 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Grounded Multimodal Benchmark with 900K-Scale Aggregated Student Response Distributions from Japan's National Assessment of Academic Ability
May 12, 2026Authentic school examinations provide a high-validity test bed for evaluating multimodal large language models (MLLMs), yet benchmarks grounded in Japanese K-12 assessments remain scarce. We present a multimodal dataset constructed from Japan's National Assessment of Academic Ability, comprising officially released middle-school items in Science, Mathematics, and Japanese Language. Unlike existing benchmarks based on synthetic or curated data, our dataset preserves real exam layouts, diagrams, and Japanese educational text, together with nationwide aggregated student response distributions (N $\approx$ 900{,}000). These features enable direct comparison between human and model performance under a unified evaluation framework. We benchmark recent multimodal LLMs using exact-match accuracy and character-level F1 for open-ended responses, observing substantial variation across subjects and strong sensitivity to visual reasoning demands. Human evaluation and LLM-as-judge analyses further assess the reliability of automatic scoring. Our dataset establishes a reproducible, human-grounded benchmark for multimodal educational reasoning and supports future research on evaluation, feedback generation, and explainable AI in authentic assessment contexts. Our dataset is available at: https://github.com/KyosukeTakami/gakucho-benchmark
Improving Methodologies for LLM Evaluations Across Global Languages
Jan 22, 2026As frontier AI models are deployed globally, it is essential that their behaviour remains safe and reliable across diverse linguistic and cultural contexts. To examine how current model safeguards hold up in such settings, participants from the International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the EU, France, Kenya, South Korea and the UK conducted a joint multilingual evaluation exercise. Led by Singapore AISI, two open-weight models were tested across ten languages spanning high and low resourced groups: Cantonese English, Farsi, French, Japanese, Korean, Kiswahili, Malay, Mandarin Chinese and Telugu. Over 6,000 newly translated prompts were evaluated across five harm categories (privacy, non-violent crime, violent crime, intellectual property and jailbreak robustness), using both LLM-as-a-judge and human annotation. The exercise shows how safety behaviours can vary across languages. These include differences in safeguard robustness across languages and harm types and variation in evaluator reliability (LLM-as-judge vs. human review). Further, it also generated methodological insights for improving multilingual safety evaluations, such as the need for culturally contextualised translations, stress-tested evaluator prompts and clearer human annotation guidelines. This work represents an initial step toward a shared framework for multilingual safety testing of advanced AI systems and calls for continued collaboration with the wider research community and industry.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance
Feb 22, 2024



We investigate the impact of politeness levels in prompts on the performance of large language models (LLMs). Polite language in human communications often garners more compliance and effectiveness, while rudeness can cause aversion, impacting response quality. We consider that LLMs mirror human communication traits, suggesting they align with human cultural norms. We assess the impact of politeness in prompts on LLMs across English, Chinese, and Japanese tasks. We observed that impolite prompts often result in poor performance, but overly polite language does not guarantee better outcomes. The best politeness level is different according to the language. This phenomenon suggests that LLMs not only reflect human behavior but are also influenced by language, particularly in different cultural contexts. Our findings highlight the need to factor in politeness for cross-cultural natural language processing and LLM usage.
WikiSQE: A Large-Scale Dataset for Sentence Quality Estimation in Wikipedia
May 10, 2023



