 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Retrieval for Answering Entity-Centric Questions
Aug 05, 2024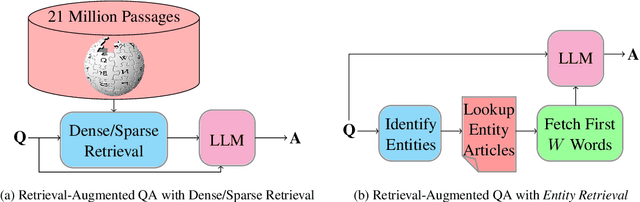



The similarity between the question and indexed documents is a crucial factor in document retrieval for retrieval-augmented question answering. Although this is typically the only method for obtaining the relevant documents, it is not the sole approach when dealing with entity-centric questions. In this study, we propose Entity Retrieval, a novel retrieval method which rather than relying on question-document similarity, depends on the salient entities within the question to identify the retrieval documents. We conduct an in-depth analysis of the performance of both dense and sparse retrieval methods in comparison to Entity Retrieval. Our findings reveal that our method not only leads to more accurate answers to entity-centric questions but also operates more efficiently.
Unified Examination of Entity Linking in Absence of Candidate Sets
Apr 17, 2024Despite remarkable strides made in the development of entity linking systems in recent years, a comprehensive comparative analysis of these systems using a unified framework is notably absent. This paper addresses this oversight by introducing a new black-box benchmark and conducting a comprehensive evaluation of all state-of-the-art entity linking methods. We use an ablation study to investigate the impact of candidate sets on the performance of entity linking. Our findings uncover exactly how much such entity linking systems depend on candidate sets, and how much this limits the general applicability of each system. We present an alternative approach to candidate sets, demonstrating that leveraging the entire in-domain candidate set can serve as a viable substitute for certain models. We show the trade-off between less restrictive candidate sets, increased inference time and memory footprint for some models.
SpEL: Structured Prediction for Entity Linking
Oct 23, 2023Entity linking is a prominent thread of research focused on structured data creation by linking spans of text to an ontology or knowledge source. We revisit the use of structured prediction for entity linking which classifies each individual input token as an entity, and aggregates the token predictions. Our system, called SpEL (Structured prediction for Entity Linking) is a state-of-the-art entity linking system that uses some new ideas to apply structured prediction to the task of entity linking including: two refined fine-tuning steps; a context sensitive prediction aggregation strategy; reduction of the size of the model's output vocabulary, and; we address a common problem in entity-linking systems where there is a training vs. inference tokenization mismatch. Our experiments show that we can outperform the state-of-the-art on the commonly used AIDA benchmark dataset for entity linking to Wikipedia. Our method is also very compute efficient in terms of number of parameters and speed of inference.
CipherDAug: Ciphertext based Data Augmentation for Neural Machine Translation
Apr 01, 2022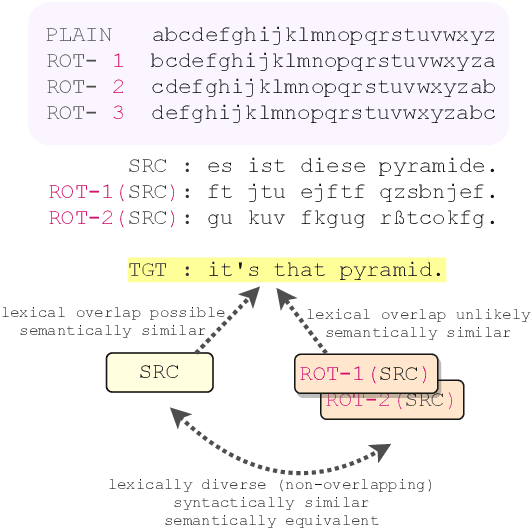
