 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Retrieval for Answering Entity-Centric Questions
Aug 05, 2024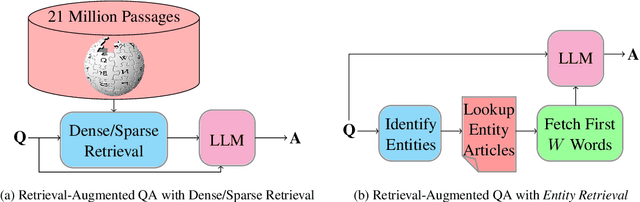



The similarity between the question and indexed documents is a crucial factor in document retrieval for retrieval-augmented question answering. Although this is typically the only method for obtaining the relevant documents, it is not the sole approach when dealing with entity-centric questions. In this study, we propose Entity Retrieval, a novel retrieval method which rather than relying on question-document similarity, depends on the salient entities within the question to identify the retrieval documents. We conduct an in-depth analysis of the performance of both dense and sparse retrieval methods in comparison to Entity Retrieval. Our findings reveal that our method not only leads to more accurate answers to entity-centric questions but also operates more efficiently.
SpEL: Structured Prediction for Entity Linking
Oct 23, 2023Entity linking is a prominent thread of research focused on structured data creation by linking spans of text to an ontology or knowledge source. We revisit the use of structured prediction for entity linking which classifies each individual input token as an entity, and aggregates the token predictions. Our system, called SpEL (Structured prediction for Entity Linking) is a state-of-the-art entity linking system that uses some new ideas to apply structured prediction to the task of entity linking including: two refined fine-tuning steps; a context sensitive prediction aggregation strategy; reduction of the size of the model's output vocabulary, and; we address a common problem in entity-linking systems where there is a training vs. inference tokenization mismatch. Our experiments show that we can outperform the state-of-the-art on the commonly used AIDA benchmark dataset for entity linking to Wikipedia. Our method is also very compute efficient in terms of number of parameters and speed of inference.
Better Neural Machine Translation by Extracting Linguistic Information from BERT
Apr 07, 2021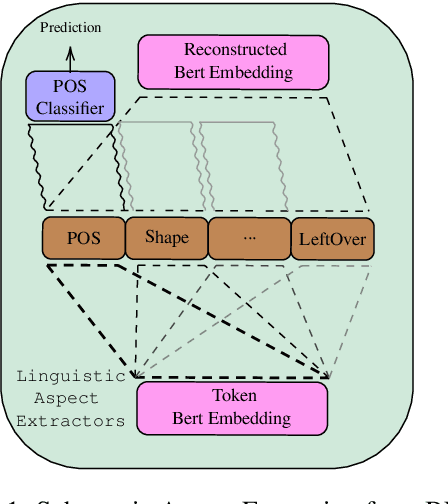



Adding linguistic information (syntax or semantics) to neural machine translation (NMT) has mostly focused on using point estimates from pre-trained models. Directly using the capacity of massive pre-trained contextual word embedding models such as BERT (Devlin et al., 2019) has been marginally useful in NMT because effective fine-tuning is difficult to obtain for NMT without making training brittle and unreliable. We augment NMT by extracting dense fine-tuned vector-based linguistic information from BERT instead of using point estimates. Experimental results show that our method of incorporating linguistic information helps NMT to generalize better in a variety of training contexts and is no more difficult to train than conventional Transformer-based NMT.
Pointer-based Fusion of Bilingual Lexicons into Neural Machine Translation
Sep 17, 2019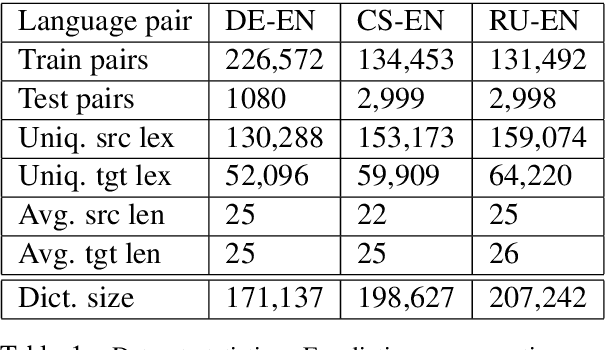