Wikipedia can be edited by anyone and thus contains various quality sentences. Therefore, Wikipedia includes some poor-quality edits, which are often marked up by other editors. While editors' reviews enhance the credibility of Wikipedia, it is hard to check all edited text. Assisting in this process is very important, but a large and comprehensive dataset for studying it does not currently exist. Here, we propose WikiSQE, the first large-scale dataset for sentence quality estimation in Wikipedia. Each sentence is extracted from the entire revision history of Wikipedia, and the target quality labels were carefully investigated and selected. WikiSQE has about 3.4 M sentences with 153 quality labels. In the experiment with automatic classification using competitive machine learning models, sentences that had problems with citation, syntax/semantics, or propositions were found to be more difficult to detect. In addition, we conducted automated essay scoring experiments to evaluate the generalizability of the dataset. We show that the models trained on WikiSQE perform better than the vanilla model, indicating its potential usefulness in other domains. WikiSQE is expected to be a valuable resource for other tasks in NLP.
Classifying Wikipedia in a fine-grained hierarchy: what graphs can contribute
Jan 22, 2020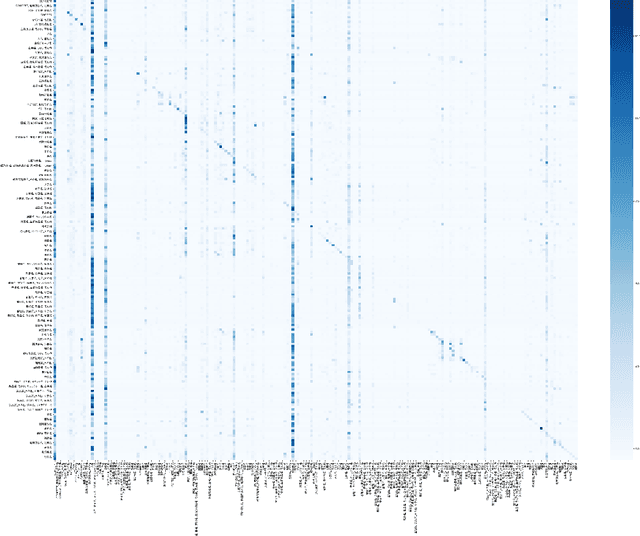
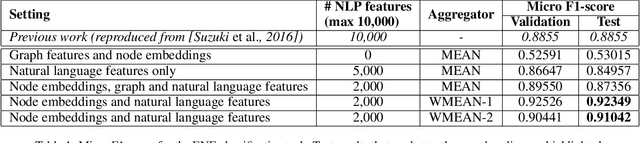
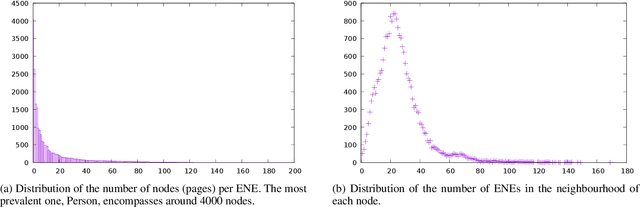
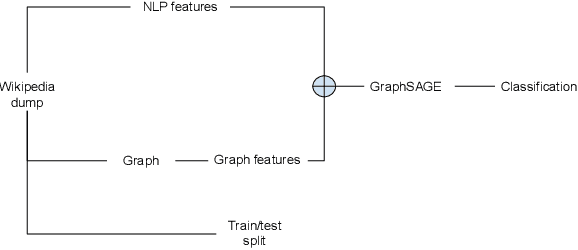
Wikipedia is a huge opportunity for machine learning, being the largest semi-structured base of knowledge available. Because of this, many works examine its contents, and focus on structuring it in order to make it usable in learning tasks, for example by classifying it into an ontology. Beyond its textual contents, Wikipedia also displays a typical graph structure, where pages are linked together through citations. In this paper, we address the task of integrating graph (i.e. structure) information to classify Wikipedia into a fine-grained named entity ontology (NE), the Extended Named Entity hierarchy. To address this task, we first start by assessing the relevance of the graph structure for NE classification. We then explore two directions, one related to feature vectors using graph descriptors commonly used in large-scale network analysis, and one extending flat classification to a weighted model taking into account semantic similarity. We conduct at-scale practical experiments, on a manually labeled subset of 22,000 pages extracted from the Japanese Wikipedia. Our results show that integrating graph information succeeds at reducing sparsity of the input feature space, and yields classification results that are comparable or better than previous works.
Multi-class Multilingual Classification of Wikipedia Articles Using Extended Named Entity Tag Set
Sep 14, 2019

