heterogeneous DA (HeDA) methods have been introduced to address the challenges posed by heterogeneous feature space between source and target domains. Despite their successes, current HeDA techniques fall short when there is a mismatch in both feature and label spaces. To address this, this paper explores a new DA scenario called open-set HeDA (OSHeDA). In OSHeDA, the model must not only handle heterogeneity in feature space but also identify samples belonging to novel classes. To tackle this challenge, we first develop a novel theoretical framework that constructs learning bounds for prediction error on target domain. Guided by this framework, we propose a new DA method called Representation Learning for OSHeDA (RL-OSHeDA). This method is designed to simultaneously transfer knowledge between heterogeneous data sources and identify novel classes. Experiments across text, image, and clinical data demonstrate the effectiveness of our algorithm. Model implementation is available at \url{https://github.com/pth1993/OSHeDA}.
Non-stationary Domain Generalization: Theory and Algorithm
May 10, 2024

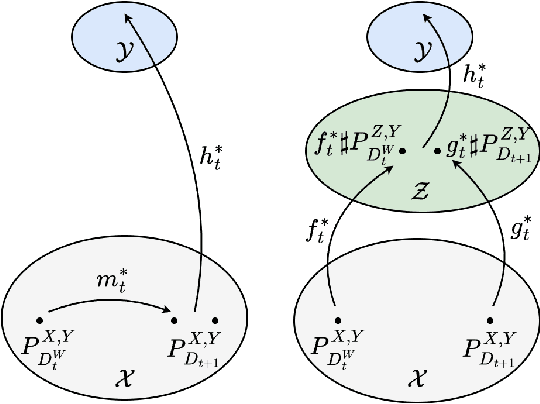
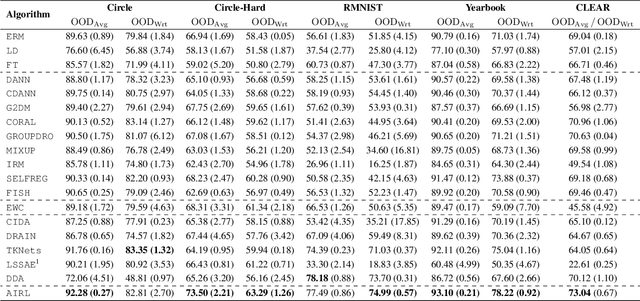
Although recent advances in machine learning have shown its success to learn from independent and identically distributed (IID) data, it is vulnerable to out-of-distribution (OOD) data in an open world. Domain generalization (DG) deals with such an issue and it aims to learn a model from multiple source domains that can be generalized to unseen target domains. Existing studies on DG have largely focused on stationary settings with homogeneous source domains. However, in many applications, domains may evolve along a specific direction (e.g., time, space). Without accounting for such non-stationary patterns, models trained with existing methods may fail to generalize on OOD data. In this paper, we study domain generalization in non-stationary environment. We first examine the impact of environmental non-stationarity on model performance and establish the theoretical upper bounds for the model error at target domains. Then, we propose a novel algorithm based on adaptive invariant representation learning, which leverages the non-stationary pattern to train a model that attains good performance on target domains. Experiments on both synthetic and real data validate the proposed algorithm.
Domain Invariant Representation Learning and Sleep Dynamics Modeling for Automatic Sleep Staging
Dec 09, 2023Sleep staging has become a critical task in diagnosing and treating sleep disorders to prevent sleep related diseases. With growing large scale sleep databases, significant progress has been made toward automatic sleep staging. However, previous studies face critical problems in sleep studies; the heterogeneity of subjects' physiological signals, the inability to extract meaningful information from unlabeled data to improve predictive performances, the difficulty in modeling correlations between sleep stages, and the lack of an effective mechanism to quantify predictive uncertainty. In this study, we propose a neural network based sleep staging model, DREAM, to learn domain generalized representations from physiological signals and models sleep dynamics. DREAM learns sleep related and subject invariant representations from diverse subjects' sleep signals and models sleep dynamics by capturing interactions between sequential signal segments and between sleep stages. We conducted a comprehensive empirical study to demonstrate the superiority of DREAM, including sleep stage prediction experiments, a case study, the usage of unlabeled data, and uncertainty. Notably, the case study validates DREAM's ability to learn generalized decision function for new subjects, especially in case there are differences between testing and training subjects. Uncertainty quantification shows that DREAM provides prediction uncertainty, making the model reliable and helping sleep experts in real world applications.