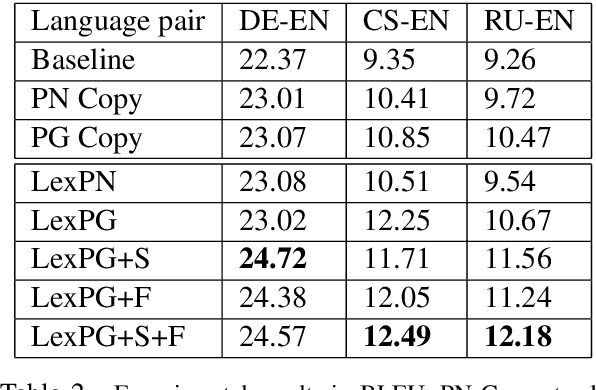
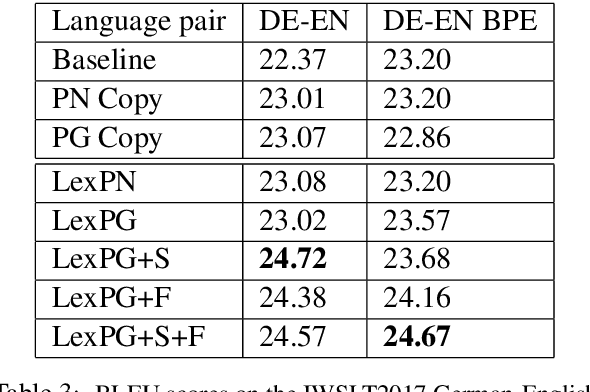
Neural machine translation (NMT) systems require large amounts of high quality in-domain parallel corpora for training. State-of-the-art NMT systems still face challenges related to out-of-vocabulary words and dealing with low-resource language pairs. In this paper, we propose and compare several models for fusion of bilingual lexicons with an end-to-end trained sequence-to-sequence model for machine translation. The result is a fusion model with two information sources for the decoder: a neural conditional language model and a bilingual lexicon. This fusion model learns how to combine both sources of information in order to produce higher quality translation output. Our experiments show that our proposed models work well in relatively low-resource scenarios, and also effectively reduce the parameter size and training cost for NMT without sacrificing performance.
Multi-class Multilingual Classification of Wikipedia Articles Using Extended Named Entity Tag Set
Sep 14, 2019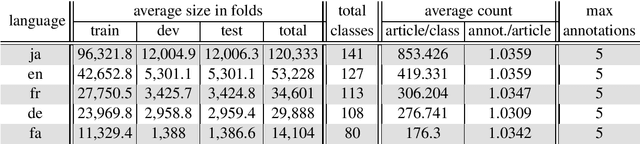

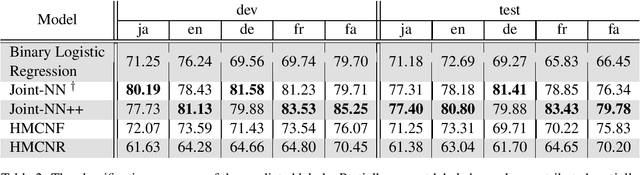
Wikipedia is a great source of general world knowledge which can guide NLP models better understand their motivation to make predictions. We aim to create a large set of structured knowledge, usable for NLP models, from Wikipedia. The first step we take to create such a structured knowledge source is fine-grain classification of Wikipedia articles. In this work, we introduce the Shinara Dataset, a large multi-lingual and multi-labeled set of manually annotated Wikipedia articles in Japanese, English, French, German, and Farsi using Extended Named Entity (ENE) tag set. We evaluate the dataset using the best models provided for ENE label set classification and show that the currently available classification models struggle with large datasets using fine-grained tag sets.
Top-down Tree Structured Decoding with Syntactic Connections for Neural Machine Translation and Parsing
Sep 06, 2018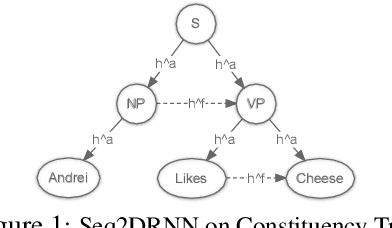

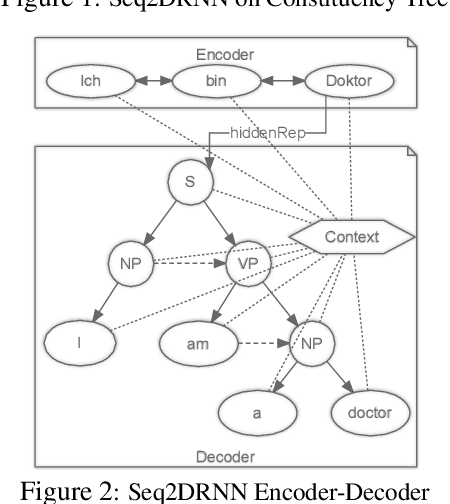
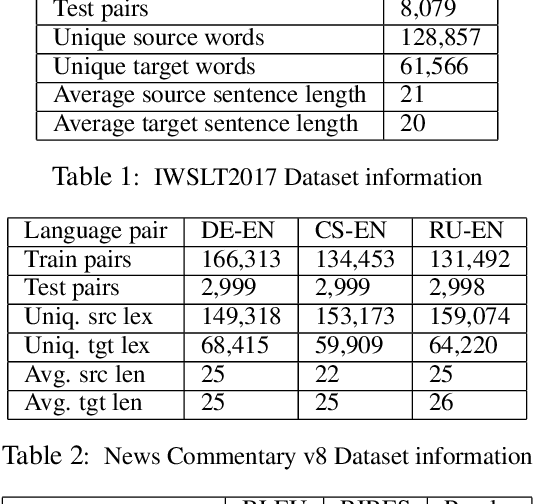
The addition of syntax-aware decoding in Neural Machine Translation (NMT) systems requires an effective tree-structured neural network, a syntax-aware attention model and a language generation model that is sensitive to sentence structure. We exploit a top-down tree-structured model called DRNN (Doubly-Recurrent Neural Networks) first proposed by Alvarez-Melis and Jaakola (2017) to create an NMT model called Seq2DRNN that combines a sequential encoder with tree-structured decoding augmented with a syntax-aware attention model. Unlike previous approaches to syntax-based NMT which use dependency parsing models our method uses constituency parsing which we argue provides useful information for translation. In addition, we use the syntactic structure of the sentence to add new connections to the tree-structured decoder neural network (Seq2DRNN+SynC). We compare our NMT model with sequential and state of the art syntax-based NMT models and show that our model produces more fluent translations with better reordering. Since our model is capable of doing translation and constituency parsing at the same time we also compare our parsing accuracy against other neural parsing models.