Wikipedia is a great source of general world knowledge which can guide NLP models better understand their motivation to make predictions. We aim to create a large set of structured knowledge, usable for NLP models, from Wikipedia. The first step we take to create such a structured knowledge source is fine-grain classification of Wikipedia articles. In this work, we introduce the Shinara Dataset, a large multi-lingual and multi-labeled set of manually annotated Wikipedia articles in Japanese, English, French, German, and Farsi using Extended Named Entity (ENE) tag set. We evaluate the dataset using the best models provided for ENE label set classification and show that the currently available classification models struggle with large datasets using fine-grained tag sets.
Select and Attend: Towards Controllable Content Selection in Text Generation
Sep 10, 2019
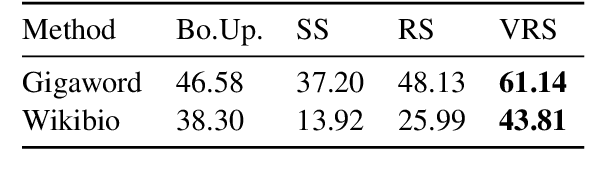
Many text generation tasks naturally contain two steps: content selection and surface realization. Current neural encoder-decoder models conflate both steps into a black-box architecture. As a result, the content to be described in the text cannot be explicitly controlled. This paper tackles this problem by decoupling content selection from the decoder. The decoupled content selection is human interpretable, whose value can be manually manipulated to control the content of generated text. The model can be trained end-to-end without human annotations by maximizing a lower bound of the marginal likelihood. We further propose an effective way to trade-off between performance and controllability with a single adjustable hyperparameter. In both data-to-text and headline generation tasks, our model achieves promising results, paving the way for controllable content selection in text generation.
Can neural networks understand monotonicity reasoning?
Jun 27, 2019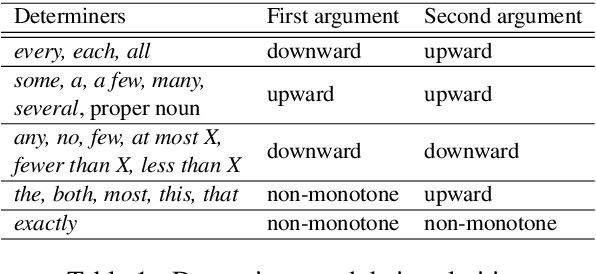


Monotonicity reasoning is one of the important reasoning skills for any intelligent natural language inference (NLI) model in that it requires the ability to capture the interaction between lexical and syntactic structures. Since no test set has been developed for monotonicity reasoning with wide coverage, it is still unclear whether neural models can perform monotonicity reasoning in a proper way. To investigate this issue, we introduce the Monotonicity Entailment Dataset (MED). Performance by state-of-the-art NLI models on the new test set is substantially worse, under 55%, especially on downward reasoning. In addition, analysis using a monotonicity-driven data augmentation method showed that these models might be limited in their generalization ability in upward and downward reasoning.
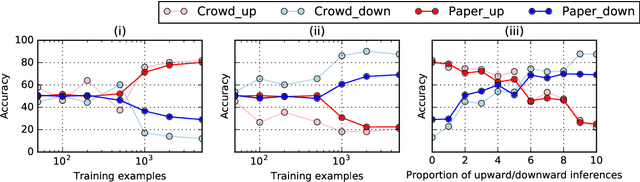
HELP: A Dataset for Identifying Shortcomings of Neural Models in Monotonicity Reasoning
Apr 27, 2019


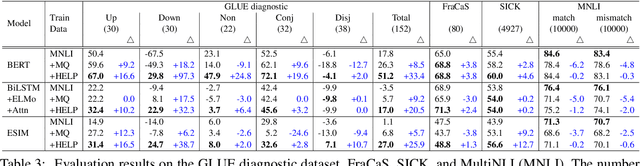
Large crowdsourced datasets are widely used for training and evaluating neural models on natural language inference (NLI). Despite these efforts, neural models have a hard time capturing logical inferences, including those licensed by phrase replacements, so-called monotonicity reasoning. Since no large dataset has been developed for monotonicity reasoning, it is still unclear whether the main obstacle is the size of datasets or the model architectures themselves. To investigate this issue, we introduce a new dataset, called HELP, for handling entailments with lexical and logical phenomena. We add it to training data for the state-of-the-art neural models and evaluate them on test sets for monotonicity phenomena. The results showed that our data augmentation improved the overall accuracy. We also find that the improvement is better on monotonicity inferences with lexical replacements than on downward inferences with disjunction and modification. This suggests that some types of inferences can be improved by our data augmentation while others are immune to it.