 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Neural Machine Translation by Extracting Linguistic Information from BERT
Paper and Code
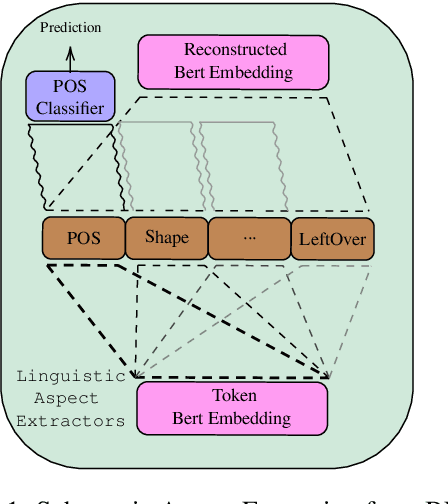



Adding linguistic information (syntax or semantics) to neural machine translation (NMT) has mostly focused on using point estimates from pre-trained models. Directly using the capacity of massive pre-trained contextual word embedding models such as BERT (Devlin et al., 2019) has been marginally useful in NMT because effective fine-tuning is difficult to obtain for NMT without making training brittle and unreliable. We augment NMT by extracting dense fine-tuned vector-based linguistic information from BERT instead of using point estimates. Experimental results show that our method of incorporating linguistic information helps NMT to generalize better in a variety of training contexts and is no more difficult to train than conventional Transformer-based NMT.