Fairness and Accuracy under Domain Generalization
Jan 30, 2023As machine learning (ML) algorithms are increasingly used in high-stakes applications, concerns have arisen that they may be biased against certain social groups. Although many approaches have been proposed to make ML models fair, they typically rely on the assumption that data distributions in training and deployment are identical. Unfortunately, this is commonly violated in practice and a model that is fair during training may lead to an unexpected outcome during its deployment. Although the problem of designing robust ML models under dataset shifts has been widely studied, most existing works focus only on the transfer of accuracy. In this paper, we study the transfer of both fairness and accuracy under domain generalization where the data at test time may be sampled from never-before-seen domains. We first develop theoretical bounds on the unfairness and expected loss at deployment, and then derive sufficient conditions under which fairness and accuracy can be perfectly transferred via invariant representation learning. Guided by this, we design a learning algorithm such that fair ML models learned with training data still have high fairness and accuracy when deployment environments change. Experiments on real-world data validate the proposed algorithm. Model implementation is available at https://github.com/pth1993/FATDM.
Cardiac Complication Risk Profiling for Cancer Survivors via Multi-View Multi-Task Learning
Sep 25, 2021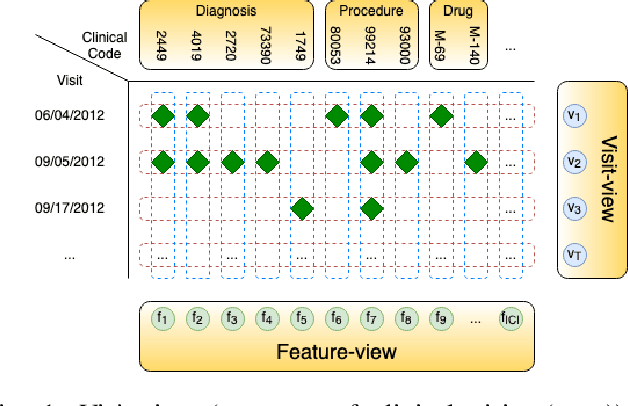
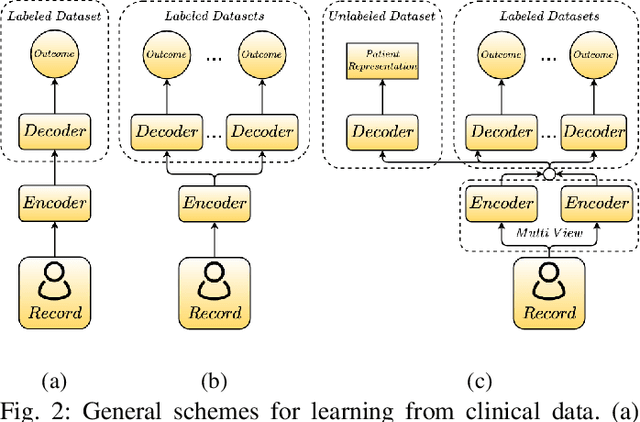
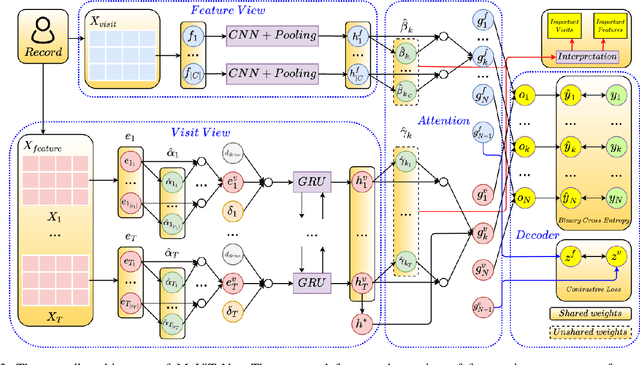
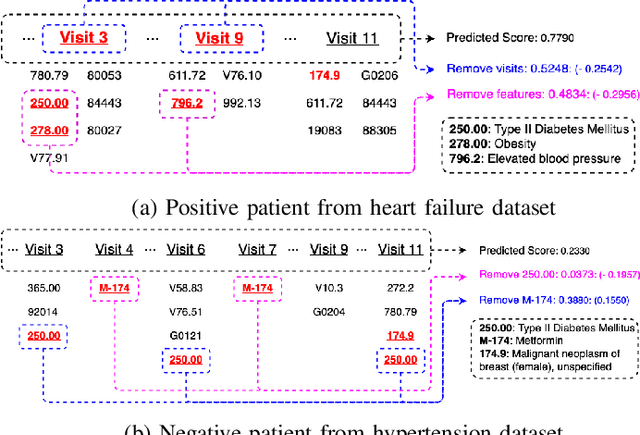
Complication risk profiling is a key challenge in the healthcare domain due to the complex interaction between heterogeneous entities (e.g., visit, disease, medication) in clinical data. With the availability of real-world clinical data such as electronic health records and insurance claims, many deep learning methods are proposed for complication risk profiling. However, these existing methods face two open challenges. First, data heterogeneity relates to those methods leveraging clinical data from a single view only while the data can be considered from multiple views (e.g., sequence of clinical visits, set of clinical features). Second, generalized prediction relates to most of those methods focusing on single-task learning, whereas each complication onset is predicted independently, leading to suboptimal models. We propose a multi-view multi-task network (MuViTaNet) for predicting the onset of multiple complications to tackle these issues. In particular, MuViTaNet complements patient representation by using a multi-view encoder to effectively extract information by considering clinical data as both sequences of clinical visits and sets of clinical features. In addition, it leverages additional information from both related labeled and unlabeled datasets to generate more generalized representations by using a new multi-task learning scheme for making more accurate predictions. The experimental results show that MuViTaNet outperforms existing methods for profiling the development of cardiac complications in breast cancer survivors. Furthermore, thanks to its multi-view multi-task architecture, MuViTaNet also provides an effective mechanism for interpreting its predictions in multiple perspectives, thereby helping clinicians discover the underlying mechanism triggering the onset and for making better clinical treatments in real-world scenarios.
