 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCipherDAug: Ciphertext based Data Augmentation for Neural Machine Translation
Apr 01, 2022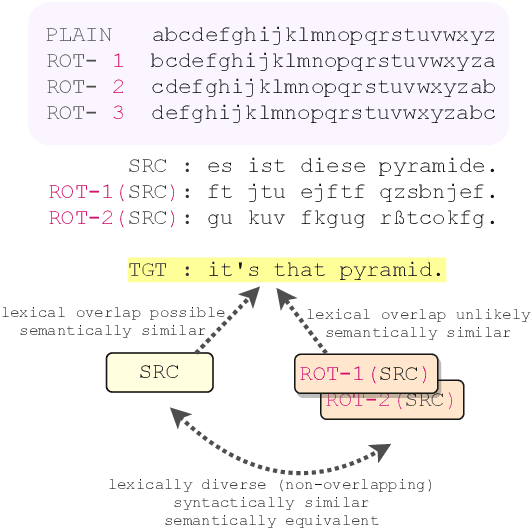
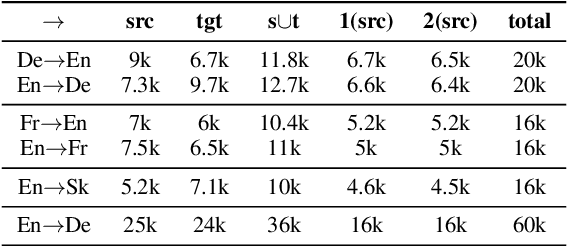
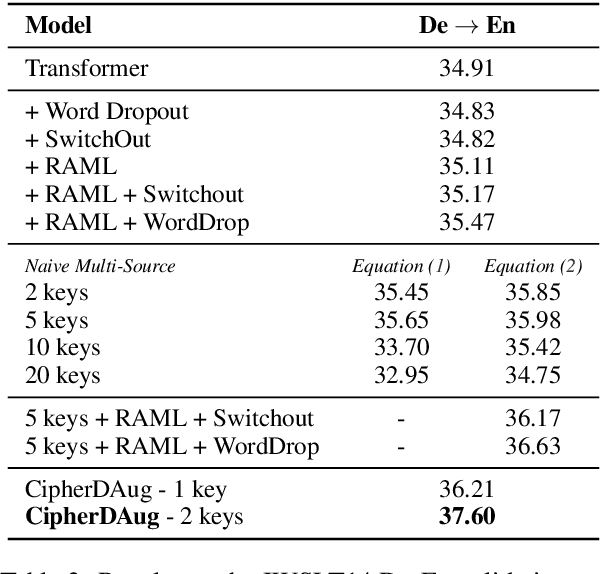
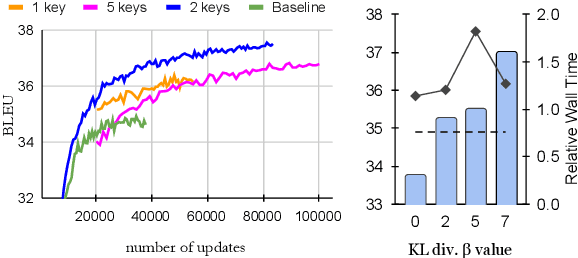
We propose a novel data-augmentation technique for neural machine translation based on ROT-$k$ ciphertexts. ROT-$k$ is a simple letter substitution cipher that replaces a letter in the plaintext with the $k$th letter after it in the alphabet. We first generate multiple ROT-$k$ ciphertexts using different values of $k$ for the plaintext which is the source side of the parallel data. We then leverage this enciphered training data along with the original parallel data via multi-source training to improve neural machine translation. Our method, CipherDAug, uses a co-regularization-inspired training procedure, requires no external data sources other than the original training data, and uses a standard Transformer to outperform strong data augmentation techniques on several datasets by a significant margin. This technique combines easily with existing approaches to data augmentation, and yields particularly strong results in low-resource settings.
Interrogating the Explanatory Power of Attention in Neural Machine Translation
Sep 30, 2019

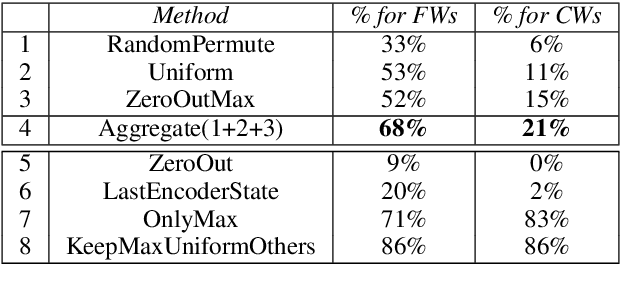
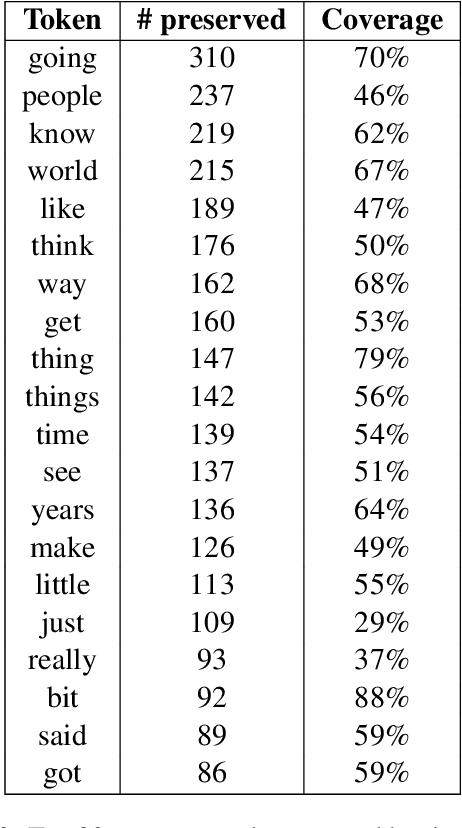
Attention models have become a crucial component in neural machine translation (NMT). They are often implicitly or explicitly used to justify the model's decision in generating a specific token but it has not yet been rigorously established to what extent attention is a reliable source of information in NMT. To evaluate the explanatory power of attention for NMT, we examine the possibility of yielding the same prediction but with counterfactual attention models that modify crucial aspects of the trained attention model. Using these counterfactual attention mechanisms we assess the extent to which they still preserve the generation of function and content words in the translation process. Compared to a state of the art attention model, our counterfactual attention models produce 68% of function words and 21% of content words in our German-English dataset. Our experiments demonstrate that attention models by themselves cannot reliably explain the decisions made by a NMT model.