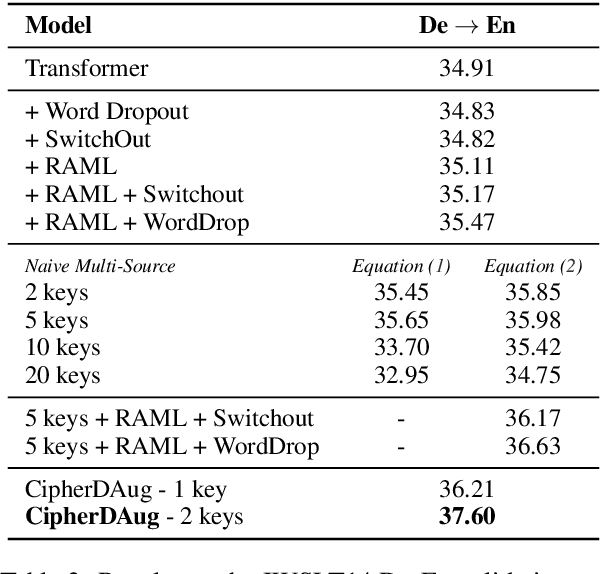
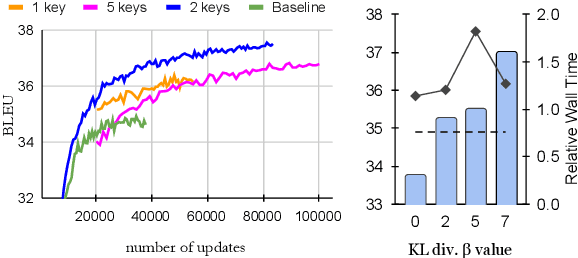
We propose a novel data-augmentation technique for neural machine translation based on ROT-$k$ ciphertexts. ROT-$k$ is a simple letter substitution cipher that replaces a letter in the plaintext with the $k$th letter after it in the alphabet. We first generate multiple ROT-$k$ ciphertexts using different values of $k$ for the plaintext which is the source side of the parallel data. We then leverage this enciphered training data along with the original parallel data via multi-source training to improve neural machine translation. Our method, CipherDAug, uses a co-regularization-inspired training procedure, requires no external data sources other than the original training data, and uses a standard Transformer to outperform strong data augmentation techniques on several datasets by a significant margin. This technique combines easily with existing approaches to data augmentation, and yields particularly strong results in low-resource settings.
Better Neural Machine Translation by Extracting Linguistic Information from BERT
Apr 07, 2021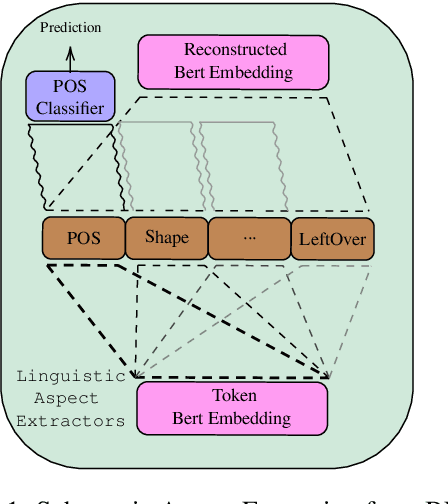



Adding linguistic information (syntax or semantics) to neural machine translation (NMT) has mostly focused on using point estimates from pre-trained models. Directly using the capacity of massive pre-trained contextual word embedding models such as BERT (Devlin et al., 2019) has been marginally useful in NMT because effective fine-tuning is difficult to obtain for NMT without making training brittle and unreliable. We augment NMT by extracting dense fine-tuned vector-based linguistic information from BERT instead of using point estimates. Experimental results show that our method of incorporating linguistic information helps NMT to generalize better in a variety of training contexts and is no more difficult to train than conventional Transformer-based NMT.
Interrogating the Explanatory Power of Attention in Neural Machine Translation
Sep 30, 2019

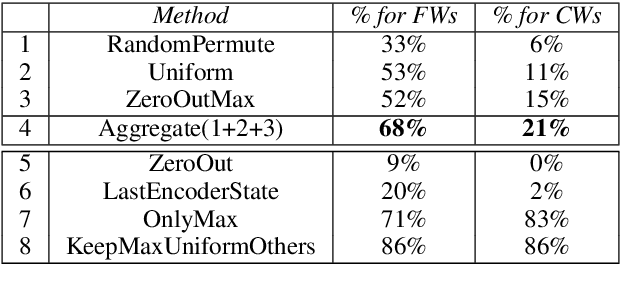
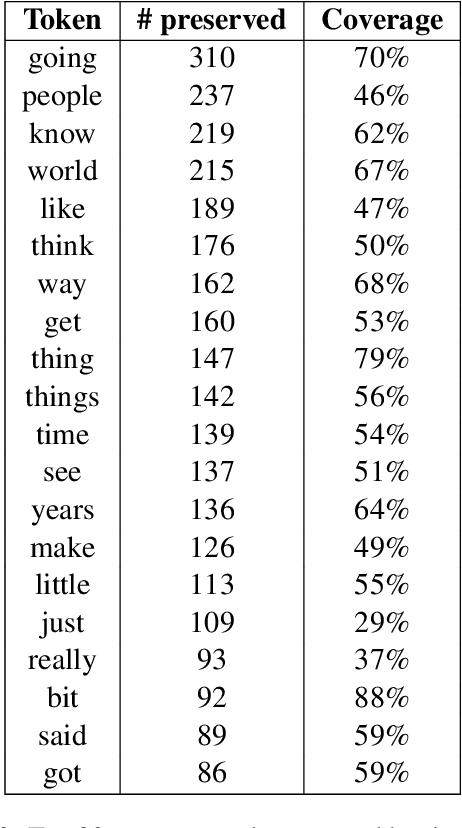
Attention models have become a crucial component in neural machine translation (NMT). They are often implicitly or explicitly used to justify the model's decision in generating a specific token but it has not yet been rigorously established to what extent attention is a reliable source of information in NMT. To evaluate the explanatory power of attention for NMT, we examine the possibility of yielding the same prediction but with counterfactual attention models that modify crucial aspects of the trained attention model. Using these counterfactual attention mechanisms we assess the extent to which they still preserve the generation of function and content words in the translation process. Compared to a state of the art attention model, our counterfactual attention models produce 68% of function words and 21% of content words in our German-English dataset. Our experiments demonstrate that attention models by themselves cannot reliably explain the decisions made by a NMT model.