TransICD: Transformer Based Code-wise Attention Model for Explainable ICD Coding
Mar 28, 2021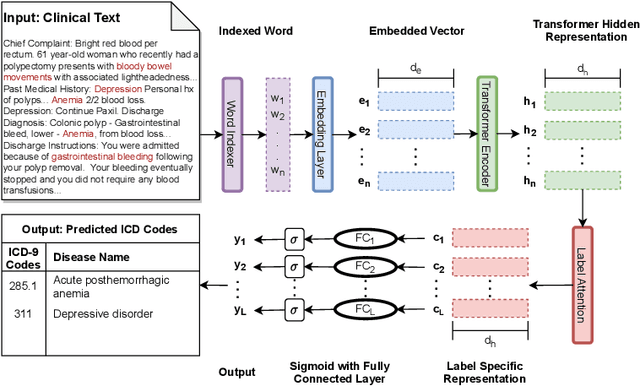

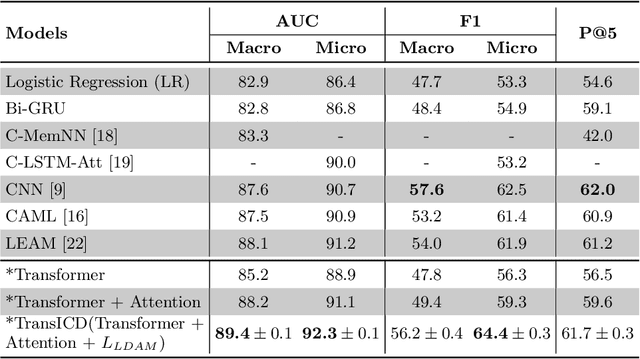
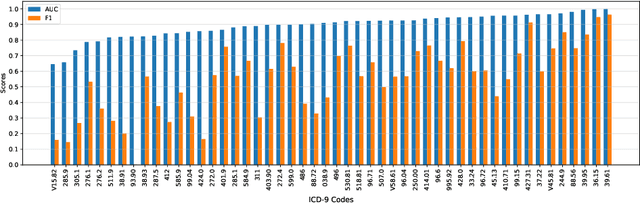
International Classification of Disease (ICD) coding procedure which refers to tagging medical notes with diagnosis codes has been shown to be effective and crucial to the billing system in medical sector. Currently, ICD codes are assigned to a clinical note manually which is likely to cause many errors. Moreover, training skilled coders also requires time and human resources. Therefore, automating the ICD code determination process is an important task. With the advancement of artificial intelligence theory and computational hardware, machine learning approach has emerged as a suitable solution to automate this process. In this project, we apply a transformer-based architecture to capture the interdependence among the tokens of a document and then use a code-wise attention mechanism to learn code-specific representations of the entire document. Finally, they are fed to separate dense layers for corresponding code prediction. Furthermore, to handle the imbalance in the code frequency of clinical datasets, we employ a label distribution aware margin (LDAM) loss function. The experimental results on the MIMIC-III dataset show that our proposed model outperforms other baselines by a significant margin. In particular, our best setting achieves a micro-AUC score of 0.923 compared to 0.868 of bidirectional recurrent neural networks. We also show that by using the code-wise attention mechanism, the model can provide more insights about its prediction, and thus it can support clinicians to make reliable decisions. Our code is available online (https://github.com/biplob1ly/TransICD)
Multi-Task Learning with Contextualized Word Representations for Extented Named Entity Recognition
Feb 26, 2019

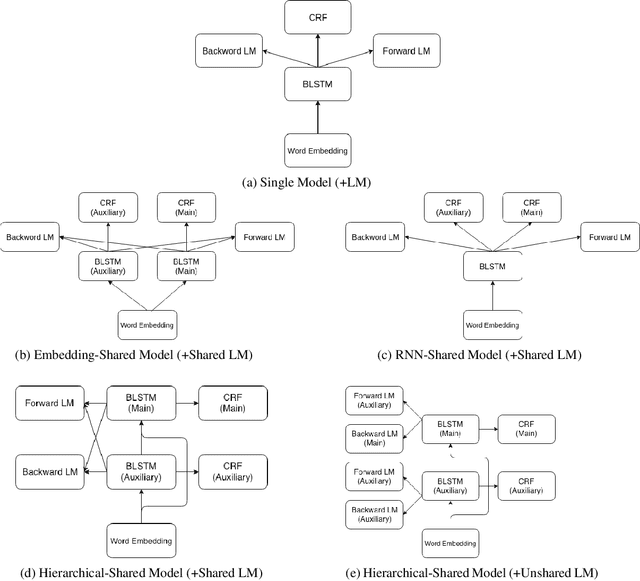
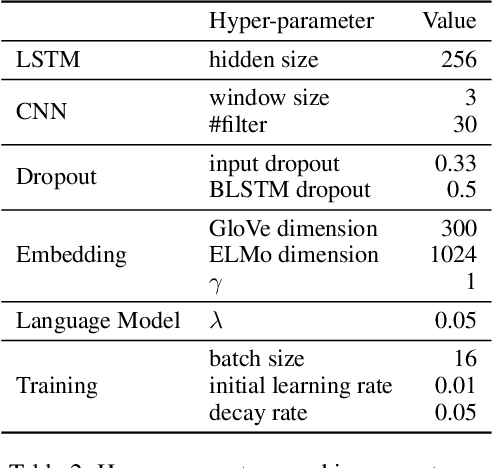
