 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Monaural Speech Enhancement using Spectrum Attention Fusion
Aug 04, 2023Speech enhancement is a demanding task in automated speech processing pipelines, focusing on separating clean speech from noisy channels. Transformer based models have recently bested RNN and CNN models in speech enhancement, however at the same time they are much more computationally expensive and require much more high quality training data, which is always hard to come by. In this paper, we present an improvement for speech enhancement models that maintains the expressiveness of self-attention while significantly reducing model complexity, which we have termed Spectrum Attention Fusion. We carefully construct a convolutional module to replace several self-attention layers in a speech Transformer, allowing the model to more efficiently fuse spectral features. Our proposed model is able to achieve comparable or better results against SOTA models but with significantly smaller parameters (0.58M) on the Voice Bank + DEMAND dataset.
Pointer-based Fusion of Bilingual Lexicons into Neural Machine Translation
Sep 17, 2019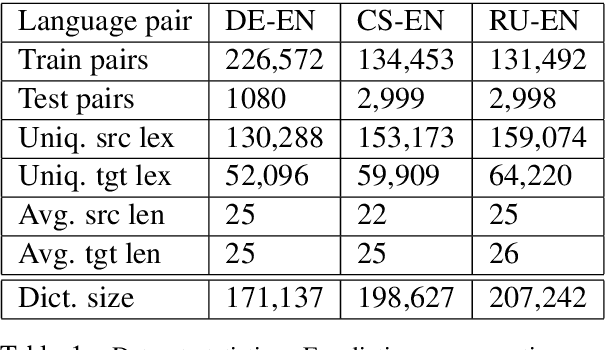

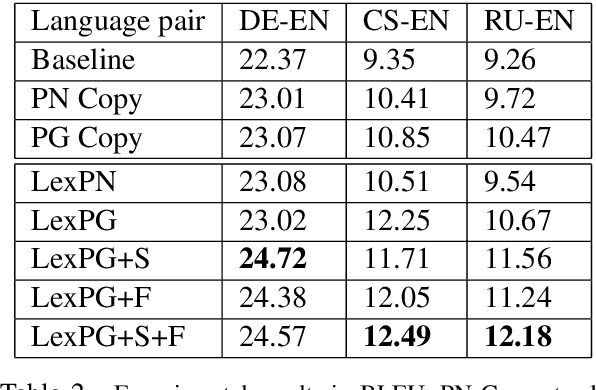
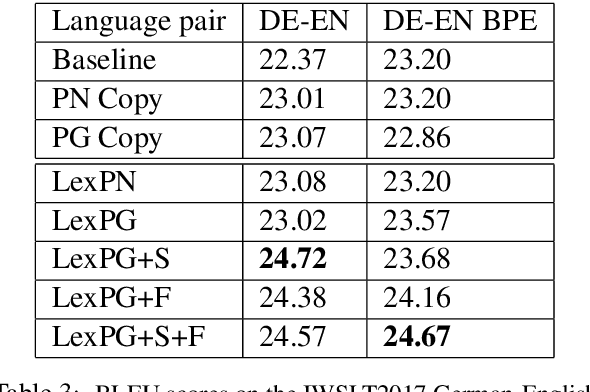
Neural machine translation (NMT) systems require large amounts of high quality in-domain parallel corpora for training. State-of-the-art NMT systems still face challenges related to out-of-vocabulary words and dealing with low-resource language pairs. In this paper, we propose and compare several models for fusion of bilingual lexicons with an end-to-end trained sequence-to-sequence model for machine translation. The result is a fusion model with two information sources for the decoder: a neural conditional language model and a bilingual lexicon. This fusion model learns how to combine both sources of information in order to produce higher quality translation output. Our experiments show that our proposed models work well in relatively low-resource scenarios, and also effectively reduce the parameter size and training cost for NMT without sacrificing performance.
Top-down Tree Structured Decoding with Syntactic Connections for Neural Machine Translation and Parsing
Sep 06, 2018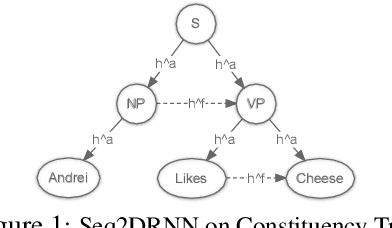

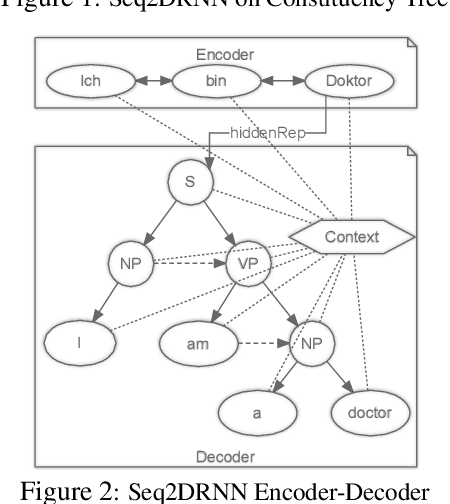
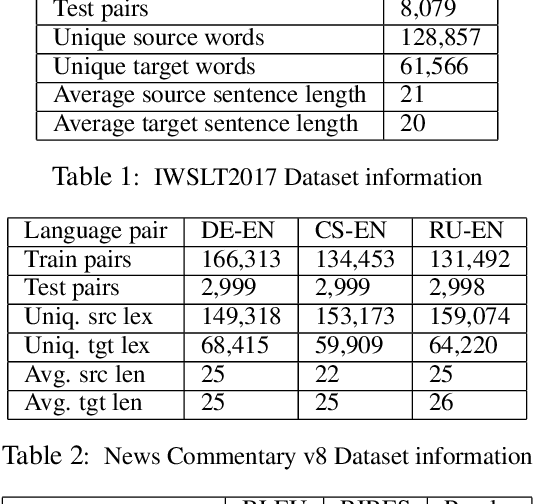
The addition of syntax-aware decoding in Neural Machine Translation (NMT) systems requires an effective tree-structured neural network, a syntax-aware attention model and a language generation model that is sensitive to sentence structure. We exploit a top-down tree-structured model called DRNN (Doubly-Recurrent Neural Networks) first proposed by Alvarez-Melis and Jaakola (2017) to create an NMT model called Seq2DRNN that combines a sequential encoder with tree-structured decoding augmented with a syntax-aware attention model. Unlike previous approaches to syntax-based NMT which use dependency parsing models our method uses constituency parsing which we argue provides useful information for translation. In addition, we use the syntactic structure of the sentence to add new connections to the tree-structured decoder neural network (Seq2DRNN+SynC). We compare our NMT model with sequential and state of the art syntax-based NMT models and show that our model produces more fluent translations with better reordering. Since our model is capable of doing translation and constituency parsing at the same time we also compare our parsing accuracy against other neural parsing models.