 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointer-based Fusion of Bilingual Lexicons into Neural Machine Translation
Paper and Code
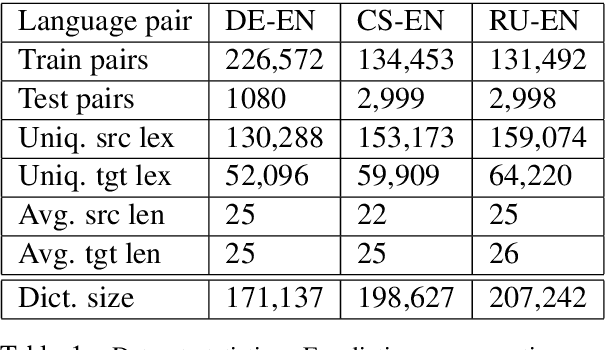

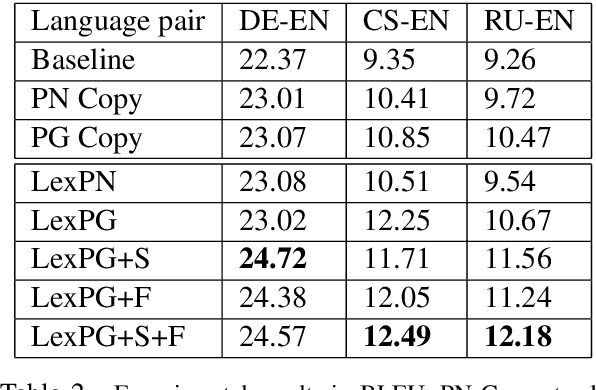
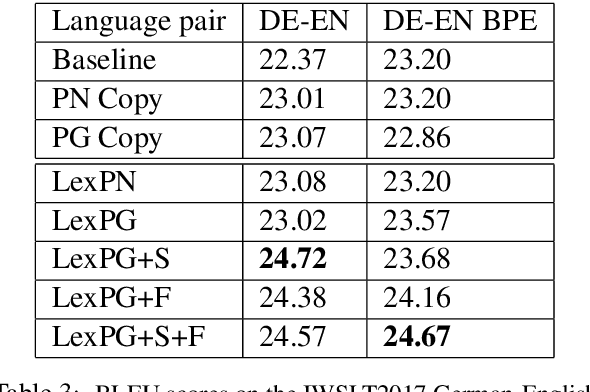
Neural machine translation (NMT) systems require large amounts of high quality in-domain parallel corpora for training. State-of-the-art NMT systems still face challenges related to out-of-vocabulary words and dealing with low-resource language pairs. In this paper, we propose and compare several models for fusion of bilingual lexicons with an end-to-end trained sequence-to-sequence model for machine translation. The result is a fusion model with two information sources for the decoder: a neural conditional language model and a bilingual lexicon. This fusion model learns how to combine both sources of information in order to produce higher quality translation output. Our experiments show that our proposed models work well in relatively low-resource scenarios, and also effectively reduce the parameter size and training cost for NMT without sacrificing performance.