Pointer-based Fusion of Bilingual Lexicons into Neural Machine Translation
Sep 17, 2019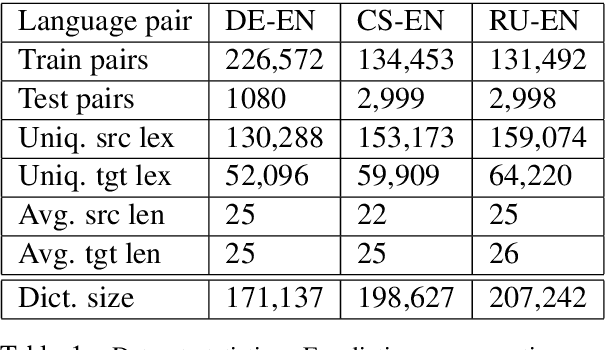

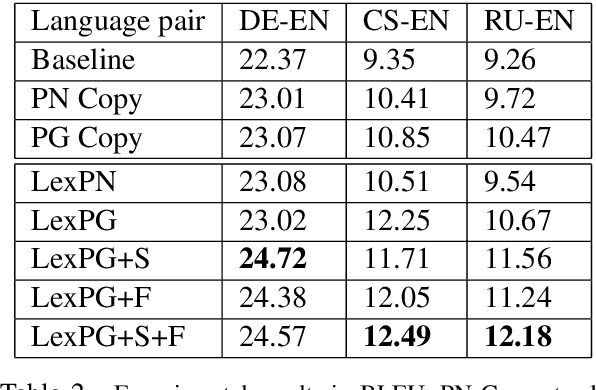
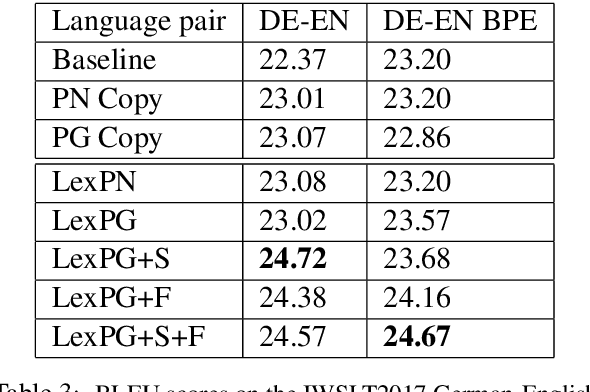
Neural machine translation (NMT) systems require large amounts of high quality in-domain parallel corpora for training. State-of-the-art NMT systems still face challenges related to out-of-vocabulary words and dealing with low-resource language pairs. In this paper, we propose and compare several models for fusion of bilingual lexicons with an end-to-end trained sequence-to-sequence model for machine translation. The result is a fusion model with two information sources for the decoder: a neural conditional language model and a bilingual lexicon. This fusion model learns how to combine both sources of information in order to produce higher quality translation output. Our experiments show that our proposed models work well in relatively low-resource scenarios, and also effectively reduce the parameter size and training cost for NMT without sacrificing performance.
