 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-class Multilingual Classification of Wikipedia Articles Using Extended Named Entity Tag Set
Paper and Code
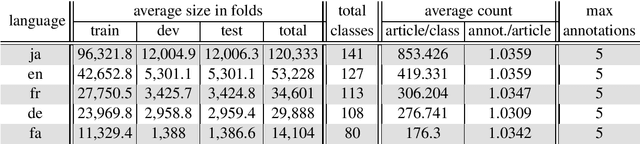

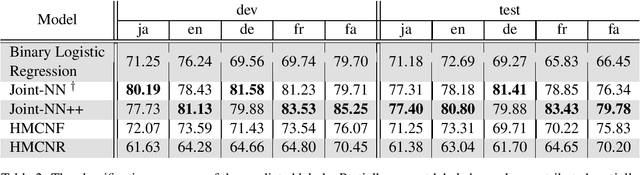
Wikipedia is a great source of general world knowledge which can guide NLP models better understand their motivation to make predictions. We aim to create a large set of structured knowledge, usable for NLP models, from Wikipedia. The first step we take to create such a structured knowledge source is fine-grain classification of Wikipedia articles. In this work, we introduce the Shinara Dataset, a large multi-lingual and multi-labeled set of manually annotated Wikipedia articles in Japanese, English, French, German, and Farsi using Extended Named Entity (ENE) tag set. We evaluate the dataset using the best models provided for ENE label set classification and show that the currently available classification models struggle with large datasets using fine-grained tag sets.