Fine-Grained Named Entity Recognition (FG-NER) is critical for many NLP applications. While classical named entity recognition (NER) has attracted a substantial amount of research, FG-NER is still an open research domain. The current state-of-the-art (SOTA) model for FG-NER relies heavily on manual efforts for building a dictionary and designing hand-crafted features. The end-to-end framework which achieved the SOTA result for NER did not get the competitive result compared to SOTA model for FG-NER. In this paper, we investigate how effective multi-task learning approaches are in an end-to-end framework for FG-NER in different aspects. Our experiments show that using multi-task learning approaches with contextualized word representation can help an end-to-end neural network model achieve SOTA results without using any additional manual effort for creating data and designing features.
On the Use of Machine Translation-Based Approaches for Vietnamese Diacritic Restoration
Oct 26, 2017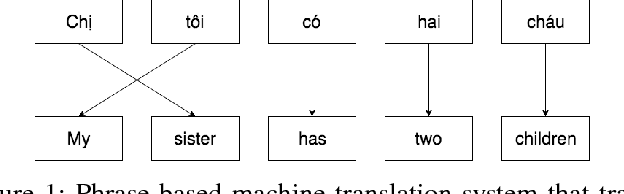
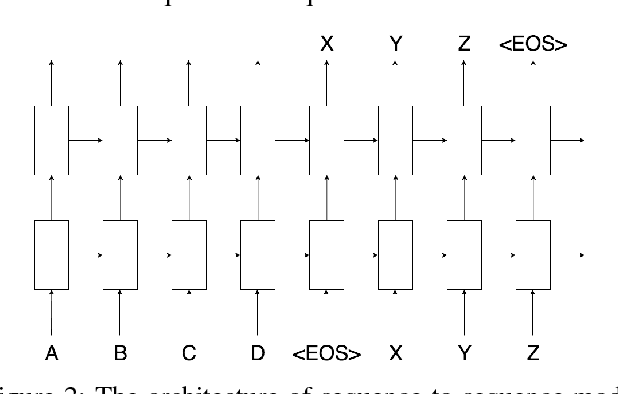
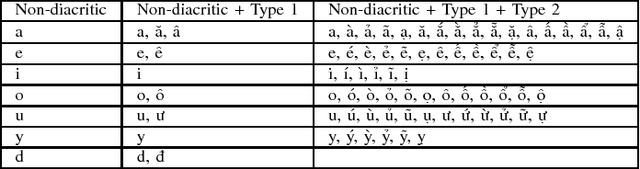
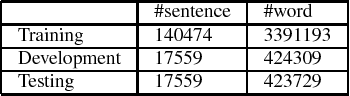
This paper presents an empirical study of two machine translation-based approaches for Vietnamese diacritic restoration problem, including phrase-based and neural-based machine translation models. This is the first work that applies neural-based machine translation method to this problem and gives a thorough comparison to the phrase-based machine translation method which is the current state-of-the-art method for this problem. On a large dataset, the phrase-based approach has an accuracy of 97.32% while that of the neural-based approach is 96.15%. While the neural-based method has a slightly lower accuracy, it is about twice faster than the phrase-based method in terms of inference speed. Moreover, neural-based machine translation method has much room for future improvement such as incorporating pre-trained word embeddings and collecting more training data.