 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Large Language Model Behavior with Human Citation Preferences
Feb 05, 2026Most services built on powerful large-scale language models (LLMs) add citations to their output to enhance credibility. Recent research has paid increasing attention to the question of what reference documents to link to outputs. However, how LLMs recognize cite-worthiness and how this process should be controlled remains underexplored. In this study, we focus on what kinds of content LLMs currently tend to cite and how well that behavior aligns with human preferences. We construct a dataset to characterize the relationship between human citation preferences and LLM behavior. Web-derived texts are categorized into eight citation-motivation types, and pairwise citation preferences are exhaustively evaluated across all type combinations to capture fine-grained contrasts. Our results show that humans most frequently seek citations for medical text, and stronger models display a similar tendency. We also find that current models are as much as $27\%$ more likely than humans to add citations to text that is explicitly marked as needing citations on sources such as Wikipedia, and this overemphasis reduces alignment accuracy. Conversely, models systematically underselect numeric sentences (by $-22.6\%$ relative to humans) and sentences containing personal names (by $-20.1\%$), categories for which humans typically demand citations. Furthermore, experiments with Direct Preference Optimization demonstrate that model behavior can be calibrated to better match human citation preferences. We expect this study to provide a foundation for more fine-grained investigations into LLM citation preferences.
WikiSQE: A Large-Scale Dataset for Sentence Quality Estimation in Wikipedia
May 10, 2023



Wikipedia can be edited by anyone and thus contains various quality sentences. Therefore, Wikipedia includes some poor-quality edits, which are often marked up by other editors. While editors' reviews enhance the credibility of Wikipedia, it is hard to check all edited text. Assisting in this process is very important, but a large and comprehensive dataset for studying it does not currently exist. Here, we propose WikiSQE, the first large-scale dataset for sentence quality estimation in Wikipedia. Each sentence is extracted from the entire revision history of Wikipedia, and the target quality labels were carefully investigated and selected. WikiSQE has about 3.4 M sentences with 153 quality labels. In the experiment with automatic classification using competitive machine learning models, sentences that had problems with citation, syntax/semantics, or propositions were found to be more difficult to detect. In addition, we conducted automated essay scoring experiments to evaluate the generalizability of the dataset. We show that the models trained on WikiSQE perform better than the vanilla model, indicating its potential usefulness in other domains. WikiSQE is expected to be a valuable resource for other tasks in NLP.
Is In-hospital Meta-information Useful for Abstractive Discharge Summary Generation?
Mar 10, 2023



During the patient's hospitalization, the physician must record daily observations of the patient and summarize them into a brief document called "discharge summary" when the patient is discharged. Automated generation of discharge summary can greatly relieve the physicians' burden, and has been addressed recently in the research community. Most previous studies of discharge summary generation using the sequence-to-sequence architecture focus on only inpatient notes for input. However, electric health records (EHR) also have rich structured metadata (e.g., hospital, physician, disease, length of stay, etc.) that might be useful. This paper investigates the effectiveness of medical meta-information for summarization tasks. We obtain four types of meta-information from the EHR systems and encode each meta-information into a sequence-to-sequence model. Using Japanese EHRs, meta-information encoded models increased ROUGE-1 by up to 4.45 points and BERTScore by 3.77 points over the vanilla Longformer. Also, we found that the encoded meta-information improves the precisions of its related terms in the outputs. Our results showed the benefit of the use of medical meta-information.