Top-down Tree Structured Decoding with Syntactic Connections for Neural Machine Translation and Parsing
Sep 06, 2018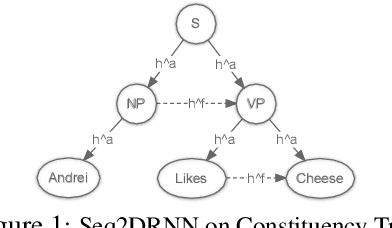

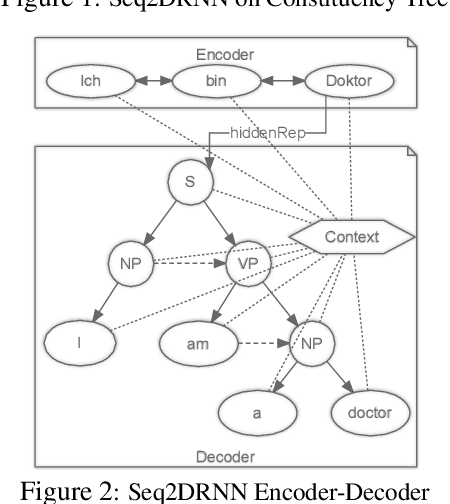
The addition of syntax-aware decoding in Neural Machine Translation (NMT) systems requires an effective tree-structured neural network, a syntax-aware attention model and a language generation model that is sensitive to sentence structure. We exploit a top-down tree-structured model called DRNN (Doubly-Recurrent Neural Networks) first proposed by Alvarez-Melis and Jaakola (2017) to create an NMT model called Seq2DRNN that combines a sequential encoder with tree-structured decoding augmented with a syntax-aware attention model. Unlike previous approaches to syntax-based NMT which use dependency parsing models our method uses constituency parsing which we argue provides useful information for translation. In addition, we use the syntactic structure of the sentence to add new connections to the tree-structured decoder neural network (Seq2DRNN+SynC). We compare our NMT model with sequential and state of the art syntax-based NMT models and show that our model produces more fluent translations with better reordering. Since our model is capable of doing translation and constituency parsing at the same time we also compare our parsing accuracy against other neural parsing models.
Non-Uniform Stochastic Average Gradient Method for Training Conditional Random Fields
Apr 16, 2015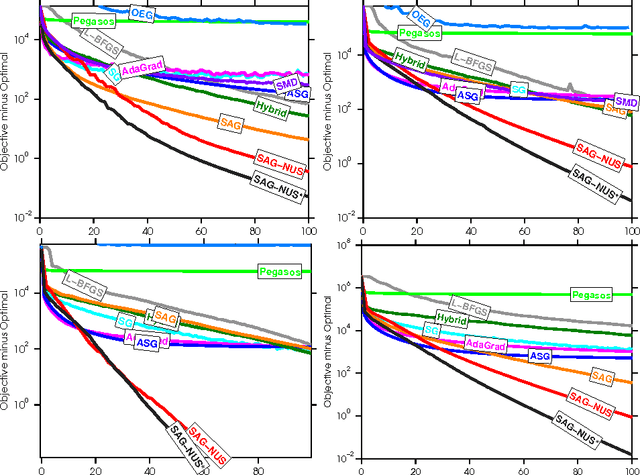
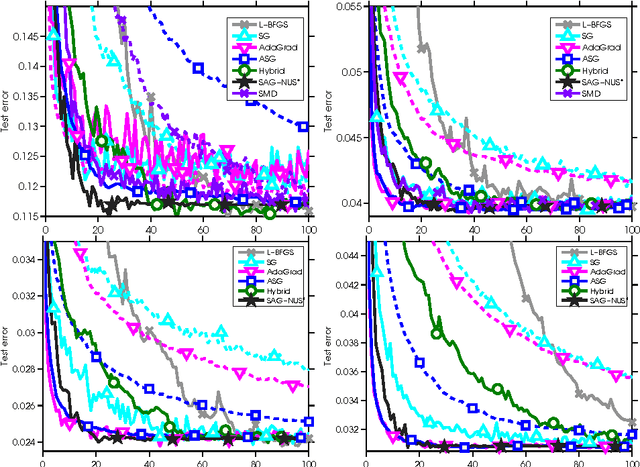
We apply stochastic average gradient (SAG) algorithms for training conditional random fields (CRFs). We describe a practical implementation that uses structure in the CRF gradient to reduce the memory requirement of this linearly-convergent stochastic gradient method, propose a non-uniform sampling scheme that substantially improves practical performance, and analyze the rate of convergence of the SAGA variant under non-uniform sampling. Our experimental results reveal that our method often significantly outperforms existing methods in terms of the training objective, and performs as well or better than optimally-tuned stochastic gradient methods in terms of test error.
Analysis of Semi-Supervised Learning with the Yarowsky Algorithm
Jun 20, 2012
The Yarowsky algorithm is a rule-based semi-supervised learning algorithm that has been successfully applied to some problems in computational linguistics. The algorithm was not mathematically well understood until (Abney 2004) which analyzed some specific variants of the algorithm, and also proposed some new algorithms for bootstrapping. In this paper, we extend Abney's work and show that some of his proposed algorithms actually optimize (an upper-bound on) an objective function based on a new definition of cross-entropy which is based on a particular instantiation of the Bregman distance between probability distributions. Moreover, we suggest some new algorithms for rule-based semi-supervised learning and show connections with harmonic functions and minimum multi-way cuts in graph-based semi-supervised learning.