Exploring Optimal Granularity for Extractive Summarization of Unstructured Health Records: Analysis of the Largest Multi-Institutional Archive of Health Records in Japan
Sep 20, 2022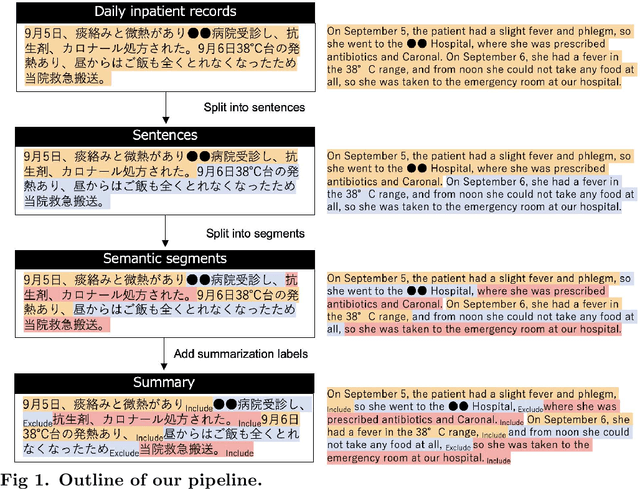
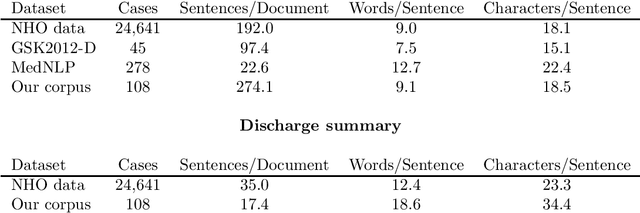
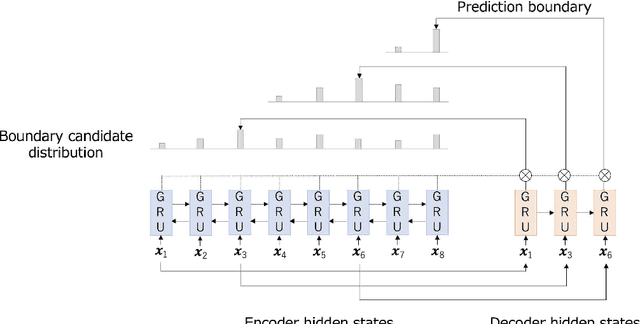
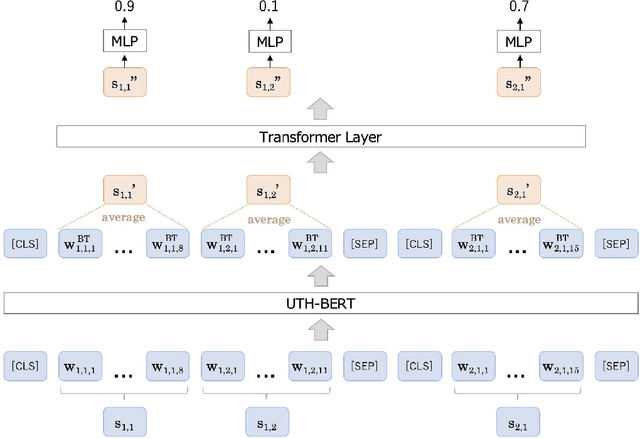
Automated summarization of clinical texts can reduce the burden of medical professionals. "Discharge summaries" are one promising application of the summarization, because they can be generated from daily inpatient records. Our preliminary experiment suggests that 20-31% of the descriptions in discharge summaries overlap with the content of the inpatient records. However, it remains unclear how the summaries should be generated from the unstructured source. To decompose the physician's summarization process, this study aimed to identify the optimal granularity in summarization. We first defined three types of summarization units with different granularities to compare the performance of the discharge summary generation: whole sentences, clinical segments, and clauses. We defined clinical segments in this study, aiming to express the smallest medically meaningful concepts. To obtain the clinical segments, it was necessary to automatically split the texts in the first stage of the pipeline. Accordingly, we compared rule-based methods and a machine learning method, and the latter outperformed the formers with an F1 score of 0.846 in the splitting task. Next, we experimentally measured the accuracy of extractive summarization using the three types of units, based on the ROUGE-1 metric, on a multi-institutional national archive of health records in Japan. The measured accuracies of extractive summarization using whole sentences, clinical segments, and clauses were 31.91, 36.15, and 25.18, respectively. We found that the clinical segments yielded higher accuracy than sentences and clauses. This result indicates that summarization of inpatient records demands finer granularity than sentence-oriented processing. Although we used only Japanese health records, it can be interpreted as follows: physicians extract "concepts of medical significance" from patient records and recombine them ...